Kimi K2.6 Deep Dive: 88% Cheaper Claude Opus 4.7 Alternative?
Kimi K2.6 is an open-weight MoE model with SWE-Bench Pro 58.6, HLE 54.0, 300-agent swarms, 256K context, and API pricing about 88% below Claude Opus 4.7.

Quick take
Start with this judgment
15 min readBottom line
Kimi K2.6 is an open-weight MoE model with SWE-Bench Pro 58.6, HLE 54.0, 300-agent swarms, 256K context, and API pricing about 88% below Claude Opus 4.7.
- Best for
- Readers comparing cost, capability, and real limits before choosing a tool
- What to check
- Kimi K2.6 · Moonshot AI · open-weight LLM
- Watch out
- Pricing and features can change, so confirm with the official source too.
3 key points
- Kimi K2.6, released by Moonshot AI on April 20, 2026, is a 1T-parameter MoE model with about 32B active parameters. It ranks first among open-weight models and fourth overall in Artificial Analysis’ Intelligence Index.
- API pricing is $0.60 input and $2.50 output per 1M tokens, roughly 88% cheaper than Claude Opus 4.7 in common coding-agent workloads.
- Vibe coders can test it through Kimi Code CLI or OpenAI-compatible endpoints. Security-sensitive teams should route sensitive data to local GGUF deployments instead of the default mainland China API region.
목차
- What changed with Kimi K2.6?
- Why does a 1T model activate only 32B parameters?
- Are the benchmark numbers actually credible?
- What does 88% cheaper mean in real usage?
- What is the 300-subagent swarm feature?
- Can Kimi Code CLI replace Claude Code?
- Is a Chinese model safe for sensitive data?
- How do you use the 256K context window?
- What is the community saying?
- Troubleshooting Q&A
- Conclusion: who should try Kimi K2.6 now?
What changed with Kimi K2.6?
Kimi K2.6 is an open-weight MoE (Mixture of Experts) model released by Beijing-based Moonshot AI on April 20, 2026 (source: MarkTechPost). K2.5 made developers take Chinese coding models seriously. K2.6 pushes the claim further: an open-weight model can sit close to GPT-5.4 and Claude Opus 4.7 in public benchmarks. Artificial Analysis ranks it first among open-weight models and fourth overall, just three points behind the 57-point frontier cluster from Anthropic, Google, and OpenAI (source: Artificial Analysis).
Release, license, and access paths
Weights and the model card are available at moonshotai/Kimi-K2.6 on Hugging Face. Soon after release, the page had hundreds of likes, tens of thousands of monthly downloads, active discussions, finetunes, and quantizations (source: Hugging Face). The license is Modified MIT: commercial use is allowed, but very large services may need to display Kimi or Moonshot AI attribution.
There are four access paths: Kimi.com chat, iOS/Android Kimi apps, the terminal-based Kimi Code CLI, and the API at api.moonshot.cn. The API is the important one for developers because it exposes both OpenAI-compatible and Anthropic-compatible endpoints. In many tools, changing base_url and api_key is enough for a first test.
K2.5 vs K2.6 in one table
K2.5 was “surprisingly good for open source.” K2.6 is “close enough to frontier models that cost becomes the main question.” The subagent limit grows from 100 to 300, autonomous step count grows from about 1,500 to more than 4,000, and native INT4 plus MoonViT 400M vision support arrive.
| Item | Kimi K2.6 | Kimi K2.5 |
|---|---|---|
| Release date | 2026-04-20 | 2025-11-06 |
| Total parameters | 1T | 1T |
| Active parameters | 32B | 32B |
| Context | 256K | 256K |
| Subagents | 300 | 100 |
| Autonomous steps | 4,000+ | 1,500+ |
| Vision | MoonViT 400M | Basic multimodal |
| Quantization | Native INT4 | Community quantization |
| License | Modified MIT | Modified MIT |
Why does a 1T model activate only 32B parameters?
K2.6 uses an MoE architecture. The model owns roughly 1T total parameters, but only a subset is active for each token. That is how it can carry massive capacity without paying the full compute cost on every forward pass.
384 experts, top-8 routing, one shared expert
Each MoE layer contains 384 experts. For each token, the router selects 8 experts, and one shared expert is always active. In practice, about 9 experts participate per token. The model has 61 layers: one dense layer and 60 MoE layers. Attention uses 64 heads and MLA (Multi-head Latent Attention) to reduce KV-cache memory (source: Hugging Face Model Card).
256K context, not 1M
Some summaries misreported K2.6 as a 1M-context model. The Hugging Face model card lists max_position_embeddings as 262,144, which means 256K tokens (source: Hugging Face). That is still enough for large multi-file coding tasks and agent-state orchestration, but it is not the same category as 1M-context frontier models.
| Architecture item | Kimi K2.6 |
|---|---|
| Total parameters | 1T |
| Active parameters | 32B |
| Experts per MoE layer | 384 |
| Experts selected per token | 8 + 1 shared |
| Layers | 61 total, 60 MoE |
| Attention | 64 heads, MLA |
| Context window | 262,144 tokens |
| Vision encoder | MoonViT 400M |
Are the benchmark numbers actually credible?
The numbers are strong enough that you should look at them, but not so clean that you should skip your own evaluation.
AIME 2026 96.4 and GPQA-Diamond 90.5
K2.6 scores 96.4% on AIME 2026, 92.7% on HMMT February 2026, 86.0% on IMO-AnswerBench, and 90.5% on GPQA-Diamond (source: official Kimi blog). On pure reasoning, it is in the same conversation as frontier models.
Coding: SWE-Bench Pro 58.6
K2.6 reaches 80.2% on SWE-Bench Verified and 58.6% on SWE-Bench Pro. Opus 4.7 is still ahead on Pro at 64.3%, but K2.6 slightly beats GPT-5.4’s reported 57.7% (source: officechai). For a cheaper open-weight model, that is the headline.
| Benchmark | Kimi K2.6 | Claude Opus 4.7 | GPT-5.4 | Gemma 4 |
|---|---|---|---|---|
| AIME 2026 | 96.4 | 95.1 | 94.8 | 89.2 |
| GPQA-Diamond | 90.5 | 88.1 | 87.2 | 82.4 |
| SWE-Bench Verified | 80.2 | 87.6 | n/a | 74.0 |
| SWE-Bench Pro | 58.6 | 64.3 | 57.7 | n/a |
| LiveCodeBench | 89.6 | 91.0 | 88.4 | 78.2 |
| HLE | 54.0 | 56.1 | 52.8 | n/a |
| BrowseComp | 83.2 | 79.3 | 89.3 | n/a |
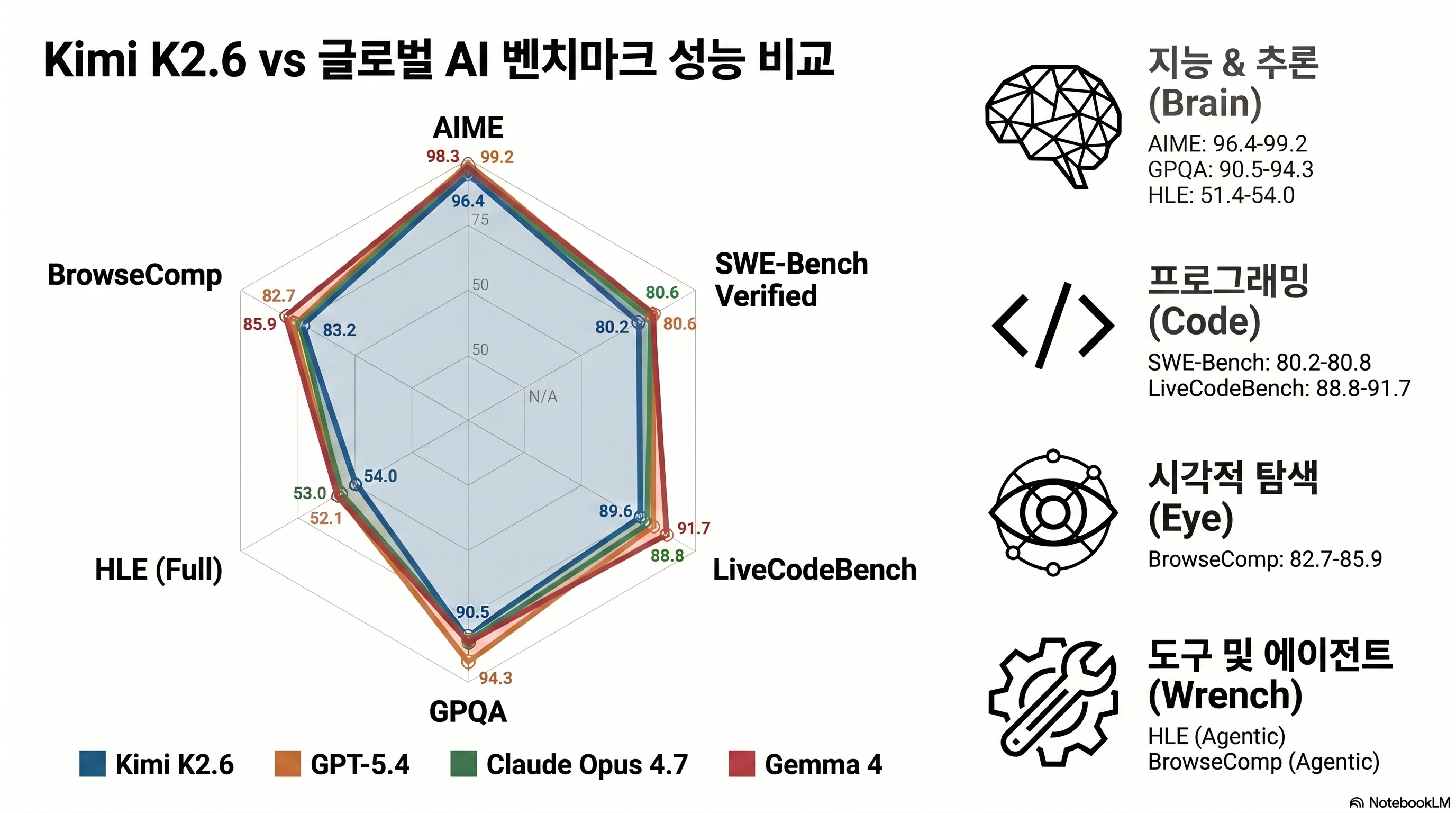
Many K2.6 benchmark numbers come from Moonshot’s own release materials. Third-party checks such as SWE-Bench Verified and Artificial Analysis broadly agree with the ranking, but newer benchmarks like OJBench and Toolathlon have less independent replication. For decisions, prioritize standard coding and reasoning benchmarks, then run your own prompts.
A follow-up hands-on comparison is planned with the same prompts across Claude Opus 4.7, GPT-5.4, GLM 5.1, and Kimi K2.6. Until then, treat the benchmark table as a shortlist, not a final purchasing decision.
What does 88% cheaper mean in real usage?
If the quality is close enough, the price gap becomes hard to ignore.
$0.60 / $2.50 vs $5 / $25
Kimi K2.6 API pricing is $0.60 input and $2.50 output per 1M tokens. Claude Opus 4.7 is $5 input and $25 output (source: DEV Community). That is 8.3x cheaper on input and 10x cheaper on output. Under a common 1:2 input-to-output ratio, the blended saving is about 88%.
| Item | Kimi K2.6 | Claude Opus 4.7 | GPT-5.4 |
|---|---|---|---|
| Input (1M tokens) | $0.60 | $5.00 | $3.00 |
| Output (1M tokens) | $2.50 | $25.00 | $15.00 |
| Cache discount | About 50% input reduction | 90% cache read discount | About 50% input reduction |
| Minimum request fee | None | None | None |
| 1M context surcharge | Not applicable, 256K max | Applies past threshold | Applies past threshold |
| Weights | Downloadable | Closed | Closed |
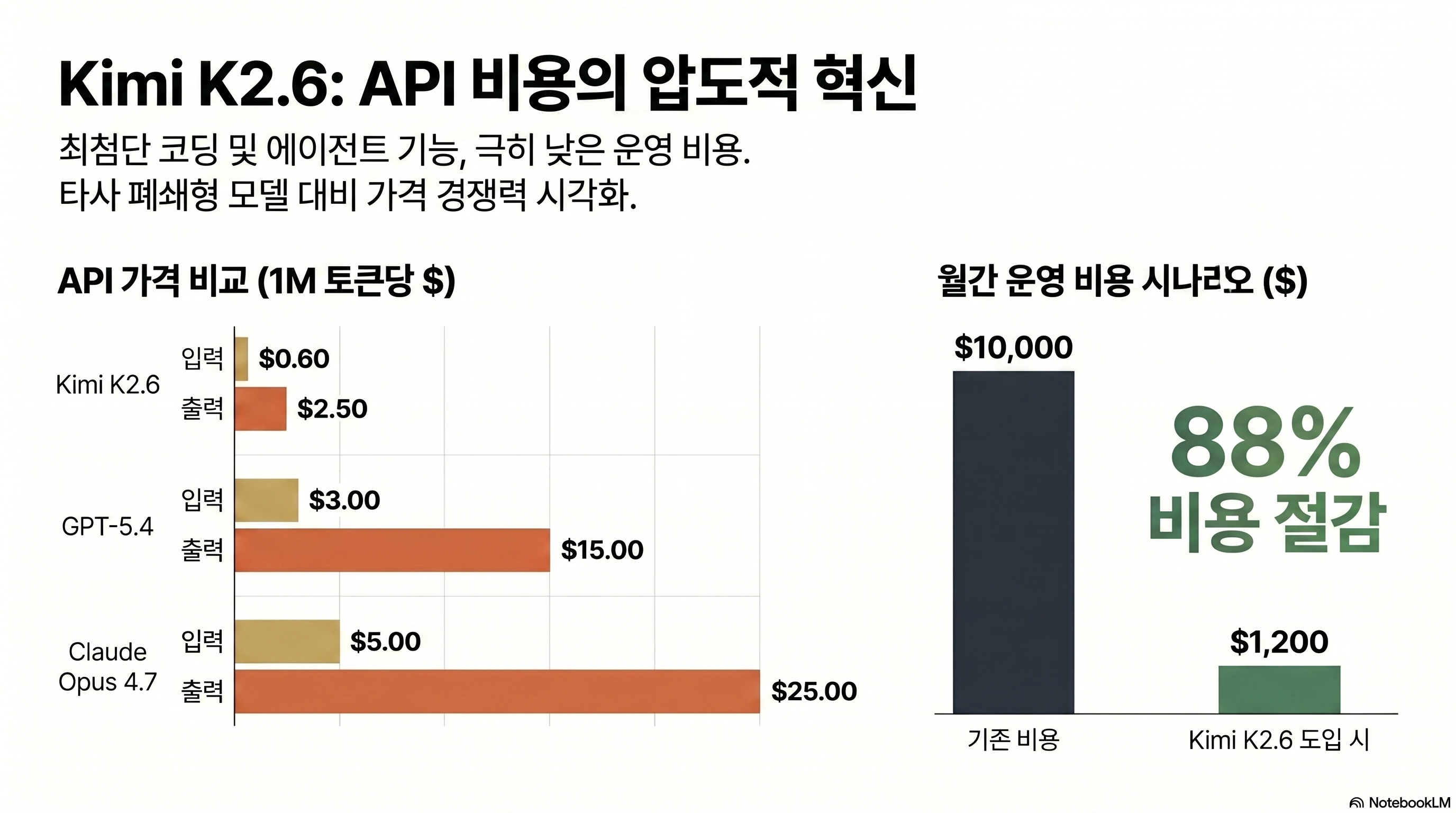
A practical monthly-bill scenario
Imagine a five-developer team running coding agents all day. If Opus 4.7 usage lands around $10,000/month after extended thinking and task budgets, the same token volume on K2.6 can model out around $1,200/month after operational overhead. The exact number depends on prompt length and retries, but the direction is clear: this is not a 10% optimization. It is a budget-line change.
Caveat: cheap tokens do not mean equal total tokens
Artificial Analysis reports that K2.6 can use more tokens per session than GPT-5.4. The effective saving may be 82-85% instead of the advertised 88%. That still leaves a large gap against Opus 4.7, but it matters for annual budgets.
What is the 300-subagent swarm feature?
The most unusual K2.6 feature is not a single benchmark. It is the 300-subagent swarm claim: one orchestrator can coordinate up to 300 subagents and more than 4,000 steps over sessions lasting 12+ hours (source: MarkTechPost).
| Feature | Kimi K2.6 | Claude Code style agents |
|---|---|---|
| Parallel subagents | Up to 300 | Commonly 5-10 in practice |
| Long-horizon steps | 4,000+ | Tool and platform dependent |
| Context | 256K | Model dependent |
| Orchestration | Native swarm framing | External agent framework |
| Best fit | Large parallel search and coding swarms | High-quality focused coding loops |

The feature is compelling for massive issue triage, codebase mapping, and multi-repo migration planning. It is also easy to over-romanticize. More agents mean more state, more failures, and more orchestration overhead. The safest first test is not “launch 300 agents.” It is “run 10-20 small agents on one known repository and compare the merged result against Opus 4.7.”
Can Kimi Code CLI replace Claude Code?
Kimi Code CLI is Moonshot’s terminal agent. The replacement story is credible but not universal.
Where it can replace Claude Code
Kimi is worth testing when the bottleneck is cost, not absolute coding quality:
- Repetitive repository analysis
- First-pass refactors
- Test generation drafts
- Documentation updates
- Bulk issue classification
- Agent workflows where a failure can be reviewed before merge
Where Claude Code still has the edge
Claude Code remains the safer default for high-value edits, architecture-level refactors, and workflows where tool behavior and editor integration matter more than token price. Opus 4.7’s SWE-Bench Pro advantage is real. If a failed patch costs an engineer two hours, the cheaper model may not be cheaper.
Pros
- + Much cheaper API pricing than Opus 4.7
- + Open-weight model with downloadable weights
- + OpenAI-compatible and Anthropic-compatible API paths
- + Strong coding benchmarks for the price
- + Native framing around long-horizon agent swarms
Cons
- − Opus 4.7 still leads SWE-Bench Pro
- − Default API region and data-governance questions matter
- − Token usage can be higher than GPT-5.4
- − Independent replication is still catching up
- − Local deployment requires serious hardware
Is a Chinese model safe for sensitive data?
This is the section many teams should read first. Model quality and API price are irrelevant if the data route violates internal policy.
Default API region and data governance
The API entry point is run by Moonshot AI, a China-based company. If your prompts contain source code, customer data, contracts, medical records, or regulated financial data, you need legal and security review before sending them to the hosted API. In many organizations, the hosted API is appropriate only for non-sensitive workloads.
Modified MIT license
K2.6’s Modified MIT license is permissive for most teams. The extra attribution requirement applies to extremely large services, such as products with 100M monthly active users or $20M monthly revenue. Most startups and internal tools will not hit that threshold, but product teams should still read the exact license text (source: Hugging Face).
Local GGUF path
Unsloth and the community provide quantized weights, including GGUF options. Local execution avoids the hosted-region issue, but the hardware requirement is heavy. Even 4-bit quantization can be hundreds of gigabytes, putting practical deployment in multi-GPU server territory rather than hobby laptop territory. For lighter local use, Gemma 4 remains easier to run.
How do you use the 256K context window?
256K is not a marketing number if you use it carefully.
Scenario 1: medium monorepo refactor
A 200K-line Python monorepo cannot fit in full, but 256K can hold 30-50 key files plus architecture notes. That is enough for targeted refactoring. As discussed in the Karpathy LLM Wiki piece, blindly increasing context is not the same as feeding the right context.
Scenario 2: agent swarm state
If 300 subagents each carry 800 tokens of state, that alone is 240K tokens. K2.6’s context size is almost tailor-made for swarm orchestration state. Compressing state into a graph, as in Graphify, can push the same orchestration further.
Scenario 3: RAG-less issue triage
For issue triage, you can include the issue thread, related files, failing logs, and previous attempts in one context. This is where K2.6’s cheap input price matters. You can afford broader context during exploration, then hand the final high-risk patch to a stronger model if needed.
What is the community saying?
- "Open-weight Kimi K2.6 takes on GPT-5.4 and Claude Opus 4.7 with agent swarms." — the-decoder
- "The new leading open weights model." — Artificial Analysis
- "Beats top US models on some benchmarks." — officechai
- "The economics are impossible to ignore if quality is close enough." — developer community discussion
- "Hallucination rate remains a concern next to Opus 4.7." — Artificial Analysis
- "The default API region is mainland China, so sensitive data needs a separate path." — DEV Community
- "Token consumption can be higher, so the real saving is smaller than the sticker price implies." — Artificial Analysis report
- "1M context claims are wrong. The official context is 256K." — Hugging Face discussions
Troubleshooting Q&A
API compatibility
If an OpenAI-compatible client fails, check the base_url, model name, and tool-call schema first. Some clients hard-code OpenAI model assumptions. For Anthropic-compatible clients, test one simple non-tool request before enabling a full agent loop.
Chinese characters in Korean or English output
Some users report unwanted Chinese phrasing or mixed-script output. Add an explicit system prompt:
Reply only in English.
Do not use Chinese characters unless the user explicitly asks for Chinese text.
When uncertain, ask a clarification question instead of inventing details.Cost evaluation
Do not compare only per-token price. Measure:
- Total input tokens
- Total output tokens
- Retry count
- Tool-call failure count
- Human correction time
- Final accepted patch rate
Those numbers tell you whether 88% cheaper survives contact with your workflow.
Conclusion: who should try Kimi K2.6 now?
Key takeaway
Kimi K2.6 is not simply a cheap model. It is the strongest open-weight challenge to frontier coding models so far, with a price gap large enough to change how teams budget agent workflows. It is still not an automatic Opus 4.7 replacement. Use it where cost dominates and verification is available; keep Opus 4.7 for the highest-risk coding work.
Try Kimi K2.6 if your Claude Opus 4.7 or GPT-5 bill is becoming the limiting factor, your workload is mostly coding-agent exploration, and your data can safely use the hosted API or a local deployment. Avoid it for sensitive data until legal and security teams approve the route.
Build a real evaluation set
Take the top 10 token-heavy tasks from last week and save the expected outputs or accepted patches.
Run K2.6 and Opus 4.7 side by side
Use the same prompt, same tool schema, and same timeout. Track quality, cost, and retry count.
Route sensitive prompts separately
Send non-sensitive tasks to the hosted API first. Keep regulated code or documents on local GGUF or an approved model.
Review after 30 days
If savings stay above 82% and accepted-patch quality is close, promote K2.6. If quality falls below target, keep it as a draft or exploration model.
Is Kimi K2.6 really open source?
Can Kimi K2.6 replace Claude Opus 4.7?
Does Kimi K2.6 have a 1M context window?
Is the hosted API safe for private code?
What hardware do I need for local K2.6?
How should I test the 88% savings claim?
Was this helpful?
One tap shapes what gets written next.

GLM 5.1 Review: Run Claude Code at 1/5 the Price with Open-Weight SOTA
How to run GLM 5.1 in Claude Code at one-fifth the cost, plus what Z.AI's official docs reveal about subscription-backed API access, Vision MCP, and GLM-Image.
Read
Oh My OpenAgent Review: A Multi-Agent Alternative to Claude Code (2026)
An honest one-month review of OpenCode + Oh My OpenAgent, covering ultrawork, agent roles, pricing, failure modes, and whether it is ready to replace Claude Code.
Read
Qwen 3.6 27B Review: A Local Coding Agent Tested on RTX 4090 and M4 Max (2026)
A practical review of Qwen 3.6 27B and 35B-A3B for local coding work, covering benchmarks, VRAM, token speed, Apache 2.0 licensing, and Claude alternatives.
Read