Beyond RAG: Karpathy's LLM Wiki Pattern Explained (2026)
Hit RAG's limits? Andrej Karpathy's LLM Wiki pattern is a markdown-first alternative — 3-layer architecture, 95% token savings, exploding ecosystem in 2 weeks.

Quick take
Start with this judgment
21 min readBottom line
Hit RAG's limits? Andrej Karpathy's LLM Wiki pattern is a markdown-first alternative — 3-layer architecture, 95% token savings, exploding ecosystem in 2 weeks.
- Best for
- Readers comparing cost, capability, and real limits before choosing a tool
- What to check
- RAG alternative · LLM knowledge base · Karpathy LLM Wiki
- Watch out
- Pricing and features can change, so confirm with the official source too.
3 key points
- A single gist that Andrej Karpathy published in late March 2026 racked up 16 million views and became the reference point for “life after RAG.” The core idea is a file-over-app philosophy: drop the vector DB and incrementally compile knowledge into a markdown wiki.
- Thanks to the 3-layer separation (Raw / Wiki / Schema), reports cite roughly 95% token savings per query. Within two weeks of the gist going public, five derivative implementations had shipped — the ecosystem moved first.
- That said, scale ceilings, hallucination contamination, and skipped lints are real traps, and the “RAG with extra steps” criticism has weight. This article covers the concept, the architecture, and the limits as of April 2026.
목차
- Why did Karpathy suddenly bring up 'LLM Wikis'?
- Why isn't RAG a fit for personal knowledge management?
- Why isn't a long context window enough?
- How does the LLM Wiki's 3-layer architecture work?
- What exactly is different between RAG and the LLM Wiki?
- How explosive has the LLM Wiki ecosystem been?
- What are actual users saying?
- Three limits of the LLM Wiki — what to watch out for
- If you're reading this now, where do you start?
- Frequently asked questions
Why did Karpathy suddenly bring up ‘LLM Wikis’?
In late March 2026, Andrej Karpathy posted a GitHub gist. The title was unremarkable: “How I use LLMs to manage my knowledge base.” Six weeks later it had 16 million views (source: remio.ai analysis). For a “how I use it” note from the OpenAI co-founder and former Tesla AI director, that’s an unusual reaction.
Why a simple tip post turned into a paradigm fight
The argument in the gist boils down to one sentence: “RAG is a stateless system; personal knowledge management calls for stateful compilation” (source: Karpathy gist). RAG (Retrieval-Augmented Generation) chops up source documents and pulls them out of a vector DB to interpret on each query. Karpathy’s pattern instead has the LLM synthesize (compile) the material once at ingest time and store it as human-readable markdown. After that, you just read what’s there.
VentureBeat summarized the claim as “Karpathy shares an LLM knowledge base architecture that bypasses RAG” (source: VentureBeat coverage). The key word was “bypass” — not interpret, not replace, not complement. Bypass. Meaning the premise itself gets overturned.
The shape of the debate — supporters and critics
Supporters said the pattern “finally puts into words why personal-scale RAG felt so bad.” Critics said it was “a Semantic Web rerun, a structure that only works at small scale, dressed up as a RAG alternative.” Both sides came with data. Supporters cited the 84% reduction in context tokens reported on Reddit’s r/ClaudeCode. Critics pointed to the scale ceiling (around 400,000 words), beyond which a hybrid is ultimately required.
What this article aims to do
This article lays out what the Karpathy LLM Wiki pattern (LLM-KB, file-over-app) is, what problem it tries to solve, where it’s been validated, and where it breaks — as of April 2026. It is a concept piece, not a product walkthrough. Specific implementation tools (Graphify, llm-wiki-mcp, etc.) are mentioned only in the ecosystem timeline section.
Why isn’t RAG a fit for personal knowledge management?
The claim isn’t that RAG itself is wrong. For scenarios with low update frequency and a constrained query pool — enterprise FAQ chatbots, internal document search — RAG still works well. The trouble is in the kind of environment Karpathy assumed: a “personal research archive” where sources are heterogeneous and knowledge has to accumulate.
Stateless — re-interpreting from scratch every time
RAG runs a similarity search on every query, pulls chunks, and pushes them into the LLM. Ask the same question yesterday and today, and the LLM interprets the source like it’s seeing it for the first time, every time. Yesterday’s insight doesn’t automatically fold into today’s answer. remio.ai called this the “absence of compounding” (source: remio.ai). Add as many sources as you want — the knowledge graph doesn’t get denser.
Black box — vector DBs aren’t readable
A vector embedding is a 1,536-dimensional float array. You can’t open it up and confirm “ah, this document was understood like that.” It’s hard to track whether the index is wrong, whether chunk boundaries were cut badly, or how often retrieval misses happen. techbuddies.io flagged this as “non-auditability” (source: techbuddies.io). Worse, when retrieval fails, the system doesn’t say “couldn’t find it” — it fabricates a plausible answer. Silent failure.
A ceiling on synthesis depth — chunks are just chunks
The essence of personal knowledge management is “cross-referencing what multiple sources say about the same concept.” RAG grabs top-k chunks and stitches them together one-shot. If five papers contain different claims by the same author, RAG pulls some of those chunks and tells the LLM to “figure it out.” That’s closer to sampling than synthesis. And it’s unrelated to the kind of frontier-model gains like Gemma 4’s function-calling jump from 6% to 86%. A better model can’t deepen synthesis if the input is thin.
Karpathy himself confirmed in a gist comment: “For scenarios like large-scale enterprise search or legal Q&A, RAG is still the right fit. I’m talking about personal-scale static archives” (source: Karpathy gist comment). The comparisons in this article are bounded to the ‘personal / small-scale knowledge management’ context.
Why isn’t a long context window enough?
“If a model has a 1M-token context, can’t I just dump everything in?” That’s the most common pushback. With Gemini 3.1 Pro’s 1M tokens, Claude Opus 4.7’s 1M context, and other frontier models rolling out serious long-context support, the objection comes up more often. But in practice you hit three walls at once.
Token cost isn’t linear
Doubling the context doubles the cost. Meanwhile, the LLM Wiki pattern reports roughly 95% token savings (source: levelup.gitconnected analysis). The reason is simple: instead of loading 400,000 source words on every query, you follow a pre-compiled summary page and 5–10 related wikilinks.
The lost-in-the-middle problem
Research has repeatedly reproduced the finding that models miss material in the middle when the context is packed. Actually using 1M tokens requires a retrieval strategy — at which point a search layer enters the picture again. Long context isn’t a one-shot fix.
Permanent storage vs. ephemeral session
Information loaded into the context window disappears when the session ends. Tomorrow’s same task means loading it again. No compounding. The wiki, on the other hand, lives on disk. The next query starts from an already-synthesized state.
| Approach | Tokens per unit | Persistence | Maintenance cost |
|---|---|---|---|
| RAG retrieval | Medium (top-k chunks) | Vector DB reindexing required | Pipeline upkeep |
| Long-context full dump | Very high (full load every query) | Lost when session ends | Low (but cost explodes) |
| LLM Wiki compile | Low (summary + wikilinks) | Permanent markdown | Heavy investment in lint/ingest |
How does the LLM Wiki’s 3-layer architecture work?
The substantive contribution of Karpathy’s gist is the ‘3-layer separation principle.’ Each layer has a different owner and different write permissions.
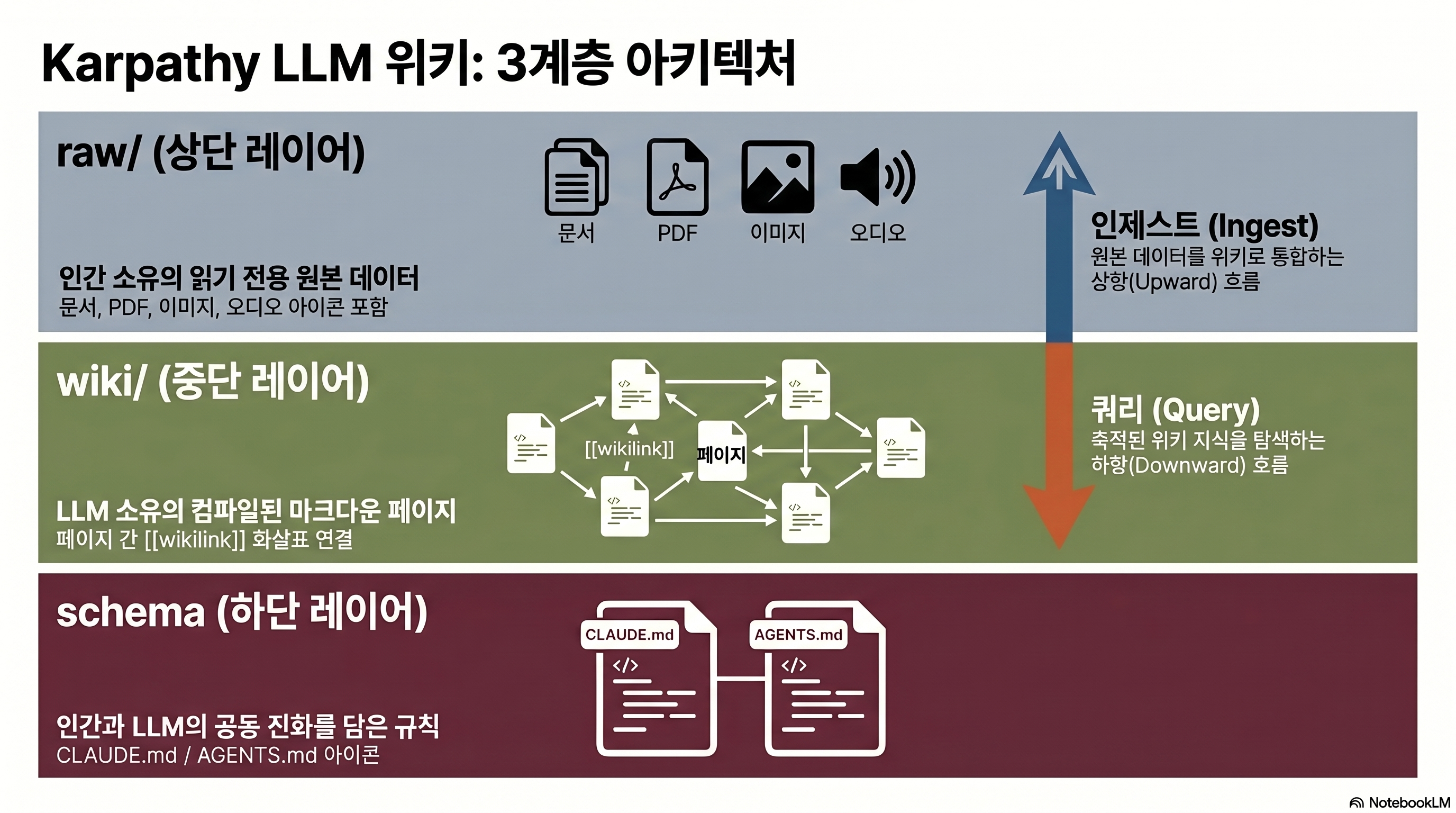
Raw layer — the source of truth, hands off
The raw/ directory holds PDFs, markdown, transcripts, and images in their original form. Use Obsidian Web Clipper to clip a web article in full, and the images come down locally too. This layer is read-only. If you decide it’s been corrupted, you wipe the wiki layer and rebuild from raw. It plays the same role as the original commits in a Git history.
Wiki layer — the LLM’s synthesized knowledge
The wiki/ directory accumulates compiled pages as markdown + YAML frontmatter + [[wikilinks]]. When a new source comes in, the LLM modifies 10–15 pages simultaneously in a single ingest pass. It writes the summary page, creates or updates entity/concept pages, plants cross-reference links, flags any contradictions it finds, and updates index.md. That’s what “compile” really means.
Schema layer — the rules humans and LLMs grow together
CLAUDE.md or AGENTS.md holds the workflow contract: ingest / query / lint order, naming rules, directory structure, conventions like “how to flag contradictions when found.” This file already exists in the dev tools ecosystem. Claude Code’s CLAUDE.md system is a prime example. The anchor-file pattern for telling an LLM about codebase conventions has been transplanted directly to knowledge work.
index.md — the search mechanism without a vector DB
The special file index.md collects category-grouped page lists with one-line summaries. When a query comes in, the LLM reads index.md first, then drills down into the relevant page. That’s the answer to “how does search work without a vector DB?” The catch: the practical limit is reportedly around 100–200 pages (source: rohitg00 extension gist). Beyond that, index.md itself bloats and has to be split.
| Layer | Owner | File format | Change rule |
|---|---|---|---|
| Raw | Human | PDF / MD / images / transcripts | Read-only, original preserved |
| Wiki | LLM | Markdown + frontmatter + [[wikilinks]] | LLM modifies 10–15 files simultaneously on ingest |
| Schema | Human + LLM (co-evolved) | CLAUDE.md / AGENTS.md | Manual commit when contract changes |
What exactly is different between RAG and the LLM Wiki?
Now that the architecture is clear, on to the head-to-head. Three axes: token cost, accuracy, maintenance.

Token cost — why 95% savings is possible
Reports cite roughly 95% token savings versus RAG (source: levelup.gitconnected analysis). The reason is structural. RAG re-encodes top-k chunks (usually 5–10) on every question. The LLM Wiki only follows 1–3 already-synthesized summary pages plus relevant wikilinks, so the input size shrinks to a single digit. Among the derivative implementations, one benchmark reported 71.5x fewer tokens per query vs. loading the full raw files (source: Analytics Vidhya analysis).
Accuracy — retrieval miss disappears
When RAG can’t pull the answer in top-k, it fails silently. With the LLM Wiki, if index.md misses a relevant page, the LLM can at least confirm “that page doesn’t exist.” Within the context limit, recall is 100%. The catch: once you exceed that limit, a search layer is needed again — covered in the limits section.
Maintenance — self-healing lint
The LLM Wiki periodically runs a ‘lint mode’: merge duplicate entity pages, repair broken wikilinks, refresh stale summaries, clean up contradiction flags. The process self-heals the knowledge graph. To do the equivalent with RAG, you re-run the reindexing pipeline — and embedding-level errors still aren’t visible.
| Dimension | RAG | LLM Wiki |
|---|---|---|
| State | Stateless (rediscovered each query) | Stateful (incrementally compiled) |
| Storage format | Opaque vector embeddings | Human-readable markdown |
| Search pipeline | Similarity search (vector DB) | index.md scan → drill-down |
| Infra complexity | Vector DB + embedding model + chunker | Filesystem + LLM agent |
| Token cost | Retrieval per query | ~95% savings vs raw load |
| Reliability | Silent failure on retrieval miss | 100% within context limit |
| Maintenance | Reindexing pipeline | Active LLM self-healing lint |
| Auditability | Hard (vector black box) | Transparent (file diff) |
| Synthesis depth | Shallow (one-shot top-k) | Deep (incremental compile) |
This table isn’t a ‘tech performance comparison’ — it’s a ‘data model comparison.’ RAG solves knowledge management as a search problem. The LLM Wiki solves it as a compilation problem. That framing difference determines all nine rows of the table.
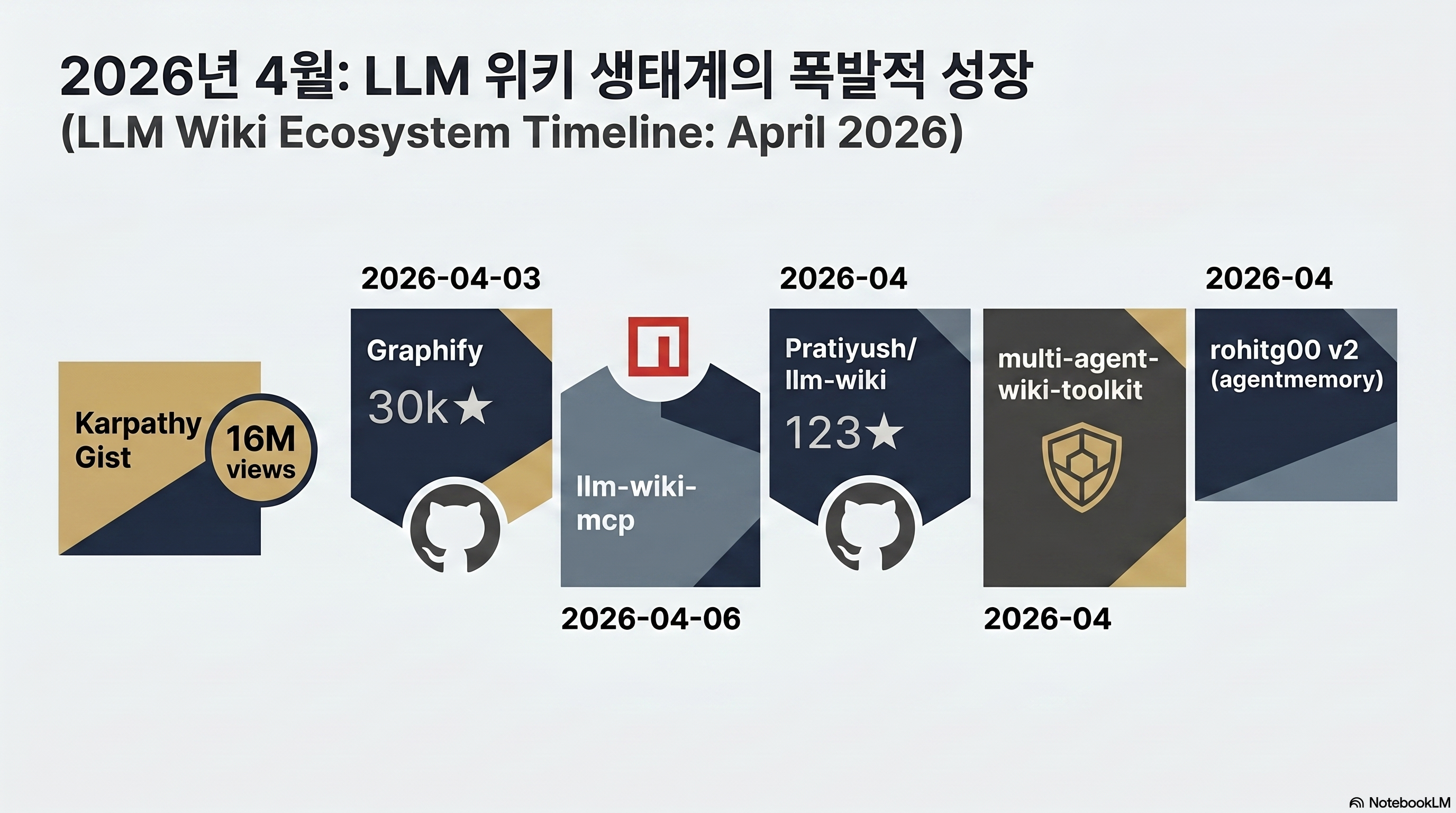
How explosive has the LLM Wiki ecosystem been?
The theory was in the gist. Implementation was the issue. And yet within two weeks at least five derivative implementations had shipped — concrete evidence of “what you can do with this pattern.”
Watch the narrative speed
Within 48 hours of the gist going up, the first serious implementation was on GitHub (source: viral post). In days, the projects branched out in different directions: MCP-server packaging, automatic Claude Code session compilation, multi-agent extensions, agentmemory integration. The ecosystem became a speed contest over “who grabs the slot first.”
A map of the derivatives — what angles split off
Each implementation emphasizes a different facet of the same pattern. Part 1 only covers the per-category positions. Hands-on installation and use is covered in depth in Part 2 of this series.
| Implementation | Axis (angle of attack) | One-line take |
|---|---|---|
| safishamsi/graphify | Multimodal + graph topology | Leiden community detection clusters code, PDFs, images, video; ships as a CLI skill |
| llm-wiki-mcp (npm) | Protocolization | MCP server for native Claude Desktop integration |
| Pratiyush/llm-wiki | Auto-compile session logs | Claude Code conversations get loaded directly as wiki pages |
| redmizt/multi-agent-wiki-toolkit | Multi-agent safety | Contamination firewall blocks cross-agent pollution |
| rohitg00/llm-wiki-v2 | Long-term memory layer | agentmemory layer keeps past context alive |
The ecosystem’s flagship — a quick look at Graphify
Of the five, the project the community piled into first is safishamsi/graphify. Three things drew attention. First, the input range is broad — not just code but PDFs, images, and video, automatically converted into a knowledge graph. Second, where other derivatives stop at a set of markdown files, Graphify builds graph topology with Leiden community detection — compressing meaning at the cluster level rather than via simple wikilinks. Third, it plugs straight into Claude Code, Cursor, and Gemini CLI as a “skill.” Layered on top of existing workflows instead of replacing them. These three traits combined to push it past 30,000 GitHub stars in two weeks.
This article is the concept piece, though. Part 2 of this series owns the actual Graphify install, folder design, first-ingest verification, Korean-source pipeline, and how to measure whether it really is a RAG alternative. For now, just remember that “Graphify is one axis of this ecosystem.”
Why so fast
The Karpathy gist itself already contained all the implementation hints. The 3-layer directory structure, index.md drill-down, lint routine, wikilink syntax — a blueprint you could just follow. No original research required, low enough complexity for an engineer to carve out over a weekend, so the bar to entry was low and the contest became a sprint.
What are actual users saying?
- "I compiled six months of stale research notes and a pattern showed up — I'd reached the same conclusion several times and forgotten it. A connection search would never have surfaced." — Reddit r/learnmachinelearning
- "I automated it as a Claude Code plugin and context tokens dropped 84%. The cost difference is tangible." — Reddit r/ClaudeCode (103 upvotes)
- "Manual note-taking has basically vanished. The conversation becomes the wiki page. A real paradigm shift." — Reddit r/ClaudeCode plugin showcase
- "It still doesn't solve the contradiction-structure problem the Semantic Web has failed at for 30 years. Just a renamed rerun." — Hacker News comment
- "There's a contradiction — it only works at small scale. At scale you end up bolting vector search onto RAG, so isn't this just RAG with extra steps?" — Reddit r/MachineLearning
- "Having an LLM write your wiki for you is worthless for your own growth. The act of organizing is the learning." — Reddit comment (75 upvotes)
The shared keyword in positive reactions — ‘compounding’
The common thread in the positive reports is the felt sense that “it gets stronger over time.” Many testimonies say the first week is underwhelming, but answer quality starts shifting after 3–6 months.
The shared keyword in negative reactions — ‘self-deception’
The criticism, in contrast, converges on “is this really new?” Semantic Web rerun, RAG with extra steps, learning outsourcing. Three branches with the same root: suspicion that the packaging is overblown.
Three limits of the LLM Wiki — what to watch out for
This section isn’t neutral — it’s closer to defense. The traps you should know before adopting the pattern.
Scale ceiling — it breaks at 400,000 words
Karpathy’s own usage is around 100 documents, roughly 400,000 words (source: techbuddies.io). Reports of index.md-based search hitting its limit cluster around that figure. Beyond it, a hybrid (markdown + vector search) becomes necessary — and that’s the foundation of the “RAG with extra steps” critique.
Hallucination contamination becomes permanent — a wrong fact, once written, sticks
If the LLM records a wrong fact on a wiki page during compilation, every subsequent query references that error. RAG at least re-interprets from the source each time, so contamination is one-shot. The wiki makes it permanent. Periodic lint + cross-checking against the raw source + Silent Drift detection (freshness metadata) is essential.
Lint skipping — the first step people drop
In DIY implementations, the most commonly skipped step is lint. Ingest is fun; cleanup is boring. But a wiki without lint collapses under internal contradictions and duplication within three months. That’s why the rohitg00 extension highlights lint automation as a core feature.
| Limit | Symptom | Mitigation |
|---|---|---|
| Scale ceiling (~400k words) | index.md bloat, rising drill-down failure rate | Sub-indexes per category, run hybrid vector search alongside |
| Permanent hallucination contamination | Wrong entity pages get referenced repeatedly | Periodic lint + raw-source diff + freshness metadata |
| Silent Drift | Stale information returned with confidence | Per-page last_verified field + expiry alerts |
| Lint skipping | Duplicates and contradictions degrade the wiki | Force lint into the ingest workflow |
| Missing evaluation metrics | Can't measure health | Awaiting community standard; for now use coverage / link density as proxies |
The scale ceiling is a problem for later. Contamination accumulates from week one. Right after ingest, on the same day, make a habit of doing a first-pass audit against the raw source. The cost of fixing it later grows exponentially.
If you’re reading this now, where do you start?
The one-line takeaway
The LLM Wiki is a ‘knowledge compilation’ paradigm, not a ‘search optimization’ one. For personal and small-scale archives, it leads RAG on token efficiency and auditability — but if you don’t dodge the three traps (the 400k-word ceiling, hallucination contamination, lint skipping), it self-destructs in three months. Starting takes 30 minutes — make the raw / wiki / schema folders.
- Anyone with hundreds of personal research notes, papers, and bookmarks where search is increasingly failing
- Developers and researchers already comfortable in Claude Code / Cursor / Obsidian environments
- Anyone who built a RAG-based personal knowledge bot and felt “why are the answers so shallow?”
- Conversely, not recommended for beginners, writing learners, or those who want to “internalize knowledge through the act of organizing.” The learning-outsourcing critique applies precisely to this group.
Three things you can do today
Set up an Obsidian vault + 3 folders
Create just the three: raw/, wiki/, and index.md. The Web Clipper plugin alone is enough. 30 minutes start to finish.
Pick one derivative implementation and run an ingest test
From the five in the ecosystem, pick the one that fits your editor and workflow, then ingest 10–20 of your existing notes. Always compare the first compile result against the raw source to check for hallucinations. Per-implementation install and hands-on guides are covered in Part 2 of this series.
Draft your CLAUDE.md and lock in a weekly lint
In about 100 words, write the ingest/query/lint order and naming rules. Run a lint session on the same day every week to clean up duplicates and contradictions. Without this routine, the wiki collapses in three months.
From Part 1 to Part 2 — what’s covered, what’s next
That covers “why the LLM Wiki appeared, what its structure is, and why it’s blowing up now” — the theory side. The question readers usually feel at this point is the same: “I get the concept. So how do I plug it into my own folders?” That question is the starting point of Part 2.
This is Part 1 — the concept piece — of the Karpathy LLM Wiki series. Parts 2 and 3 turn the things only mentioned here into something concrete.
- Part 2 — Building Graphify in practice (read now): Take Graphify, only sketched here, and actually build a wiki with it. Folder design (
raw/,wiki/,index.md), the/graphifycommand flow, how to verify hallucinations by comparing the first ingest against the raw source, the Korean-source (HWP, PDF, news clippings) pipeline, and integration with Claude Code’s CLAUDE.md — followed step by step at the screenshot level. - Part 3 — Six-month operational report (forthcoming): Validates the “three limits” section above with real-world data. What actually breaks at the 400k-word ceiling, how hallucination contamination gets discovered and recovered, and how long it takes for the wiki to collapse when lint is skipped.
For now, just create the three folders — raw/, wiki/, index.md — and you can pick up directly in Part 2.
- Karpathy original gist (16M views; the comments are as valuable as the body)
- VentureBeat coverage (industry context)
- levelup.gitconnected analysis on 95% token savings (measured numbers)
- rohitg00 extension gist (measured 100–200 page index.md ceiling)
Frequently asked questions
Is it mature enough for production today?
Can I do this without Obsidian?
Should I drop RAG entirely?
Does it handle Korean sources (papers, blogs) well?
Any privacy risk?
How much does it cost?
Where should beginners start?
Topic tags

What Is Vectorless RAG? Is PageIndex a Real RAG Alternative?
A current guide to why PageIndex says it can search long documents without vector databases or chunking, and how to read its pricing, MCP surface, FinanceBench claims, and real limits.
Read
What Is PlayMCP? Kakao's MCP Hub and OpenClaw Integration Explained
A current guide to what PlayMCP really is, how Kakao's toolbox and mcp-gateway work, and why the OpenClaw integration matters.
Read
Andrej Karpathy's 4 AI Coding Warnings and the 100K-Star CLAUDE.md Repo
A deep dive into the four bad AI coding habits Karpathy warned about, the CLAUDE.md repo's four operating principles, what evidence supports them, and where the limits still are.
Read