Claude Opus 4.7 총정리 - 벤치마크·가격·GPT-5 비교 (2026)
Claude Opus 4.7의 벤치마크, 가격, GPT-5.4·Gemini 3.1 Pro 비교, xhigh 모드까지 2026년 4월 출시 최신 정보를 정리했다. 토큰 1.35배 이슈도 함께 다룬다.

빠른 결론
먼저 이렇게 보면 됩니다
약 43분 읽기한 줄 판단
Claude Opus 4.7의 벤치마크, 가격, GPT-5.4·Gemini 3.1 Pro 비교, xhigh 모드까지 2026년 4월 출시 최신 정보를 정리했다. 토큰 1.35배 이슈도 함께 다룬다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- Claude · Claude Opus 4.7 · Anthropic
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- Claude Opus 4.7은 2026년 4월 16일 출시된 Anthropic의 최상위 모델로, SWE-bench Pro 64.3%와 OSWorld 78%를 기록하며 자율 코딩 에이전트 부문에서 현시점 최고 점수를 확보했다.
- 입력 $5·출력 $25로 Opus 4.6과 표기 가격은 같지만 신규 토크나이저가 같은 텍스트를 최대 1.35배로 쪼개서 실제 청구액은 월 $300이 $405까지 오르는 사례가 보고됐다.
- 코딩·에이전트 중심 팀이라면 xhigh 모드와 Task Budgets로 비용을 통제하면서 도입하고, 웹 리서치·창작 중심이라면 GPT-5.4나 Gemini 3.1 Pro를 먼저 검토해야 한다.
목차
- Claude Opus 4.7, 4.6에서 정확히 뭐가 달라졌나
- 벤치마크로 본 Opus 4.7의 진짜 실력
- 가격은 그대로인데 청구액이 1.35배가 되는 이유
- Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro — 언제 뭘 써야 할까
- 새로 생긴 xhigh 모드와 Task Budgets, 실전 활용법
- 3.75MP 비전과 파일시스템 메모리 — 에이전트가 실전에 들어온다
- 실측으로 드러난 한계와 회귀 — MRCR 46pt 폭락까지
- 커뮤니티 반응 — 극과 극으로 갈렸다
- Claude Opus 4.7은 누가 써야 할까
- 결론 — 잠정 왕좌, 미토스를 기다리며
Claude Opus 4.7, 4.6에서 정확히 뭐가 달라졌나
Anthropic이 Opus 4.6을 내놓은 지 약 5개월 만에 Opus 4.7을 공개했다. 버전 숫자만 보면 0.1짜리 마이너 업데이트처럼 보이지만, 실측 벤치마크와 API 스펙을 열어보면 코딩 에이전트 축에서는 세대 교체에 가깝다. 반대로 롱컨텍스트 검색과 창작 같은 축에서는 눈에 띄는 회귀가 보고됐다. 이번 글은 출시 스펙·벤치마크·가격·경쟁 모델 비교·한계를 한 번에 짚어서, “우리 팀이 지금 써야 할까”에 바로 답을 주는 데 목적이 있다.
2026년 4월 16일 정식 출시
Anthropic은 공식 블로그에서 Opus 4.7을 2026년 4월 16일 목요일에 공개했다 (출처: Anthropic News). 같은 날 Claude.ai와 API에서 동시 제공이 시작됐고, AWS Bedrock·Vertex AI·Microsoft Foundry·Snowflake Cortex까지 주요 클라우드 마켓플레이스가 48시간 이내에 연이어 활성화됐다 (출처: Help Net Security). 내부 코드명은 “Neptune v2”로 알려졌고, 4.6 대비 학습 토큰 규모보다 사후 훈련(Post-Training)에 집중한 것으로 보고됐다. 안전 등급은 ASL-3 수준을 유지했고 생물·화학·사이버 분야 리스크 완화 층이 추가됐다.
GitHub Copilot도 공개 당일 “Pro+”, “Business”, “Enterprise” 플랜에서 Opus 4.7 선택을 열었다. 그 결과 Cursor·Windsurf·Zed 같은 서드파티 에디터에서도 드롭다운 하나만 바꾸면 바로 쓸 수 있는 구조가 됐다. 이 부분은 Claude Code 완전 정복에서 다룬 공식 CLI 워크플로와 함께 짚어두면 도입 설계가 한결 쉬워진다.
모델 ID와 지원 플랫폼
API에서 부르는 정식 모델 ID는 claude-opus-4-7이다 (출처: Claude Platform Docs). Vertex AI는 claude-opus-4-7@20260416, Bedrock은 anthropic.claude-opus-4-7-20260416-v1:0 형태로 날짜 suffix를 붙인다. 지식 컷오프는 2026년 1월 말로 명시됐고, 기본 max_tokens은 8192다. 가장 눈에 띄는 변화는 temperature·top_p·top_k 파라미터가 “non-default 값을 넣으면 400 에러”를 돌려준다는 점이다. Anthropic은 “Opus 4.7부터 이 세 파라미터는 사실상 read-only”라고 못 박았다.
단 한 문장으로 요약하면
Opus 4.7은 코딩 에이전트·컴퓨터 사용·MCP 도구 호출 축에서 한 단계 올라섰고, 가격 라벨은 유지됐지만 토크나이저 교체로 실효 비용이 올라갔으며, 롱컨텍스트 정밀 검색과 창작에서는 회귀가 관찰된 모델이다. 아래 표는 4.6과의 사양 차이를 한눈에 보여준다.
| 항목 | Opus 4.7 | Opus 4.6 |
|---|---|---|
| 출시일 | 2026-04-16 | 2025-11-24 |
| 모델 ID | claude-opus-4-7 | claude-opus-4-6 |
| 컨텍스트 입력 | 1,000,000 토큰 | 1,000,000 토큰 |
| 최대 출력 | 128,000 토큰 | 64,000 토큰 |
| 지식 컷오프 | 2026년 1월 | 2025년 7월 |
| Effort 레벨 | low / medium / high / xhigh / max | low / medium / high / max |
| Extended Thinking | Adaptive only, 기본 OFF | budget 파라미터 지정 가능 |
| Vision 해상도 | 2576 × 2576px / 3.75MP | 1568 × 1568px / 1.15MP |
| 지원 플랫폼 | Claude.ai / API / Bedrock / Vertex / MS Foundry / Snowflake / Copilot | Claude.ai / API / Bedrock / Vertex |
| 안전 등급 | ASL-3 (보강) | ASL-3 |

벤치마크로 본 Opus 4.7의 진짜 실력
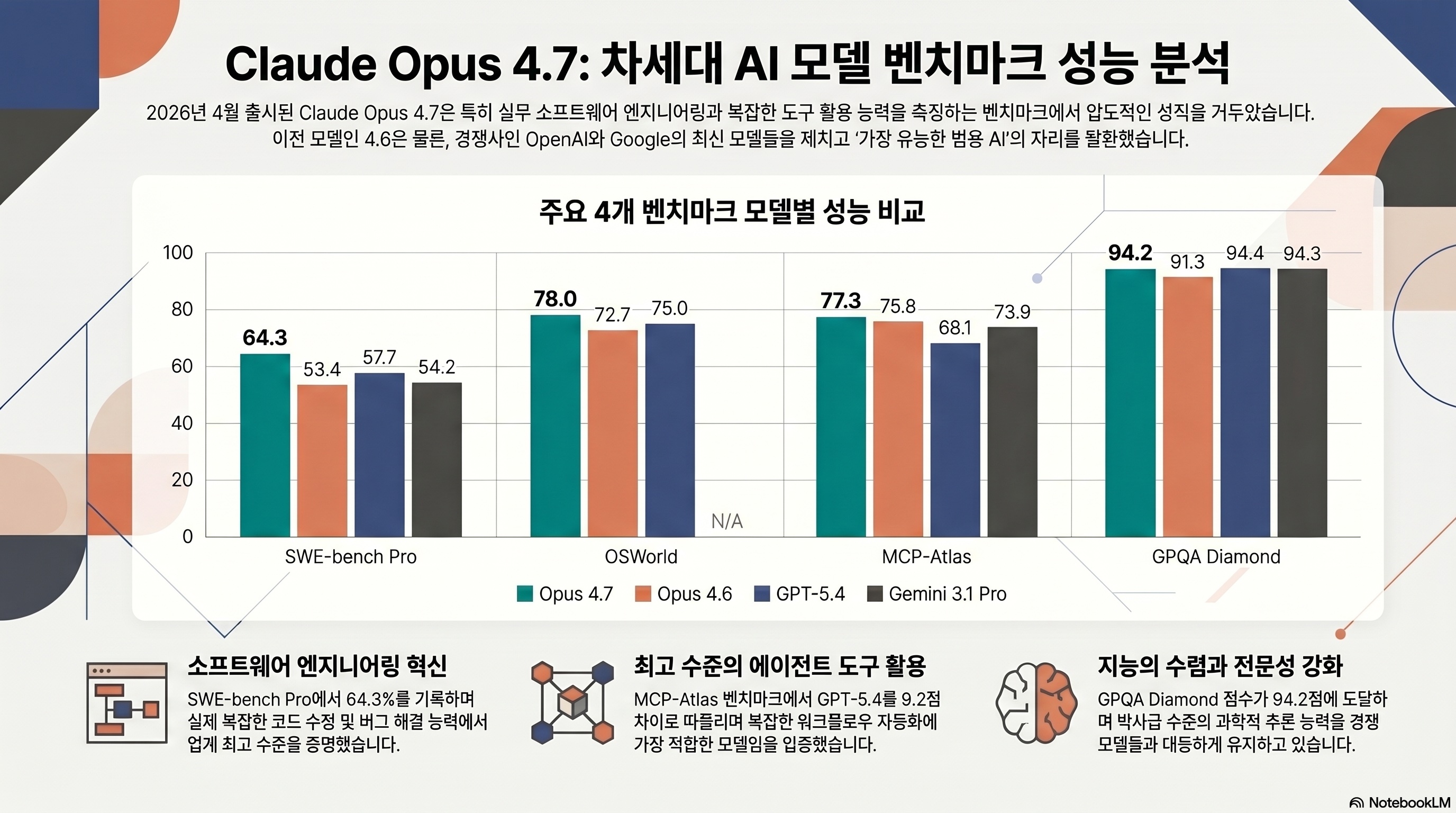
Opus 4.7 발표문에서 가장 먼저 눈에 들어오는 수치는 SWE-bench Pro 64.3%다. GPT-5.4가 57.7%, Gemini 3.1 Pro가 54.2%를 기록한 상황에서, 같은 벤치마크에서 프론티어 모델들을 6–10포인트 앞선다 (출처: Vellum AI). 이 섹션에서는 코드·컴퓨터 사용·도구 호출·일반 지능까지 벤치마크 축을 뜯어보고, 실사용 지표도 함께 확인한다.
SWE-bench Verified 87.6%, Pro 64.3% — 코딩 에이전트 역대 최고
SWE-bench(실제 깃허브 이슈를 패치하는 소프트웨어 엔지니어링 벤치마크) Verified에서 Opus 4.7은 87.6%를 기록했고, 4.6의 80.8% 대비 약 7포인트가 올랐다 (출처: The Next Web). 더 중요한 건 SWE-bench Pro다. 유료 저장소를 대상으로 하는 이 벤치마크는 Verified보다 오염(data leakage) 가능성이 낮아 실무 변별력이 높다고 평가받는다. Opus 4.7의 Pro 64.3% 점수는 현시점 공개 모델 중 최고치다 (출처: Anthropic).
Anthropic이 별도로 공개한 내부 지표인 CursorBench 점수는 70%로, 4.6의 58%에서 12포인트 상승했다. 또한 Rakuten 내부 테스트에서 Opus 4.7은 “24시간 이상 자율 실행하면서 23개 파트로 태스크를 쪼개고 유닛 테스트까지 작성했다”는 검증 결과가 보고됐다. Replit은 자사 에이전트 성능이 Opus 4.7로 전환 후 “code generation accuracy 12p 향상”을 공개했다.
OSWorld 78%, 컴퓨터 사용 에이전트 도약
OSWorld-Verified(실제 OS 환경에서 마우스·키보드 조작으로 과업을 완수하는 벤치마크)는 78.0% 점수를 찍었다. 4.6의 72.7%, GPT-5.4의 75.0% 대비 유의미한 격차다 (출처: The Next Web). 컴퓨터 사용 에이전트는 스크린샷을 읽고, 클릭 좌표를 결정하고, 긴 세션 동안 상태를 유지해야 하는데 Opus 4.7은 이 세 축 모두에서 개선됐다.
MCP-Atlas(Model Context Protocol 기반 도구 호출 벤치마크)도 77.3%로 GPT-5.4(68.1%)를 9포인트 앞섰다. 이는 Anthropic이 밀어붙이는 MCP 생태계에서 Opus 4.7이 “기본값” 위치를 가져간다는 뜻이다.
CursorBench 70%와 Rakuten·Replit 실사용 지표
벤치마크 수치만으로는 체감이 안 올 수 있다. 아래 표는 주요 공개 벤치마크를 네 모델 기준으로 나란히 정리했다.
| 벤치마크 | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% | n/a | 80.6% |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Terminal-Bench 2.0 | 69.4% | 65.4% | 75.1% | 68.5% |
| OSWorld-Verified | 78.0% | 72.7% | 75.0% | n/a |
| MCP-Atlas | 77.3% | 75.8% | 68.1% | 73.9% |
| GPQA Diamond | 94.2% | 91.3% | 94.4% | 94.3% |
| BrowseComp | 79.3% | 84.0% | 89.3% | n/a |
| CharXiv Reasoning (tools) | 91.0% | 77.4% | n/a | n/a |
| OfficeQA Pro | 80.6% | 57.1% | n/a | n/a |
| MRCR (회귀) | 32.2% | 78.3% | n/a | n/a |
| AA Intelligence Index | 57 (1위/133) | 55 | 56 | 54 |
Artificial Analysis 종합 지수에서 Opus 4.7은 57점으로 133개 평가 모델 중 1위를 차지했다 (출처: Artificial Analysis). 다만 지수는 여러 벤치마크의 가중 평균이라 세부 영역 특성을 가리는 경향이 있어서, 아래 MRCR 회귀 같은 지표는 별도 축으로 따로 봐야 한다.
가격은 그대로인데 청구액이 1.35배가 되는 이유
Opus 4.7 발표 하루 만에 커뮤니티에서 “숨겨진 가격 인상”이라는 말이 돌기 시작했다. 가격표 숫자는 그대로인데 청구서 금액이 오른 이유는 토크나이저가 바뀌었기 때문이다. 이 섹션에서 정확히 숫자로 파고든다.
표기 가격은 Opus 4.6과 동일하다
공식 API 가격은 입력 $5 / 1M 토큰, 출력 $25 / 1M 토큰으로 Opus 4.6과 같다 (출처: Anthropic News). 프롬프트 캐시는 5분 저장 기준 $6.25, 1시간 저장 $10이고 읽기는 $0.50로 90% 할인이다. Batch API는 50% 할인이 유지됐다. 가격표만 보면 “패리티”에 가깝다. 문제는 가격표 너머에 있다.
신규 토크나이저가 같은 텍스트를 1.35배로 쪼갠다
Opus 4.7은 새로운 토크나이저를 쓴다. Finout 분석에 따르면, 같은 영어 텍스트도 1.0–1.15배, 같은 한국어·일본어·코드 블록이 섞인 입력은 1.25–1.35배까지 토큰 수가 늘어난다 (출처: Finout). Anthropic은 이를 “더 정확한 세분화”로 설명했지만, 동일 입력 대비 청구액이 구조적으로 올라간다.
Opus 4.6에서 그대로 쓰던 프롬프트를 4.7 모델 ID로만 바꿔 돌려도, 입출력 토큰 수가 10–35%까지 늘어날 수 있다. 월 $300 지출 팀이라면 $330–$405 구간으로 이동한다. 배포 전 프로덕션 샘플 500–1,000건으로 실측 토큰 비율을 먼저 확인하고, 예산 알람 상한선을 미리 당겨 둬야 한다.
실 비용 시나리오 계산
가격표와 실효 토큰을 합쳐서 3가지 시나리오로 계산했다. 모두 입력 80% / 출력 20% 가정이다.
- 시나리오 A — 월 $300, 영어 위주, 토큰 1.12배 가정 → 약 $336
- 시나리오 B — 월 $300, 한국어 + 코드 혼합, 토큰 1.28배 가정 → 약 $384
- 시나리오 C — 월 $300, 긴 컨텍스트 + 한중일 혼합, 토큰 1.35배 가정 → $405
실제 Finout 보고서는 “대형 고객사 중 한 곳이 배포 첫 주에 청구액 28% 증가를 확인했다”고 전했다. 해결책은 프롬프트 캐시 적극 활용(캐시 적중 토큰은 동일 $0.50 유지)과 Batch API 50% 할인을 기본값으로 돌리는 것이다.
| 항목 | Opus 4.7 | Opus 4.6 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| 입력 | $5.00 | $5.00 | $3.00 | $0.80 |
| 출력 | $25.00 | $25.00 | $15.00 | $4.00 |
| 캐시 쓰기 (5분) | $6.25 | $6.25 | $3.75 | $1.00 |
| 캐시 쓰기 (1시간) | $10.00 | $10.00 | $6.00 | $1.60 |
| 캐시 읽기 (90% 할인) | $0.50 | $0.50 | $0.30 | $0.08 |
| Batch API | 50% 할인 | 50% 할인 | 50% 할인 | 50% 할인 |
| 토크나이저 | v2 (신규) | v1 | v1 | v1 |
| 같은 텍스트 토큰 증가율 | 1.0~1.35배 | 기준(1.0) | 기준(1.0) | 기준(1.0) |
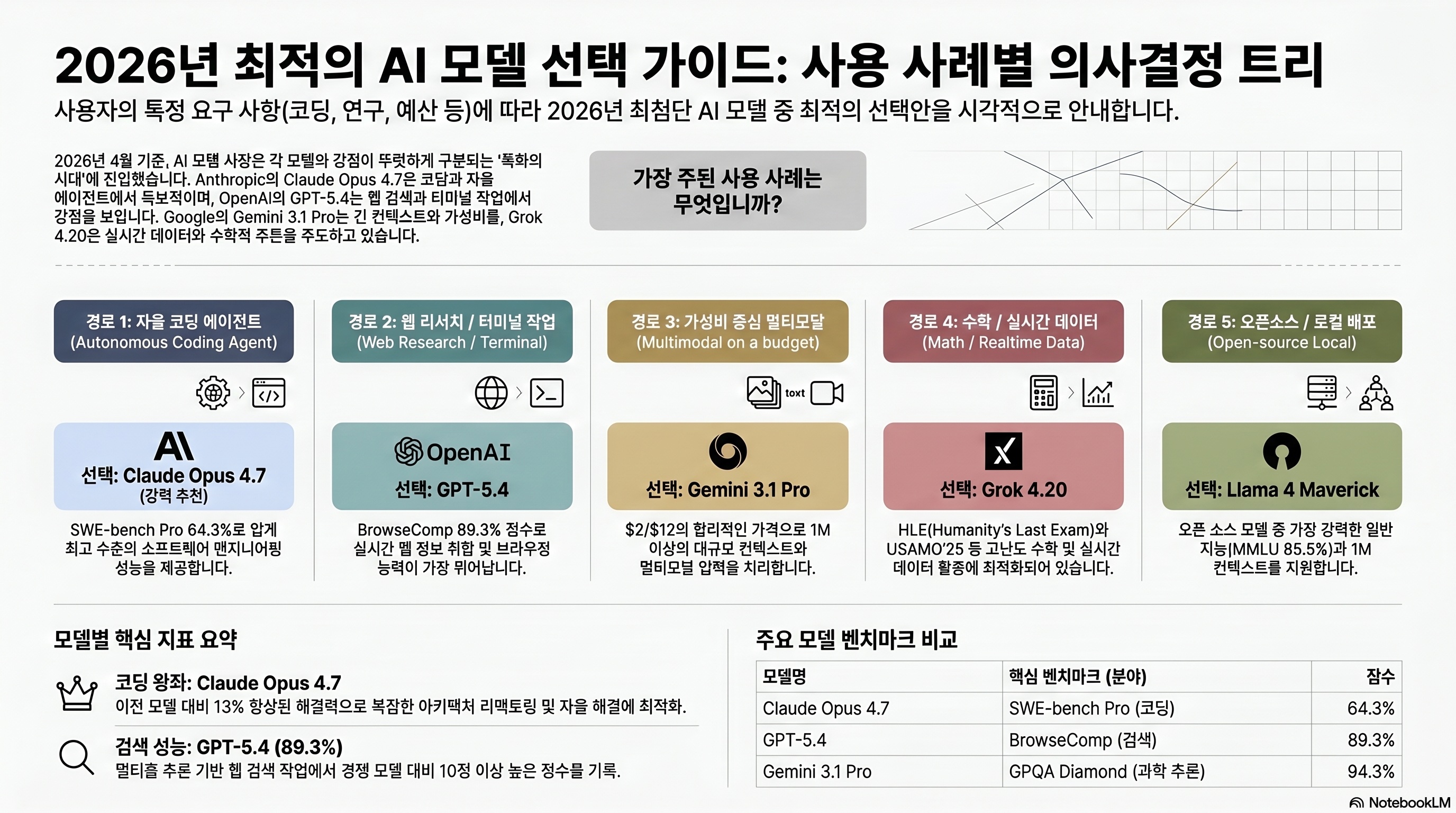
Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro — 언제 뭘 써야 할까
벤치마크와 가격을 봤으면 이제 “우리 팀에는 뭘 쓰지”가 남는다. 이 섹션은 경쟁 모델 4종(Opus 4.7 / GPT-5.4 / Gemini 3.1 Pro / Grok 4.20)을 축별로 정면 비교한다. 참고로 2026년 4월 19일 기준 xAI의 최신 모델은 Grok 4.20이고, 한때 유출로 화제가 된 “Grok 5”는 아직 공식 출시 전이다.
코딩 에이전트는 Opus 4.7이 독보적
SWE-bench Pro·OSWorld·MCP-Atlas 세 축에서 Opus 4.7이 1위다. 특히 자율 에이전트 long-session 워크로드에서 확실히 차이를 낸다. Cursor 공식 문서는 “autonomous, long-session coding, multi-file refactor에 최적”이라고 Opus 4.7을 명시했다 (출처: Cursor Docs). 단, Terminal-Bench 2.0에서는 GPT-5.4(75.1%)가 Opus 4.7(69.4%)을 앞선다. 셸 조작 중심이라면 GPT-5.4를 써야 한다.
웹 리서치·터미널은 GPT-5.4가 여전히 우세
BrowseComp는 GPT-5.4가 89.3% 점수로, Opus 4.7의 79.3%보다 10포인트 위다. Opus 4.7은 4.6(84.0%)보다도 회귀한 점수를 받았다. Anthropic은 “에이전트 분할 검색 패턴을 전제로 튜닝했다”고 설명했지만, 단일 브라우저 세션에서 깊이 파고드는 리서치에는 GPT-5.4가 유리하다. GPQA Diamond(대학원 수준 과학 지식 문제)도 GPT-5.4가 94.4%로 Opus 4.7의 94.2%와 동률에 가깝다.
가성비·멀티모달은 Gemini 3.1 Pro
Gemini 3.1 Pro는 입력 $2 / 출력 $12로 Opus 4.7 대비 절반 이하다. 멀티모달(비디오 30분까지 직접 입력)에서 압도적이고, 문서 요약·슬라이드 분석에서는 여전히 1티어다. 다만 SWE-bench Pro는 54.2%로 프론티어 모델 중 최하위권이다. 코딩이 주력이면 Gemini는 보조 역할로 남겨두는 게 맞다. 오픈소스 로컬 배포가 필요한 팀이라면 Gemma 4 리뷰에서 다룬 Gemma 4 27B가 “사내 망 배포 가능한 대안”으로 자주 언급된다.
| 항목 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro | Grok 4.20 |
|---|---|---|---|---|
| 가격 입력 / 출력 (1M) | $5 / $25 | $2.50 / $15 | $2 / $12 | $3 / $15 |
| 컨텍스트 | 1M (128K 출력) | 1.05M (272K 초과 2x) | 1M | 260K |
| 대표 강점 | SWE-bench Pro · OSWorld · MCP-Atlas | Terminal-Bench · BrowseComp · GPQA | MMMLU · 멀티모달 가성비 | 실시간 데이터 · 수학 |
| 대표 약점 | BrowseComp · MRCR 회귀 | MCP-Atlas 약함 | SWE-bench Pro 최하위 | 벤치마크 폭 좁음 |
| 추천 용도 | 자율 코딩 에이전트 · 대규모 리팩터 | 웹 리서치 · 터미널 · 과학 QA | 문서 · 비디오 · 슬라이드 분석 | 수학 올림피아드 · 실시간 검색 |
| 출시 | 2026-04-16 | 2026-01 (5.4 업데이트) | 2026-03 | 2026-03 (4.20) |
새로 생긴 xhigh 모드와 Task Budgets, 실전 활용법
Opus 4.7에서 가장 실무적인 변화는 추론 강도 제어 레벨과 에이전트 예산 관리다. 둘 다 API Breaking Change를 동반하기 때문에 기존 4.6 코드를 그대로 붙여 넣으면 에러가 나는 구간이 있다.
xhigh effort 레벨은 언제 켜나
Opus 4.7은 Extended Thinking의 effort 레벨에 xhigh를 추가했다. 기존 low / medium / high / max에서 low / medium / high / xhigh / max 5단계가 됐다. Anthropic 문서 기준 권장 용도는 다음과 같다.
high— 대부분의 코딩·리팩터 상황에서 기본값xhigh— SWE-bench Pro급 장시간 추론이 필요한 자율 에이전트, 대형 PR 전체 리뷰max— 수학 올림피아드·논문 증명 같은 “시간 제한 없는 추론”
아래는 실제로 붙여 써도 되는 Python anthropic SDK 호출 코드다.
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=8000,
thinking={"type": "enabled", "effort": "xhigh"},
messages=[
{
"role": "user",
"content": "다음 레거시 모듈을 함수형 스타일로 리팩터하고, 실패 가능한 엣지 케이스에 대한 유닛 테스트도 함께 작성해라.",
}
],
)
print(message.content)thinking 파라미터는 enabled·disabled만 받는다. Extended Thinking의 기존 budget_tokens 파라미터는 Opus 4.7에서 완전히 제거됐고, Anthropic이 말하는 “Adaptive thinking only” 정책으로 바뀌었다. 즉 모델이 추론 길이를 스스로 조절한다.
Task Budgets(beta)로 에이전트 비용 통제
자율 에이전트를 돌리다 보면 “한 세션에 토큰을 얼마나 쓸지 상한을 걸고 싶다”는 요구가 생긴다. Anthropic은 Opus 4.7과 함께 Task Budgets beta를 공개했다 (출처: Claude Platform Docs). 최소 예산은 20,000 토큰이고, 헤더로 활성화한다.
curl https://api.anthropic.com/v1/messages \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: task-budgets-2026-03-13" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-7",
"max_tokens": 20000,
"metadata": {"task_budget": {"max_tokens": 50000}},
"messages": [
{"role": "user", "content": "레포 전체를 훑고 TypeScript 마이그레이션 계획을 작성해라."}
]
}'Task Budgets는 에이전트가 스스로 도구 호출·추론·응답을 반복하는 과정에서, 한 “태스크” 단위의 토큰 상한을 설정한다. 넘치면 조기 종료하고 부분 결과를 반환한다. 이는 “무한 루프로 $500 뽑아간 에이전트” 같은 사고를 막기 위한 안전장치에 가깝다.
Extended Thinking budget 제거와 Adaptive thinking
Opus 4.6에서 쓰던 thinking: {"type": "enabled", "budget_tokens": 32000} 패턴은 이제 에러를 반환한다. 대신 기본값은 “adaptive thinking ON·budget 없음”이고, 응답의 thinking 필드는 기본적으로 summarized(요약본)만 돌려준다. 원문 thinking은 별도 header flag를 켜지 않으면 접근할 수 없다. 로그에 민감한 추론 토큰이 노출되던 문제를 막기 위한 조치로 보인다. 이 변화 때문에 기존 4.6 프로덕션 코드는 최소 다음 3줄을 점검해야 한다.
temperature·top_p·top_k호출 → 제거하지 않으면 400 에러thinking.budget_tokens파라미터 → 제거thinking응답 파싱 →summarized를 파싱하도록 변경
Claude Code에서 이 흐름을 어떻게 자동화하는지는 Claude Code 완전 정복 쪽에 도구별 설정이 정리돼 있다.
3.75MP 비전과 파일시스템 메모리 — 에이전트가 실전에 들어온다
Opus 4.7은 “모델 성능”뿐 아니라 “도구·메모리·오피스 연동” 축에서도 덩치가 커졌다. 이 섹션은 에이전트를 실전에 붙일 때 의미 있는 기능 3가지를 짚는다.
2576px 고해상도 비전이 여는 것들
Opus 4.6까지 이미지 입력은 최대 1568px(약 1.15MP) 선이었다. Opus 4.7은 2576px × 2576px, 약 3.75MP까지 직접 받는다 (출처: Claude Platform Docs). 해상도가 3.3배 늘어난 덕분에, 대시보드 전체 스크린샷·PCB 사진·CAD 도면처럼 세부가 중요한 이미지를 리사이즈 없이 넣을 수 있다. CharXiv Reasoning(tools)에서 91%, OfficeQA Pro에서 80.6%를 찍은 배경에도 이 해상도 상향이 있다.
파일시스템 기반 멀티세션 메모리
Anthropic은 “파일시스템 메모리”라는 개념을 도입했다. 에이전트가 대화 상태를 파일로 저장·로드해서 세션 간 연속성을 확보하는 구조다. 예컨대 월요일에 돌린 리팩터 에이전트가 .claude/state/session-xyz.json에 진행 상황을 저장해 두면, 수요일에 이어서 시작할 때 “지난번 분석 상태를 불러온다”고 지시할 수 있다. Simon Willison은 자신의 블로그에서 “Opus 4.7이 /memories/ 경로를 실제 파일처럼 취급하는 패턴”을 상세히 분석했다 (출처: Simon Willison).
Claude in PowerPoint, Claude Design + Canva
Anthropic은 Opus 4.7 공개와 동시에 Claude in PowerPoint 연동을 공개해서, Microsoft 365 유저가 슬라이드 안에서 Opus 4.7을 부를 수 있게 했다. 같은 주에 Canva와의 Claude Design 파트너십도 열렸다 (출처: The Next Web). 둘 다 “Chat UI 밖에서 쓰는 Opus 4.7” 흐름의 일부로, Office·디자인 툴 이용자에게 AI 어시스턴트를 바로 꽂는 포지션 싸움이 Anthropic 측에서 강화됐다.
Opus 4.7은 도구 호출이 끝난 뒤 결과를 사용자에게 반환하기 전, 모델 자체적으로 “sanity check” 한 번을 더 돌린다. Anthropic은 이를 self-verification이라고 부른다. 코드 생성 후 즉시 실행 결과를 반추해서 명백한 오류를 고치는 패턴이 Opus 4.6 대비 체감상 크게 늘었다. 특히 JSON schema 위반·함수 시그니처 불일치 같은 정적 오류는 거의 자가 교정된다.
실측으로 드러난 한계와 회귀 — MRCR 46pt 폭락까지
출시 3일이 지나면서 “4.7은 마냥 좋아지기만 했다”는 서사는 금이 가기 시작했다. 특히 MRCR과 NYT Connections에서 큰 폭 회귀가 보고됐고, 창작·감정 지원에서도 품질 하락 리포트가 나왔다. 이 섹션은 의도적으로 비판적인 각도에서 본다.
MRCR 78.3% → 32.2% — 긴 문서 검색은 퇴보
MRCR(Multi-needle Retrieval Context Recall, 긴 문서에서 여러 개의 “바늘”을 찾는 벤치마크)에서 Opus 4.7은 32.2% 점수를 기록했다. 4.6이 78.3%였으니 무려 46포인트 하락이다 (출처: RoboRhythms). 1M 컨텍스트에 문서를 우겨 넣고 “특정 고객이 2023년 3월에 요청한 항목을 찾아라”처럼 핀포인트 검색을 돌리는 작업에서는 Opus 4.7이 오히려 4.6보다 뒤처진다.
NYT Connections(단어 4개씩 4그룹으로 묶는 추론 퍼즐) 점수도 94.7%에서 41%로 주저앉았다. 언어 감각·패턴 매칭이 필요한 생활 언어 문제에서 Opus 4.7이 뚜렷한 퇴보를 보였다.
“1M 컨텍스트에 대량 문서 넣고 정확한 인용 뽑기” 작업을 해본 적 있는가? 이 용도에서 Opus 4.7은 현재 4.6보다 확실히 약하다. 당장 4.6 모델 ID(claude-opus-4-6)를 바로 끊지 말고, 긴 문서 리서치 전용 파이프라인은 4.6으로, 코딩 에이전트는 4.7로 갈라서 돌리는 구성이 현실적이다.
창작 글쓰기와 감정 지원에서 밋밋해졌다
Reddit r/OpenAI에는 “Opus 4.7은 감정 지원에서 접수 치료사처럼 딱딱하다”, “창작에서 4.6보다 상상력이 떨어진다”는 의견이 올라왔다. Anthropic은 안전성 보강과 hallucination 감소를 위해 창작·감정 축에서 “사실 검증 가중치”를 올린 것으로 추정된다. 결과적으로 소설·카피·상담성 대화에서는 4.6이 더 자연스럽다는 리포트가 우세하다.
속도·첫 토큰 레이턴시에서 뒤처진다
Artificial Analysis 측정 기준, Opus 4.7의 첫 토큰 레이턴시(TTFT)는 3.8초로 GPT-5.4의 1.9초보다 2배가량 느리다 (출처: Artificial Analysis). 초당 토큰 생성 속도는 52토큰/s로, Sonnet 4.6의 110토큰/s 대비 절반 수준이다. 실시간 챗봇 UX에서는 체감상 “생각이 길다”로 느껴질 수밖에 없다.
커뮤니티 반응 — 극과 극으로 갈렸다
Reddit·Hacker News·엔지니어 블로그에서 Opus 4.7 반응은 극명하게 갈렸다. “코딩 에이전트 혁명”과 “조용한 가격 인상” 두 서사가 동시에 돌았다.
긍정: “23파트 분할 + 일관된 유닛 테스트”
긍정 쪽은 코딩 에이전트 사용자에서 특히 강하다. 장시간 자율 실행, 컨텍스트 유지, 파일 분할 리팩터에서 Opus 4.6과 체감 격차가 크다는 평이 많다.
부정: “토큰 쿼터가 몇 시간 → 몇 분으로 소진”
부정 쪽은 비용·쿼터·창작 영역에서 몰렸다. 특히 Claude Max 구독자들이 “토큰 쿼터가 Opus 4.6 시절 몇 시간 돌아가던 게 4.7 전환 후 몇 분이면 바닥난다”고 토로한다.
- "Opus 4.7이 모놀리식 모듈을 23개 파트로 스스로 분할하고, 유닛 테스트를 일관되게 돌렸다. 버그가 거의 없었다." — r/OpenAI
- "UI 목업에서 Opus 4.7이 waaay better. 디테일 집중도가 다르다." — r/ArtificialIntelligence
- "275K 토큰까지 성능 유지. 4.6는 200K 근처에서 이미 무너지는 게 느껴진다." — Hacker News 스레드
- "autonomous, long-session coding, multi-file refactor에 최적이다." — Cursor 공식 모델 문서
- "토크나이저 변경은 숨겨진 가격 인상이다. 4.6과 같은 프롬프트에 청구서가 28% 더 나왔다." — r/ClaudeCode
- "세션 쿼터가 몇 시간에서 몇 분 만에 소진된다. Max 구독의 의미가 흐려졌다." — r/ClaudeAI
- "감정 지원에서 접수 치료사처럼 딱딱하다. 4.6 시절 자연스러움이 사라졌다." — r/OpenAI
- "복잡한 엔지니어링 태스크에서 퇴보했다. 내부 평가에서 4.6이 더 안정적이었다." — AMD 시니어 디렉터 공개 비판
Simon Willison·Cursor·HN 반응
개발자 중립 진영에서는 Simon Willison이 “Opus 4.7 시스템 프롬프트에서 /memories/를 실제 파일로 취급하는 패턴이 새롭다”며 MCP 에이전트 구현자 입장에서 긍정적 신호로 읽었다 (출처: Simon Willison). Cursor는 Opus 4.7을 기본 추천 코딩 모델로 올렸고, Hacker News 메인 스레드는 출시 당일 800+ 코멘트로 전체 1위에 올랐다 (출처: Hacker News).
Claude Opus 4.7은 누가 써야 할까
이 시점에서 결정을 내려야 한다. Opus 4.7의 장단점을 페르소나별로 정리한다.
장점
- + SWE-bench Pro 64.3% 등 자율 코딩 에이전트 최고 점수
- + OSWorld 78%, MCP-Atlas 77.3%로 컴퓨터 사용·도구 호출 강세
- + xhigh 모드·Task Budgets로 추론 강도·비용 제어 세밀화
- + 2576px 비전·1M 컨텍스트·128K 출력의 대형 워크로드 친화
- + ASL-3 안전 등급 유지 + 사내 컴플라이언스 대응 자료 풍부
단점
- − 신규 토크나이저로 같은 텍스트 기준 실효 비용 1.0~1.35배 상승
- − MRCR 78.3%→32.2%, NYT Connections 94.7%→41% 등 롱컨텍스트 검색·생활 추론 회귀
- − BrowseComp 4.6 대비 소폭 하락 — 단일 세션 웹 리서치 약함
- − TTFT 3.8초·초당 52토큰으로 실시간 UX에서 느림
- − 창작·감정 지원에서 4.6 대비 밋밋하다는 사용자 리포트
추천: 자율 코딩 에이전트·대규모 리팩터·컴퓨터 사용 자동화
- 사내 코드베이스 전면 리팩터 — 마이크로서비스 분할, 타입 마이그레이션, 테스트 생성
- 자율 에이전트 CI — PR 자동 리뷰·머지·테스트 추가
- RPA 대체 — OSWorld 벤치마크 수준의 마우스/키보드 자동화
- MCP 도구 체인 — 사내 툴 20개 이상 연결된 복합 에이전트
비추천: 웹 리서치 중심·창작 글쓰기·비용 민감 단순 챗봇
- 딥 리서치 — BrowseComp는 GPT-5.4가 유리
- 긴 문서 핀포인트 인용 — MRCR 회귀로 Opus 4.6이 여전히 우위
- 감정 지원·카피라이팅·소설 — 4.6 유지 또는 GPT-5.4
- 비용 민감 챗봇 — Sonnet 4.6 또는 Haiku 4.5가 훨씬 경제적
Pro/Max 구독 vs API 직접 사용
개인 유저라면 Claude Pro($20/월) 또는 Max($100/월) 구독이 토큰 쿼터 기준 합리적이지만, Opus 4.7 전환 후 쿼터 소진 속도가 체감상 빨라졌다. API 직접 사용 시에는 Batch API 50% 할인과 프롬프트 캐시 90% 할인을 기본 루틴에 박아 두는 쪽이 월 비용을 크게 낮춘다. 팀 규모가 커지면 AWS Bedrock이나 Vertex AI 경유가 회계·컴플라이언스 면에서 편하다. IDE 단 자동화는 Claude Code 완전 정복에 정리된 CLI 흐름을 결합하면 시간당 토큰 비용이 20–30%까지 줄어든다.
결론 — 잠정 왕좌, 미토스를 기다리며
핵심 요약
Claude Opus 4.7은 코딩 에이전트·컴퓨터 사용·MCP 도구 호출 축에서 현시점 최고 점수를 가져간 프론티어 모델이다. 가격표는 그대로지만 토크나이저 교체로 실효 비용이 10–35% 올랐고, MRCR·NYT Connections 같은 일부 축에서는 이전 세대보다 뒤로 후퇴했다. “코딩 에이전트 전용 모델”이라는 관점에서 도입하면 손해 볼 일이 적고, 웹 리서치·창작은 GPT-5.4·Gemini 3.1 Pro와 역할을 나누는 편이 맞다.
- 사내 레거시 코드베이스를 자율 에이전트로 리팩터하려는 개발팀
- 20개 이상의 MCP 도구를 엮어 장시간 에이전트를 돌리는 AI 엔지니어
- 대시보드·CAD 도면 같은 고해상도 이미지 기반 자동화를 설계하는 PM
- Claude Code·Cursor·Copilot 중 코딩 품질을 타협하지 않겠다는 개인 개발자
반대로 웹 리서치·감정 지원·소설 집필 중심이라면, Opus 4.6을 당분간 유지하거나 GPT-5.4·Gemini 3.1 Pro로 갈라 쓰는 편이 낫다.
API 코드에서 deprecated 파라미터 제거
temperature·top_p·top_k·thinking.budget_tokens 4개 파라미터를 모두 삭제한다. 없으면 400 에러로 프로덕션이 멈춘다. 샘플 요청 10건 정도 돌려서 응답 구조가 정상인지 확인한다.
샘플 500건으로 토큰 증가율 실측
기존 4.6 프롬프트를 4.7 모델 ID로 바꿔 500~1,000건 돌린 뒤, 같은 입력의 토큰 수가 몇 배인지 계산한다. 1.25배가 넘으면 프롬프트 캐시와 Batch API를 기본값으로 돌리고 예산 알람 상한을 즉시 올린다.
코딩 전용·리서치 전용 파이프라인 분리
코딩 에이전트는 Opus 4.7과 xhigh 모드로, 긴 문서 리서치는 Opus 4.6 또는 GPT-5.4로 라우팅하는 분리형 구성을 만든다. 팀 내 Slack 알림이나 내부 문서에 용도별 모델 선택 가이드를 공지해서 혼선을 줄인다.
- Anthropic 공식 발표 — Introducing Claude Opus 4.7
- Claude Platform Docs — What’s new in Claude 4.7
- The Next Web — Anthropic Claude Opus 4.7 Agentic Benchmarks
- Vellum AI — Claude Opus 4.7 Benchmarks Explained
- Finout — The Real Cost Story Behind the Unchanged Price Tag
- Artificial Analysis — Claude Opus 4.7 Profile
- Help Net Security — Claude Opus 4.7 Released
- RoboRhythms — Opus 4.7 Regression Backlash
- Simon Willison — Opus 4.7 System Prompt Analysis
- Decrypt — Claude Opus 4.7 Review: Benchmarks & Coding Test
- Cursor Docs — claude-opus-4-7 model
- Hacker News — Opus 4.7 Launch Thread
Claude Opus 4.7 모델 ID는?
Opus 4.6에서 그대로 쓰던 프롬프트를 4.7에 넣어도 되나?
1M 컨텍스트가 GPT-5.4보다 유리한 점은?
xhigh 모드는 언제 써야 하나?
Claude Code 안에서 Opus 4.7을 어떻게 쓰나?
토큰 1.35배 이슈는 어떻게 완화하나?
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.

Claude Opus 4.8 총정리 - 벤치마크·가격·ultracode 해석 (2026)
Claude Opus 4.8의 출시일, 벤치마크, 가격, fast mode, ultracode와 dynamic workflows를 2026년 5월 기준으로 정리했다.
읽기
Gemini 3.5 Flash 총정리: 가격·벤치마크·해외 반응
Gemini 3.5 Flash의 공식 스펙, 가격, 벤치마크, API 변경점과 해외 Reddit·Hacker News 반응을 정리한다.
읽기
클로드 코드 가격·한도 총정리: Pro·Max·Codex 비교
클로드 코드 가격과 한도를 2026년 5월 기준 공식 문서로 정리했다. Pro, Max, Codex 차이와 주의점을 중립적으로 비교한다.
읽기