Andrej Karpathy's 4 AI Coding Warnings and the 100K-Star CLAUDE.md Repo
A deep dive into the four bad AI coding habits Karpathy warned about, the CLAUDE.md repo's four operating principles, what evidence supports them, and where the limits still are.

Quick take
Start with this judgment
19 min readBottom line
A deep dive into the four bad AI coding habits Karpathy warned about, the CLAUDE.md repo's four operating principles, what evidence supports them, and where the limits still are.
- Best for
- Readers comparing cost, capability, and real limits before choosing a tool
- What to check
- CLAUDE.md · Claude Code · AI coding agents
- Watch out
- Pricing and features can change, so confirm with the official source too.
3 key points
forrestchang/andrej-karpathy-skillsis a repository where code of conduct is more important than executable code. Even though it is a 20KB markdown bundle, it has collected 105,196 GitHub stars as of May 2, 2026 (Source: GitHub).- The essence is not “Secret prompts to make Claude smarter”, but is closer to a behavioral patch that suppresses four typical mistakes made by AI coding agents with a short rule file.
- However, it is difficult to say that code quality will automatically improve with just this repository. Looking at external benchmarks and recent research together, the strongest value is not in added creativity, but in guardrails that reduce over-engineering and arbitrary modification habits.
목차
- 1. Why are conventions more important than code in this repository?
- 2. What exactly do the four principles prevent?
- 3. How are CLAUDE.md, SKILL, and Cursor rules distributed differently?
- 4. Why did you collect 100,000 stars so quickly?
- 5. Is there any evidence that it really improves coding quality?
- 6. What is still lacking compared to the main branch?
- 7. Who can copy and write now?
- 8. How can Korean developers mix and apply?
- 9. Frequently Asked Questions
- 10. Conclusion: Is this repo worth adopting?
To summarize this repository in one sentence: This is a repo that most concisely shows that the bottleneck in AI coding has now shifted from model performance to behavior control. If you are already using tools such as Claude Code, Cursor, or Codex, but the results are constantly exaggerated or even the surrounding code is broken, you need to understand why this repo is popping up.
1. Why are conventions more important than code in this repository?
To conclude, andrej-karpathy-skills is not software that adds functionality, but an operating rule that corrects the agent’s bad habits. The repository root contains README, CLAUDE.md, CURSOR.md, EXAMPLES.md, plug-in metadata, and only one SKILL.md. The repository size based on GitHub API is only 20KB (Source: GitHub API).
Why is this format working now?
The most common failures of AI coding agents are “Don’t say you don’t know what you don’t know” and “Doing more than asked”. This repo targets that failure with a very short rule. It takes the problem pointed out by Karpathy and asks us to expose the assumptions first, solve simply, keep the surrounding code untouched, and turn it into a verifiable goal (Source: README).
This is not a prompt tip, but a control layer.
So, if you just read this repo as “How to write Claude Code well”, you only understand half of it. A more accurate interpretation is the control layer that manages versioning of prompts like code. This perspective is in line with the harness concept discussed in [AI apps are completed with harnesses, not prompts] (/en/ai/harness-engineering-ai-apps). This means that the results are stable only when rules, execution paths, and verification loops are placed on top of the model.
The reason it exploded even though it was a document-type repo
What’s interesting is that this repository got a stronger response for “instructions for doing something less” than for “code that causes something to run”. As of May 2, 2026, it recorded 105,196 stars, 10,413 forks, and 560 watchers, which are figures similar to those of a large framework (Source: GitHub, GitHub API). It would be more accurate to read this as a market signal that behavioral inhibition is a more urgent problem than grammar generation.
This article goes one step further than “Copy and paste it.” Let’s take a look at why this repo worked, what is actually distributed, how much is grounded, and where it can be exaggerated.
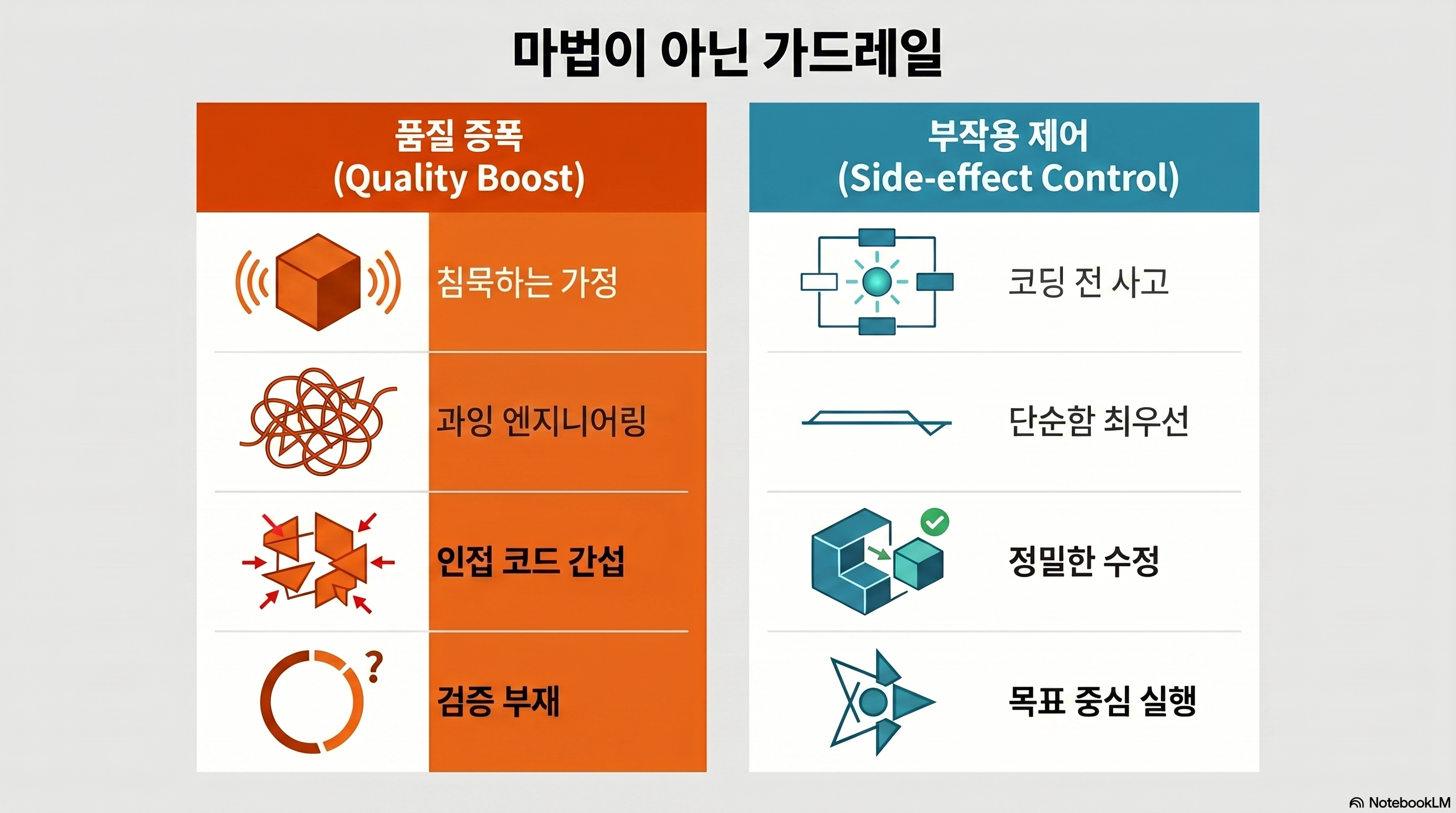
2. What exactly do the four principles prevent?
At the core of the repository are four principles: In the long run, it seems ordinary, but in reality, it accurately captures the typical thinking types of AI coding agents.
Think Before Coding Prevents Silent Misunderstandings
The first principle calls for revealing assumptions and interpretations before implementation. This means that when receiving a request such as “Add export function”, AI should not arbitrarily assume the file format, data range, and whether sensitive information is included. This part is most convincingly revealed in EXAMPLES.md. An incorrect example involves immediate CSV/JSON export, and a correct example asks about scope and privacy first (Source: EXAMPLES.md).
Simplicity First Prevents Over-Engineering
The second principle prohibits over-design, such as taking out Strategy Pattern and configuration objects when asked to create a single discount function. This is more practical than a higher-level tooltip like Mastering Claude’s Code (/en/ai/claude-code-review). This is because the model too easily mistakes “Complexity that Looks Like Good Design” as the correct answer.
Surgical Changes is the real killer feature of this repo
The third principle dictates that you do not touch unsolicited code, comments, formatting, or adjacent logic. Personally, I believe that almost all of the explosive power of this repository lies in this. Recent research supports a similar direction. An April 2026 arXiv paper reported that while rules files can be helpful overall, the only type of individual rule that was clearly beneficial was a negative constraint in the form of “Don’t do it”, and positive directives could actually harm performance (Source: Do Agent Rules Shape or Distort?).
Goal-Driven Execution Makes Work Verifiable
The fourth principle is the habit of translating “please fix the bug” into “Create a test that fails and then make it pass.” This is not a device to increase the creativity of the model, but a device to delay the point at which it is mistaken as being finished. It is especially effective in long-term work.
| principle | failure to prevent | good effect | Dangers of excessive use |
|---|---|---|---|
| Think Before Coding | Silent assumption, wrong implementation | Increased question quality, stabilized scope | Even minor tasks can be extremely slow |
| Simplicity First | Over-engineering, unnecessary abstraction | Reduce diffs, reduce review burden | Rework is possible if you ignore all long-term scalability |
| Surgical Changes | Peripheral cord damage, drive-by refactor | Risk decreases rapidly, PR clarity increases | If you are too conservative, you may miss the broad corrections needed. |
| Goal-Driven Execution | Declaration of termination without verification | Strengthening the test/verification loop | Even simple requests can turn into heavy procedures. |
(Source: README, EXAMPLES.md, arXiv 2604.11088)
3. How are CLAUDE.md, SKILL, and Cursor rules distributed differently?
If you look at this repo shallowly you’ll see “Didn’t they just post CLAUDE.md?” look like. However, in reality, it is a repository that packages the same principle into various execution aspects. That is the core of adoption.
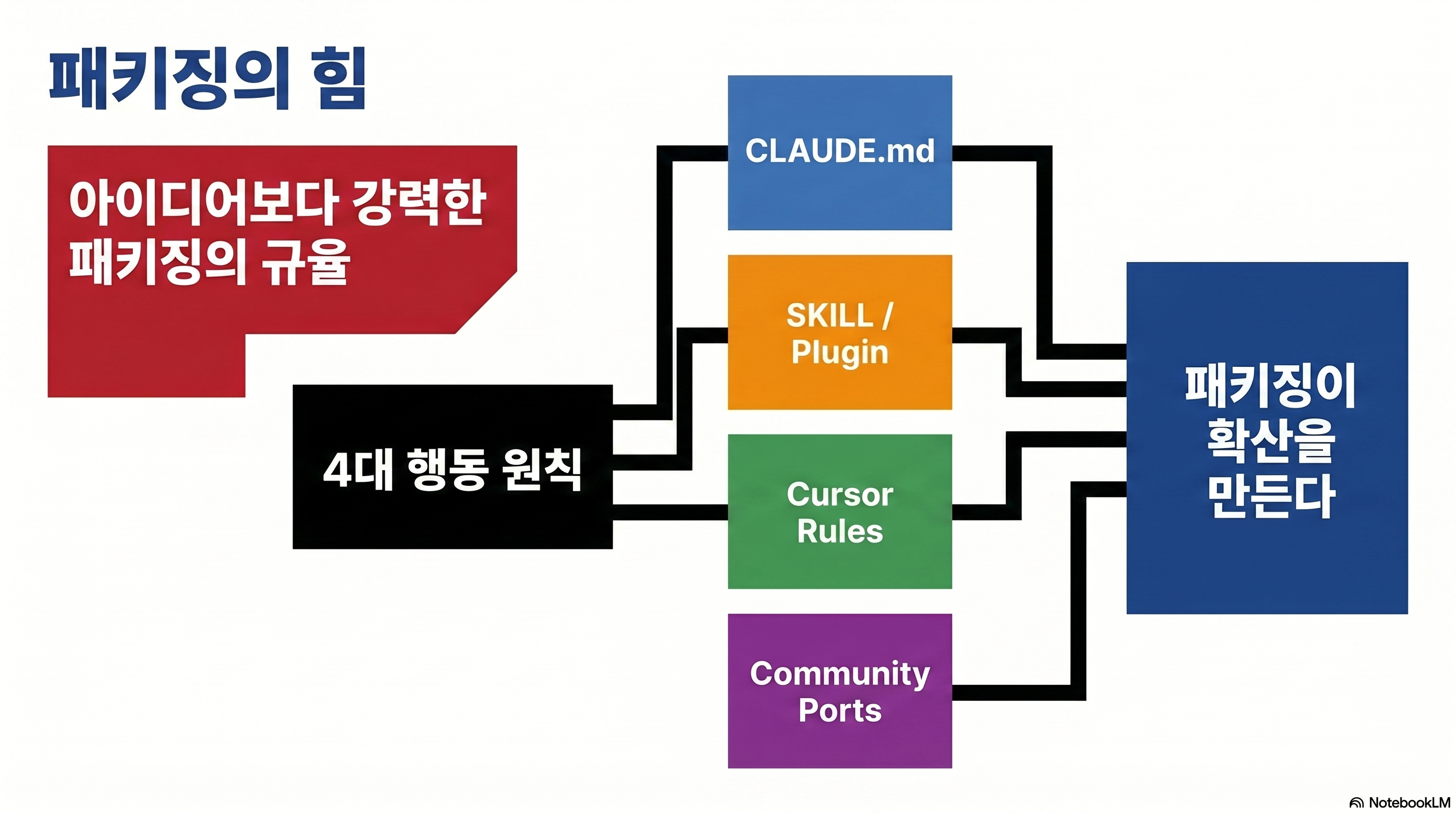
If it is a project unit, it is CLAUDE.md.
The root CLAUDE.md is close to the Claude Code project rule card. The README even explains how to download and use raw files for new projects and append them to existing projects (Source: README).
To reuse, use SKILL.md and plugin metadata.
skills/karpathy-guidelines/SKILL.md and .claude-plugin/plugin.json turn the same rules into reusable skills. Anthropic’s official documentation also explains that SKILL.md is a reuse unit of Claude Code, and plug-in skills operate in a separate namespace (Source: Claude Code Skills Docs).
For Cursor users, .cursor/rules is the key
CURSOR.md in this repository clearly divides the application path on the Cursor side. Since Cursor does not read .claude-plugin/ or CLAUDE.md by default, it is standard to copy .cursor/rules/karpathy-guidelines.mdc. This rule file is automatically applied because there is alwaysApply: true in frontmatter (Source: CURSOR.md, Cursor rule file, Cursor Docs).
Codex is still closer to a community port than the mainline.
There is one important twist here. Currently, there is no Codex-specific metadata in the main branch. Instead, PRs like Add Codex skill metadata and docs were opened, and on May 1, 2026, Codex skill edition PR was also uploaded (Source: PR #104, PR #120). That is, this repo is already being consumed as a universal code of conduct, but cross-agent production is still in progress.
| surface | applied area | Installation method | Who should use it? |
|---|---|---|---|
| CLAUDE.md | single project | Copy to root or merge into existing file | Team that handles Claude Code by project |
| SKILL.md | reusable skill | Register in personal/plugin skill path | Users who will apply the same rules repeatedly to multiple projects |
| .claude-plugin | Claude plugin ecosystem | Installation via plugin market | Claude users who want an installable reusable experience |
| .cursor/rules | Cursor project rules | Copy rule file to project | Users who need rules that always apply in Cursor |
| Community Codex port | Codex/Other Agents | Use PR or separate port | Users who want to use the same doctrine outside of Claude/Cursor |
(Source: README, Claude Code Skills Docs, Cursor Docs)
4. Why did you collect 100,000 stars so quickly?
The point is not a new feature, but the pain that everyone was already experiencing was summarized in very precise language.
The timing was correct.
This repo was created on January 27, 2026, and had 105,196 stars as of May 2, 2026. This is an abnormally fast spread for a document-type repo in about three months (Source: GitHub API). This period coincides exactly with the period when the use of Claude Code, Cursor, and Codex-based agents began in earnest, and complaints accumulated about “AI works quickly, but it keeps getting sidetracked.”
It was short and easy to spread.
CLAUDE.md has 65 lines, SKILL.md has 67 lines, and README has 171 lines. Because it is not a complicated product but a copyable doctrine, users can apply it before understanding it. It is similar to the file-over-app philosophy discussed in Karpathy LLM Wiki Concepts. Instead of installing code, it uses text as a control layer that can be versioned.
The installation path was separated by tool.
Many guide repos have good ideas, but get stuck at “So where should I put it?” This repository reduces friction by separating README, CURSOR.md, plugin metadata, and SKILL.md. It is more reasonable to say that packaging pushed adoption rather than the idea.
However, product maturity is still low
Interestingly, as of the GitHub page, there are no public releases, and the number of main branch commits is only 28 (Source: GitHub). In other words, strictly speaking, this is closer to “Operating principles spread explosively” than to “Highly complete product.” If you miss this difference, it is easy to overestimate.
5. Is there any evidence that it really improves coding quality?
From here on, you have to be cool. This repo itself has no A/B testing or eval harness. So we have to look at external evidence.
The best data is ‘Efficiency increases, but quality is not guaranteed’
The external experiment in which Augment Code ran three types of agents on 40 OpenClaw PRs was quite interesting. Adding Karpathy style rules to AGENTS.md reduced the average cost and turnaround time for both Claude Code and Codex. For example, Claude Code improved by -10% in cost and -7% in time, and Codex improved by -8% in cost and -7% in time (Source: Augment Code OpenClaw benchmark).
But the quality score did not automatically increase
In the same experiment, there was little change in code quality for Auggie and Codex, and there was a slight decline in Claude Code. The article also interprets the reason as “Adding additional constraints to an agent that already has strong system prompts can reduce exploration breadth.” (Source: Augment Code OpenClaw benchmark). This is an important point. This repo is more of a trajectory regularizer than a performance booster.
Recent research shows that ‘don’t do it’ is particularly strong
The previously mentioned arXiv 2604.11088 showed that the rule file showed an overall performance improvement of 7 to 14 points, but there were cases where random rules were as helpful as expert rules, and among individual rule types, only negative constraint was clearly beneficial (Source: Do Agent Rules Shape or Distort?). From this perspective, Surgical Changes may not be the emotional point of this repo but may actually be the most generalizable part.
| Measuring Items | Claude Code | Codex | analysis |
|---|---|---|---|
| time taken | -7% | -7% | Chances of reaching the same answer in less time |
| expense | -10% | -8% | Reduce unnecessary navigation |
| Tool call | decrease | decrease | Less sideways leaks |
| quality score | slight decline | almost the same | The Dangers of Overconfidence in Quality Assurance Tools |
(Source: Augment Code OpenClaw benchmark, arXiv 2604.11088)
6. What is still lacking compared to the main branch?
It’s a good repo, but it’s clearly too empty to trust and use as a product.
First, the license signal is not clear.
MIT is written in README, plugin.json, and SKILL.md. However, the license field of the GitHub API confirmed on May 2, 2026 is null, and there is no LICENSE file in the root contents (Source: GitHub API, plugin.json). It is not something to immediately conclude that it is dangerous, but it is correct to view it as legal clarity is less clear from a corporate introduction perspective.
Second, there are no releases and changelogs
As of the GitHub page, there are no public releases. In other words, “At what point will you use which version as the team standard?” is ambiguous (Source: GitHub). Currently, the method is to view the latest main, so reproducibility is weak.
Third, cross-agent support was not brought to the mainline as expected.
It is true that Codex-related PR is active, but that in itself does not mean native support of the main branch. The expansion into OpenClaw, OpenCode, Codex, etc. is evidence of community demand, not evidence of product completeness. If you have seen the multi-agent world like Oh My OpenAgent Honest Review, this difference will seem more important.
Fourth, there is no self-eval to prove the effect
The fact that explanations can only be made by bringing in external benchmarks and papers is not an advantage, but a gap. For this repo to go to the next level, it needs to at least show inside the repository “Which families of tasks get better and which ones get slower with this rule on and off?”
If you expect your agent to become smarter by attaching this repo, you may be disappointed. A more accurate expectation is “The frequency of accidental breakdowns decreases.”
7. Who can copy and write now?
It is not the right answer for all teams. There is a clear difference between teams that fit well with this repo and teams that are ambiguous.

The team that is doing well is the team that suffers from ‘overcorrection’
If you are asked to fix a bug and it is common for things like import cleanup, comment modification, type hint addition, and style unification to come together, there is a high chance that you will see the effect right away. It is especially well suited to teams where PR review costs have increased, and teams where AI has polluted diffs and human reviewers have become tired.
The less suitable team is a light task-oriented team.
If there are mostly minor typos, one-line wording changes, and very obvious renamings, the caution of this repo can actually be an overhead. The creator himself wrote in the README to use judgment for trivial tasks (Source: README).
In the long run, it is better to use behavioral floor.
The most realistic usage is not to mistake this repo for all of the team’s rules. It is convenient to think of it as below.
Pros
- + Good for reducing the frequency with which AI makes modifications beyond the scope of requests.
- + It is good to use as a behavioral floor underneath the rules for each project.
- + It is easy to unify the concept even in teams that go back and forth between Claude and Cursor.
Cons
- − Since there is no benchmark of its own, the storage itself cannot prove its effectiveness.
- − Being overly strict can reduce exploration power in already conservative agents.
- − Support for other tools such as Codex still has a stronger community PR nature than the mainline.
Judgment criteria that are particularly important to Korean readers
Korean teams are more sensitive to “small reviewable diff” than global teams. This is because making changes that can be explained later is as important as making them quickly. In that culture, this repo fits quite well. On the other hand, if “Anyway, throwaway prototype” is used in most cases, there is no need to use it strictly.
8. How can Korean developers mix and apply?
The key is not to worship the entire text, but to keep the doctrine as one while keeping the surfaces of each tool different.**
If it is a Claude Code project, merge it into CLAUDE.md
The simplest way is to put the principle of this repo as a behavioral floor at the bottom of the project root CLAUDE.md. You can write project-specific rules above or below it. Anthropic’s official documentation also explains skills/manifests by separating project knowledge and procedures (Source: Claude Code Skills Docs).
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.mdIf you’re a Cursor team, it’s better to put it in .cursor/rules
Cursor officially supports Project Rules and AGENTS.md, and indicates that .cursor/rules is a versioned rule path (Source: Cursor Docs). Therefore, it is more natural for a cursor-oriented team to set .cursor/rules/karpathy-guidelines.mdc as a reference point rather than forcefully insert CLAUDE.md.
mkdir -p .cursor/rules
curl -o .cursor/rules/karpathy-guidelines.mdc https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/.cursor/rules/karpathy-guidelines.mdcCodex or other agents import only the principles and localize the format
There is no need to imitate the Claude format in other agents, including Codex. It is better to keep only the doctrine of Think Before Coding, Simplicity First, Surgical Changes, and Goal-Driven Execution and translate it into the settings page read by each tool. This approach is also in line with the principle of “The control plane is the same, but the runtime can be different,” mentioned in [AI apps are completed with harnesses, not prompts] (/en/ai/harness-engineering-ai-apps).
The best introduction sequence is not to apply it all at once.
Instead of just inserting a single file and calling it a day, it is better to first compare the diff size and number of retries for one type of noisy task. For example, the effect is quickly apparent in task groups such as “Add form validation”, “insert logging”, and “stale refactor recovery”.
9. Frequently Asked Questions
Does AI coding quality immediately improve with just one CLAUDE.md file?
I am a Cursor user. Do I need to install a plugin?
Is it officially supported by Codex?
Doesn't this conflict with existing project rules?
Should we always apply this to even trivial tasks?
What are the strongest principles of this repo?
10. Conclusion: Is this repo worth adopting?
There is value. However, you need to know exactly why. This repo doesn’t make Claude a genius. Instead, it provides a minimum code of conduct that makes AI coding agents less dangerous companions. And the regulations have been well packaged in a format that can be extended to Claude plugin, SKILL, Cursor rule, and future Codex ports.
one line conclusion
andrej-karpathy-skills is not an all-purpose prompt, but a behavioral floor. What we need now may be rules that make us behave less arbitrarily, rather than more flashy instructions.
It has high value if the AI tampers with surrounding code, small reviewable diffs are important, and you want to unify the same tool habits by going back and forth between Claude and Cursor. Conversely, if the focus is on throwaway prototypes, it may be an excessive procedure.
Choose just one tool
For Claude Code, it starts from CLAUDE.md, and for Cursor, it starts from .cursor/rules. Do not spread to all tools at the same time from the beginning.
Merge with project rules
These four principles are set as the behavioral floor, and test commands or directory prohibition rules are attached separately according to the project context.
Compare before and after in one work group
Check the actual effect by comparing the diff size, number of retries, and review time in noisy tasks such as adding validation, inserting logging, or fixing small bugs.
Was this helpful?
One tap shapes what gets written next.
Topic tags

Oh My OpenAgent Review: A Multi-Agent Alternative to Claude Code (2026)
An honest one-month review of OpenCode + Oh My OpenAgent, covering ultrawork, agent roles, pricing, failure modes, and whether it is ready to replace Claude Code.
Read
GPT-5.5 Review: Benchmarks, Pricing, Codex Impact, and Early Reactions (2026)
What changed in GPT-5.5, where it leads on agent benchmarks, why pricing looks 2x higher, and how Codex users should think about upgrading as of April 2026.
Read
GLM 5.1 Review: Run Claude Code at 1/5 the Price with Open-Weight SOTA
How to run GLM 5.1 in Claude Code at one-fifth the cost, plus what Z.AI's official docs reveal about subscription-backed API access, Vision MCP, and GLM-Image.
Read