AI Apps Are Built with Harnesses, Not Prompts
A practical guide to harness engineering: context, tools, evals, observability, CI gates, and security for production AI apps.

Quick take
Start with this judgment
25 min readBottom line
A practical guide to harness engineering: context, tools, evals, observability, CI gates, and security for production AI apps.
- Best for
- Readers comparing cost, capability, and real limits before choosing a tool
- What to check
- Harness Engineering · LLM Evaluation · AI Agents
- Watch out
- Pricing and features can change, so confirm with the official source too.
3 Takeaways
- Harness engineering is not prettier prompting. It is the design of context, tools, memory, evals, observability, permissions, and feedback loops around an AI model.
- The model is the engine. The harness is the product system that turns raw capability into repeatable behavior, measurable quality, and controlled risk.
- The smallest useful harness starts with a golden set, deterministic checks, LLM-as-judge scoring, traces, and a CI gate that blocks regressions before deployment.
Contents
- What exactly is harness engineering?
- Why don't AI apps become products with prompts alone?
- How are prompt, context, and harness engineering different?
- What layers make a good harness?
- How do you test an LLM that changes its answer every time?
- What should you evaluate separately for RAG and agents?
- Which tools should you choose first?
- Where do screenshots and infographics help most?
- Where should security and privacy controls live?
- How do you raise harness maturity?
- What is the smallest harness you can build today?
- What should you trust, and what should you keep questioning?
- Frequently asked questions
- Conclusion: where does AI product quality actually come from?
Here is the short version: the quality of an AI product is no longer determined only by which model you picked. It is determined by the harness you put around that model.
Prompts still matter. A strong prompt can improve tone, task framing, and output format. But a prompt cannot give you regression testing, permission boundaries, trace replay, cost budgets, RAG diagnostics, rollout gates, or a way to convert production failures into future tests.
That is why harness engineering matters. It is the discipline of building the execution environment around the model so the system can be tested, observed, deployed, and improved like a real product.
This is not an OpenAI-only idea. OpenAI’s Codex post made the phrase more visible, but the underlying pattern is broader: Anthropic describes tool design and trajectory observation in multi-agent systems, LangSmith and Langfuse treat evaluation and traces as production loops, and Braintrust frames datasets, scorers, CI, and monitoring as one evaluation workflow (source: OpenAI Harness Engineering, Anthropic Engineering, LangSmith Evaluation Concepts, Langfuse Evaluation Overview, Braintrust LLM Evaluation Guide).
Harness engineering is not a formal industry standard with one canonical definition yet, and it should not be treated as a vendor slogan. In this post, it means a practical operating frame: prompts, context, tools, evaluation, CI, observability, security, and human review treated as one product-quality system.
What exactly is harness engineering?
Harness engineering is the design of the execution structure around an AI model. The harness decides what the model can read, which tools it can call, which memories it can retrieve, which outputs are acceptable, how failures are logged, and how those failures become future tests.
The harness is product design outside the model
In traditional software, a test harness runs code under controlled conditions with fixtures, drivers, mocks, and assertions. In AI software, the harness becomes larger because the model is probabilistic and often acts through external tools.
Think of the model as an engine. The harness is the chassis, dashboard, brakes, steering, speed limiter, maintenance log, and inspection protocol. Engine power matters, but you cannot ship a vehicle with engine power alone.
Evaluation docs across multiple ecosystems point in the same direction. OpenAI describes evals as a structured loop of defining a task, running test inputs, analyzing results, and improving the system. LangSmith separates offline evaluation from online production evaluation, and Braintrust groups datasets, scorers, tracing, CI integration, and monitoring as the evaluation workflow (source: OpenAI Evals, LangSmith Evaluation Concepts, Braintrust LLM Evaluation Guide). That shared loop is the skeleton of a harness.
Why the idea became urgent
AI demos fail differently from traditional demos. A demo can look fluent while hiding brittle behavior. After deployment, the same user intent appears in new language, retrieval results shift, tools time out, users provide malicious input, costs creep up, and the model gives a plausible but wrong answer.
OpenAI and Braintrust both emphasize explicit goals, curated datasets, metrics, comparisons, and continuous evaluation because generative outputs are variable by nature. Langfuse similarly frames evals as repeatable behavior checks that catch regressions before deployment (source: OpenAI Evaluation Best Practices, Braintrust LLM Evaluation Guide, Langfuse Evaluation Overview).
A practical definition
Working definition
Harness engineering is the design of the context, tool, evaluation, observability, permission, and feedback-loop system that lets an AI model operate inside a product with measurable quality.
The key word is system. A prompt is only one part of the harness. The reliability of the product comes from the whole operating structure.
Where weak harnesses fail
Teams with weak harnesses usually fail in predictable ways. They change a prompt and do not know which old cases broke. They see a bad production answer but do not feed that case back into the test suite. They cannot tell whether a failure came from retrieval, tool selection, tool execution, or final answer generation. They cannot see which workflow is burning latency and cost.
That is not a model problem alone. It is a harness problem.
Why don’t AI apps become products with prompts alone?
Prompts are easy to edit, so teams overuse them. When a model gives a bad answer, the instinct is to add one more sentence to the system prompt. That works for a few local failures. It does not scale into product reliability.
Prompts cannot guarantee repeatability
The same prompt can produce different answers across model versions, temperatures, context windows, retrieval inputs, and hidden tool results. Even when the output is correct, the reasoning path may change. A product team needs to know which changes are acceptable and which are regressions.
For example, an AI support agent may answer a refund question correctly in a demo. In production, the user includes screenshots, conflicting dates, past order history, and a policy edge case. A longer prompt might help, but the real need is a harness that retrieves the correct policy, masks private data, validates refund eligibility, logs the trace, and blocks unsafe actions.
Prompts cannot observe the system
When a user reports a bad answer, a prompt-only app often has no useful record. Which prompt version ran? Which documents were retrieved? Which tools were called? What did the model see? What was hidden by safety filters? How much did the run cost? Was this a single failure or a cluster?
Without traces, you debug with anecdotes.
Prompts cannot create deployment discipline
A product team needs a release question: can this change ship? The answer cannot be “the demo looked fine.” A harness gives you release gates:
- Does the new version pass the golden set?
- Did it improve the target metric without hurting latency?
- Did it introduce a new unsafe tool path?
- Did the judge agree with human labels on known tricky cases?
- Did cost per successful task stay within budget?
That is the difference between prompt iteration and product engineering.
If the fix lives only in the prompt, it is probably a local patch. If the fix adds a test, trace, permission rule, or deployment gate, it becomes part of the product’s memory.
How are prompt, context, and harness engineering different?
The three terms overlap, but they answer different questions.
| Discipline | Main question | Typical artifacts | Failure when missing |
|---|---|---|---|
| Prompt engineering | How should the model respond right now? | System prompt, few-shot examples, output schema | Answers are vague, inconsistent, or poorly formatted |
| Context engineering | What should the model know for this run? | RAG chunks, user state, memory, tool results | The model reasons with stale, irrelevant, or missing facts |
| Harness engineering | How do we make the whole AI workflow reliable? | Evals, traces, CI gates, policies, dashboards, rollback rules | Quality cannot be measured, reproduced, or improved |
Prompt engineering shapes the instruction surface
Prompt engineering is still useful. It defines the model’s role, constraints, output shape, and examples. It is the fastest way to correct a narrow behavior problem.
But prompt changes should be treated like code changes. They need versioning, tests, and release gates because they can silently change behavior elsewhere.
Context engineering shapes the evidence surface
Context engineering decides what evidence enters the model window. In RAG systems, this includes chunking, retrieval, reranking, citations, user profile data, session memory, and tool outputs. In agent systems, it also includes task state and action history.
If context is noisy, even a strong model will sound confident while being wrong. In that sense, RAG failures are often harness failures disguised as model failures.
Harness engineering shapes the operating surface
Harness engineering wraps prompt and context work inside a larger product loop. It asks how the system is tested, observed, secured, deployed, and repaired.
This is where AI app development begins to look less like one clever prompt and more like an operating system for model behavior.
What layers make a good harness?
A useful harness is not one monolithic tool. It is a stack of small controls that reinforce each other.
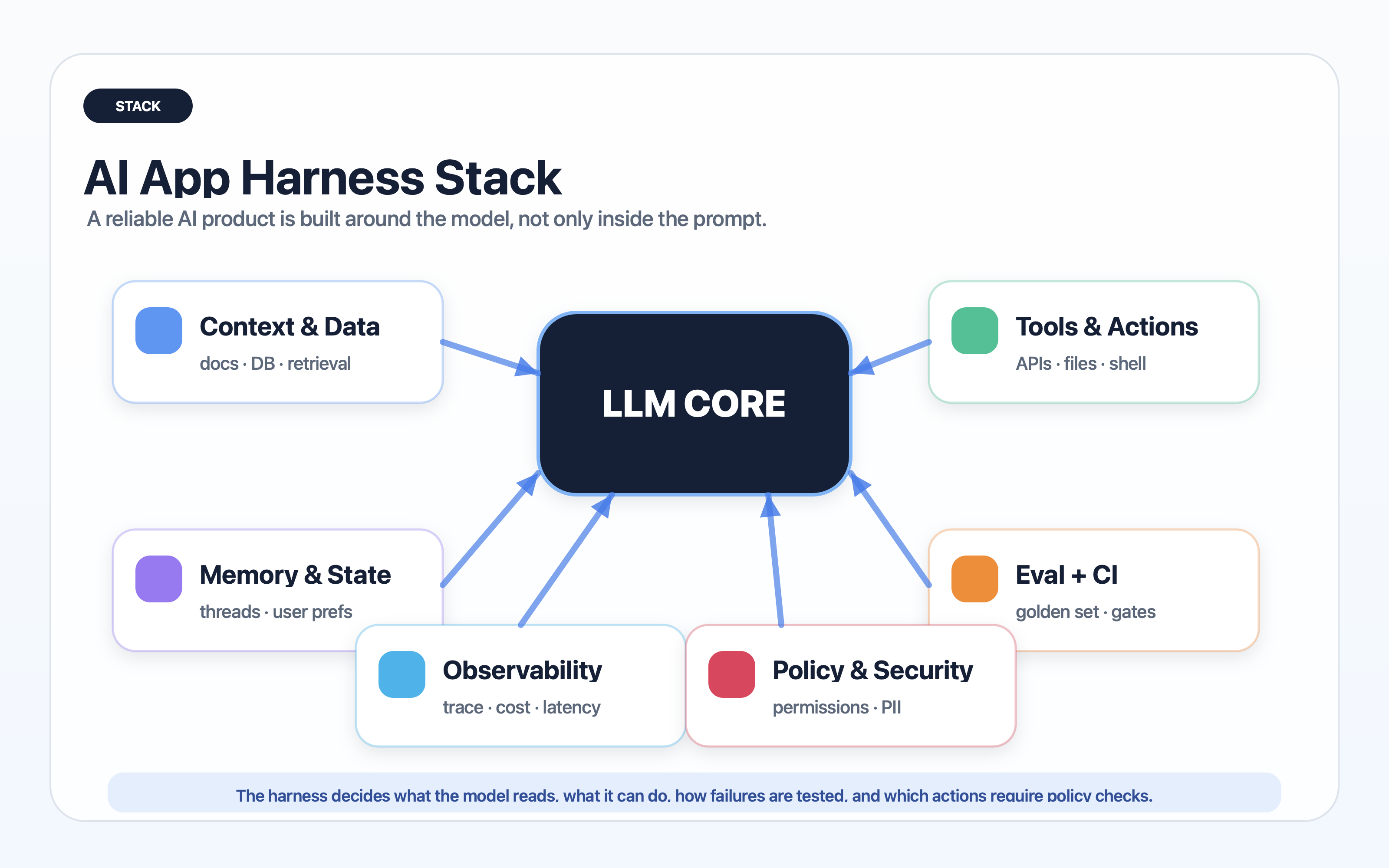
Layer 1: product workflow
Start from the user workflow, not from the model. What job is the user trying to complete? What counts as success? What action is irreversible? Where should a human approve the result?
Without this layer, teams optimize for pretty answers rather than completed tasks.
Layer 2: prompt and policy contract
The system prompt should be short enough to maintain and explicit enough to test. It should define the role, forbidden behavior, output schema, escalation rule, and citation requirement.
Treat the prompt as a versioned contract. If it changes, the eval suite should run.
Layer 3: context and memory
The harness controls the sources the model can use. That includes document retrieval, user state, conversation memory, cache policy, and redaction. Good context engineering is not “put more text in the window.” It is deciding which evidence is allowed into the run and how it is labeled.
For deeper retrieval architecture, the Graphify guide is a useful companion because it shows why graph-shaped context can behave differently from vector-only retrieval.
Layer 4: tools and action boundaries
Tools turn the model from a writer into an actor. That is powerful and dangerous. The harness should define:
- Which tools exist
- Which arguments are allowed
- Which actions require confirmation
- Which tools are read-only
- Which tool outputs must be validated
- Which tool failures should stop the run
The rule of thumb is simple: the more irreversible the action, the tighter the harness.
Layer 5: evaluation and CI
Evaluation gives the team a way to compare versions. A harness should include deterministic checks for easy cases, semantic scoring for subjective cases, and human review for high-risk cases.
Do not wait for a perfect benchmark. Start with 30 to 50 cases that represent the actual user workflow. Add every painful production failure to that set.
Layer 6: observability and replay
Traces are the memory of the harness. A trace should show prompt version, model version, inputs, retrieved context, tool calls, intermediate outputs, final answer, latency, cost, and user feedback.
Without traces, incident review becomes storytelling.
Layer 7: deployment gates and rollback
CI gates convert evaluation into release discipline. The harness should block a deployment when quality drops below a threshold, when latency exceeds budget, when unsafe tool paths appear, or when required citations disappear.
Rollback is part of the harness too. A team should be able to revert a prompt, model, retrieval config, or tool policy without rewriting the app.
Layer 8: governance and privacy
Security should not be an afterthought. The harness needs PII redaction, data retention rules, prompt-injection defenses, audit logs, access control, and policy checks for tool use.
This is especially important for agents because an agent can combine private context, model reasoning, and external actions in one run.
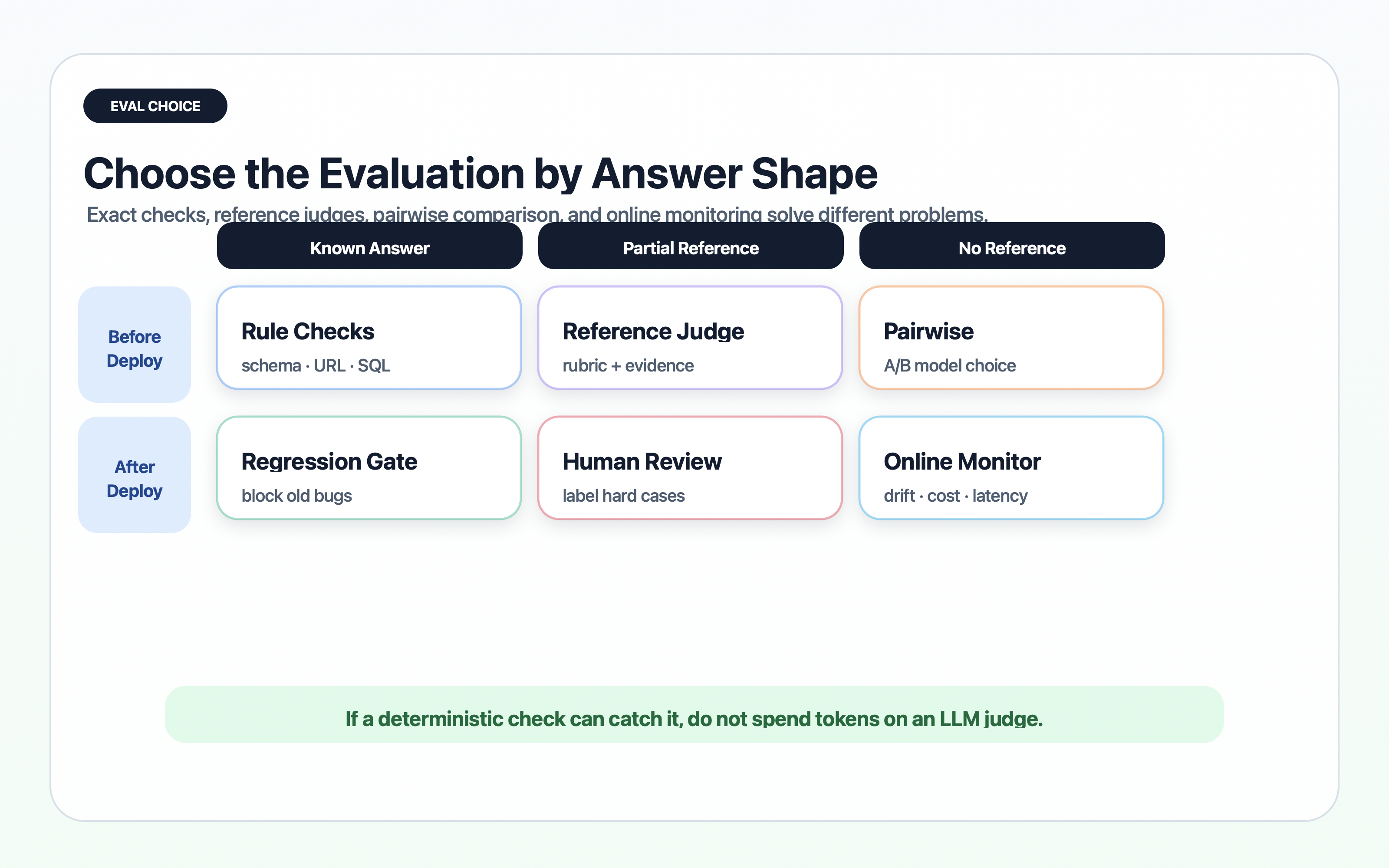
How do you test an LLM that changes its answer every time?
You test the system at multiple levels. Do not ask one metric to carry the entire product.
Start with a golden set
A golden set is a curated collection of inputs, expected behavior, edge cases, and known failures. It does not need to be huge at the beginning. It needs to be representative.
Good first cases include:
- The 10 most common user intents
- The 10 most expensive failure modes
- The 10 cases where the model sounds confident but is wrong
- The 10 cases that require tool use
- The 10 cases that require refusal, escalation, or human review
The key is to write the expected behavior clearly. Sometimes the expected output is exact. Sometimes it is a rubric.
Separate deterministic checks from semantic checks
Some requirements are easy to check with code. Did the JSON parse? Did the answer include required fields? Did the citation URL come from an approved domain? Did the tool argument match a schema?
Other requirements need semantic evaluation. Is the answer faithful to the source? Did it resolve the user’s intent? Is it safe? Does it explain uncertainty?
Use deterministic checks wherever possible because they are cheap and stable. Use LLM-as-judge only where meaning actually matters.
| Check type | Best for | Example | Risk |
|---|---|---|---|
| Deterministic | Format, schema, required fields, policy flags | JSON parses and every citation has a source id | Misses semantic correctness |
| Embedding or similarity | Near-duplicate answers and broad relevance | Answer stays close to approved answer | Can reward surface similarity over truth |
| LLM-as-judge | Faithfulness, helpfulness, safety, rubric scoring | Judge checks whether answer is grounded in retrieved docs | Judge can drift or overfit |
| Human review | High-risk workflows and new failure classes | Reviewer labels production traces | Expensive and slower |
Measure deltas, not vibes
The most useful question is not “is this model good?” The useful question is “did this version improve the target workflow without breaking known cases?”
Track version-to-version deltas:
- Task success rate
- Faithfulness to source
- Tool success rate
- Refusal accuracy
- Citation coverage
- Median and p95 latency
- Cost per successful task
- Human escalation rate
This is why a harness needs CI. If a change makes one metric better and three metrics worse, the release gate should show that tradeoff before users feel it.
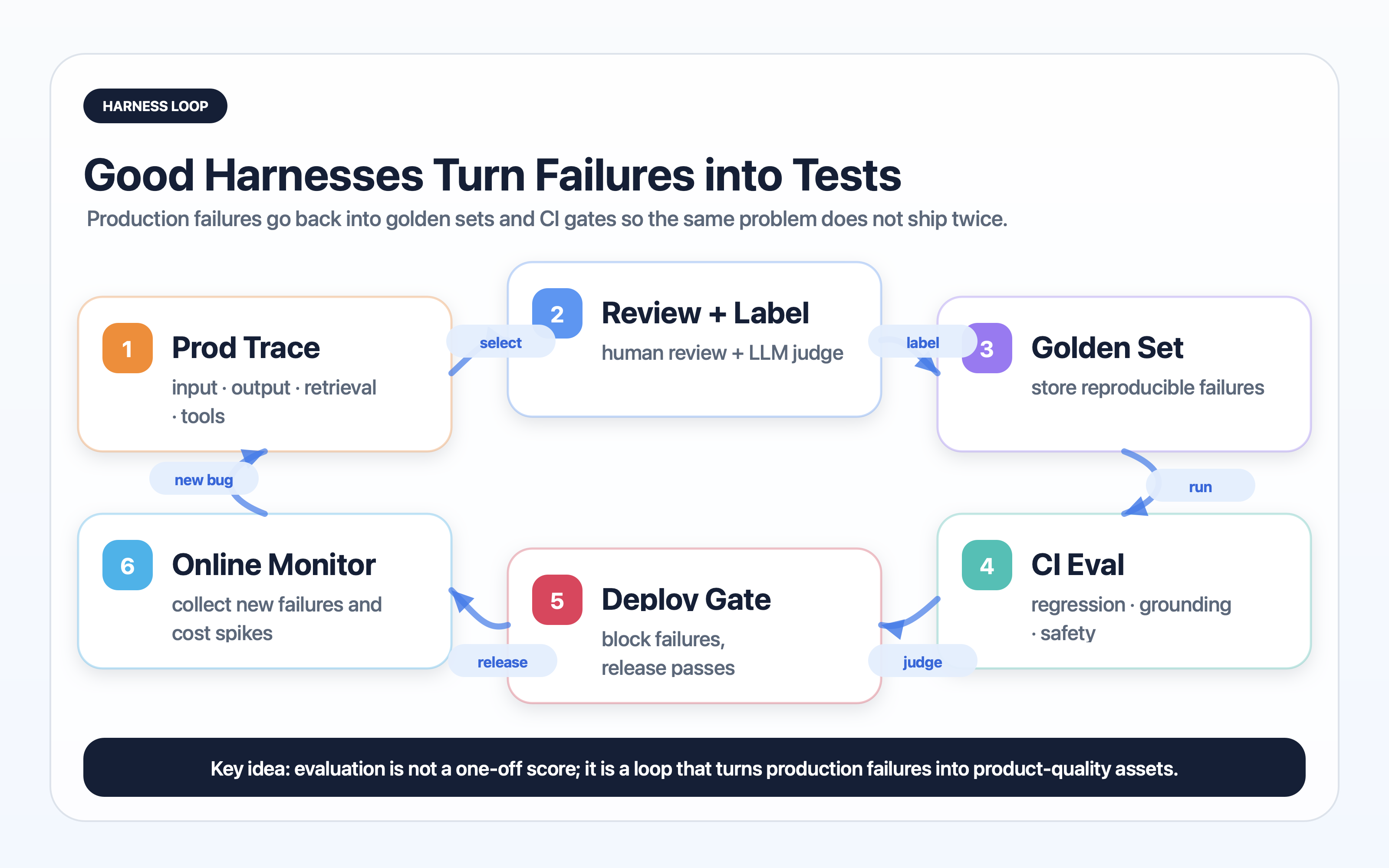
Convert incidents into tests
Every production incident should leave behind at least one artifact: a new golden-set case, a new rule, a new judge rubric, a new dashboard alert, or a new permission boundary.
If incidents do not update the harness, the team is paying twice for the same lesson.
What should you evaluate separately for RAG and agents?
RAG and agents fail in different places. A good harness separates those failure points instead of giving the whole run one vague score.
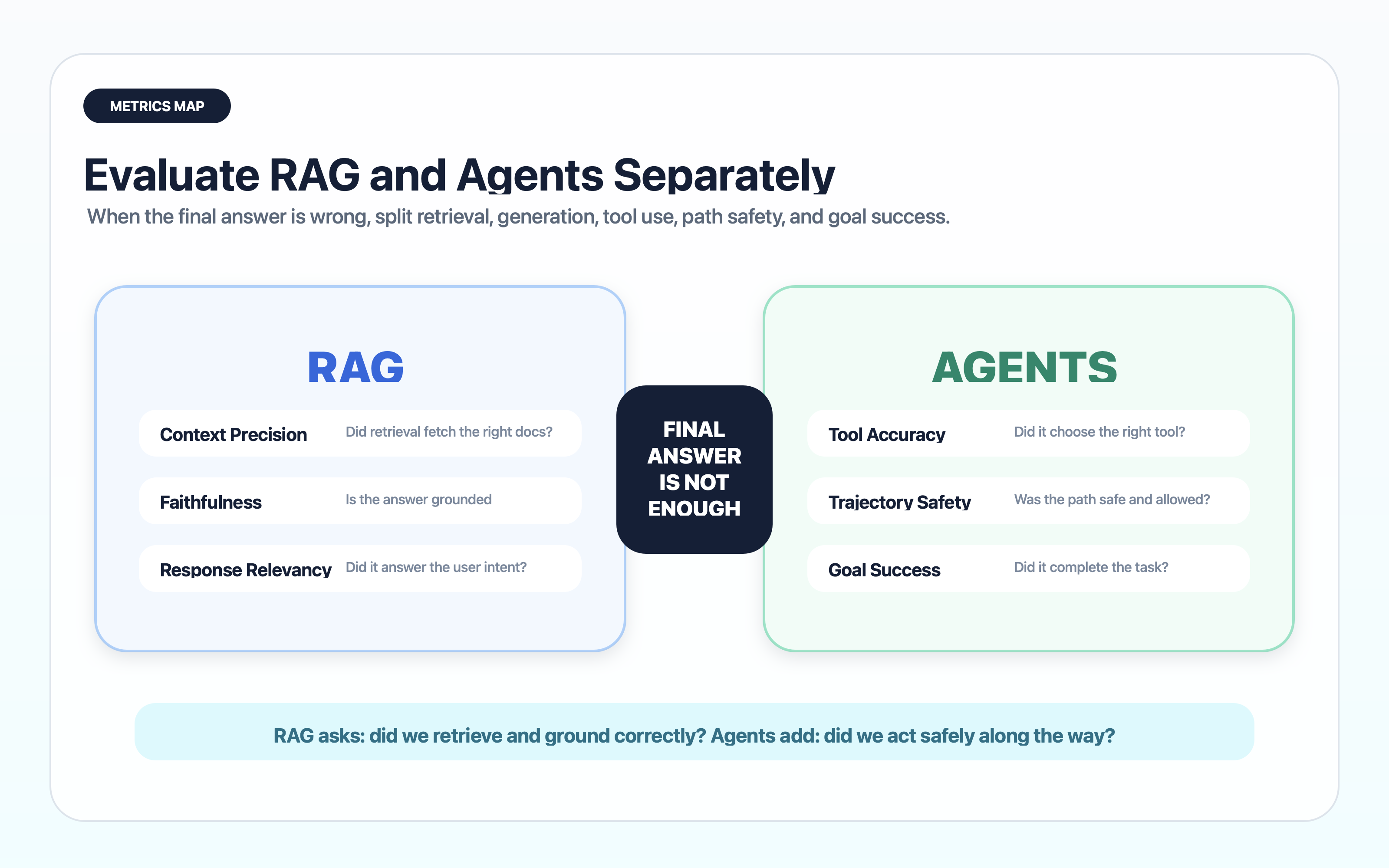
RAG needs retrieval and generation metrics
RAG systems should be evaluated before the model writes the final answer. If the retriever did not fetch the right evidence, the generator is already working from a weak hand.
Ragas is useful here because it separates retrieval and generation signals instead of collapsing the whole workflow into one score. Its metric set includes context precision, context recall, noise sensitivity, response relevancy, faithfulness, and tool/agent metrics such as tool call accuracy and agent goal accuracy (source: Ragas Metrics).
Evaluate retrieval with:
- Recall at k: did the right source appear?
- Precision at k: how much retrieved content was actually useful?
- Source freshness: was the retrieved document current?
- Chunk quality: did the chunk contain enough context?
- Citation integrity: did the final answer cite the source it used?
Then evaluate generation separately:
- Faithfulness to retrieved context
- Completeness
- Refusal when evidence is missing
- Explanation quality
- User task completion
This split matters because the fix is different. A retrieval failure needs indexing, chunking, reranking, or source quality work. A generation failure needs prompt, rubric, model, or output-contract work.
Agents need path-level evaluation
An agent can arrive at a decent answer through an unsafe path. That means final-answer scoring is not enough.
Anthropic makes the same point in its multi-agent research system writeup: complex agents can take multiple valid paths from the same starting point, which makes evaluation harder than single-answer scoring (source: Anthropic Engineering).
Agent harnesses need to evaluate:
- Plan quality: was the next action reasonable?
- Tool choice: did the agent call the right tool?
- Argument safety: were tool arguments valid and allowed?
- Step budget: did the agent loop or overthink?
- Recovery: did it handle tool failure gracefully?
- Goal success: did the workflow finish?
- Human handoff: did it ask for approval at the right moment?
This is where agent observability tools matter. You need traces that show the path, not only the output.
The answer can be correct while the harness still fails
Suppose an agent updates a customer record correctly. If it did so after reading a private field it did not need, calling an unapproved tool, or skipping a confirmation step, the harness failed even though the final state looks right.
That is the central difference between answer quality and product quality.
Which tools should you choose first?
Do not start by buying a large platform. Start by choosing the first missing capability in your harness.
| Tool category | What it gives you | Examples | When to adopt |
|---|---|---|---|
| Minimal CI harness | Versioned cases, deterministic checks, release gates | pytest, custom scripts, JSONL datasets | When you need control before platform features |
| Prompt and policy testing | Scenario tests, red-team checks, regression suites | promptfoo, DeepEval, CI scripts | When release gates are missing |
| Experiment tracking and evals | Datasets, scorers, experiment comparison | Braintrust, LangSmith, OpenAI Evals | When prompt or model changes are frequent |
| Observability and tracing | Run traces, spans, latency, cost, feedback | LangSmith, Langfuse, OpenTelemetry | When production failures are hard to reproduce |
| RAG evaluation | Retrieval quality, faithfulness, answer relevance | Ragas, custom retrieval evals | When source grounding is the product risk |
| Agent frameworks | Tool calling, state, memory, orchestration | LangGraph, Cloudflare Agents SDK, custom workflow code | When workflows require multi-step action |
| Security controls | PII redaction, access control, audit logs | Presidio, policy engines, app-level RBAC | When private data or tool actions are involved |
Braintrust, LangSmith, Langfuse, and promptfoo solve different slices
Braintrust is strong when you want datasets, scorers, experiment comparison, and evaluation workflows around product iterations (source: Braintrust Evals).
LangSmith is strong when you need traces, datasets, feedback, annotation queues, and evaluation around LangChain or LangGraph applications (source: LangSmith Evaluation).
Langfuse is strong for open-source LLM observability, traces, prompt management, and production monitoring (source: Langfuse Documentation).
promptfoo is useful when you want test cases, assertions, red-team scenarios, and CI-friendly prompt/model comparison (source: promptfoo Documentation).
OpenTelemetry matters when AI traces need to live beside normal application telemetry rather than in a separate island (source: OpenTelemetry Documentation).
A simple adoption order
If you are early, use this order:
Create the golden set
Write 30 to 50 real cases with expected behavior, failure notes, and owner.
Add deterministic checks
Validate schemas, citations, tool arguments, forbidden actions, and required refusal paths.
Add semantic scoring
Use LLM-as-judge for faithfulness, task success, and safety only where code checks are not enough.
Record traces
Persist prompt version, model, retrieved context, tool calls, latency, cost, and user feedback.
Connect CI
Run the eval suite on prompt, retrieval, tool, and model changes before deployment.
Review production failures
Sample traces weekly and convert new failure classes into tests or policy changes.
Buy tools after the workflow is clear
Tools are accelerators, not substitutes for judgment. If your team cannot define what a good answer means, a dashboard will only make the confusion prettier.
Start with the workflow, then pick tools that remove friction.
Where do screenshots and infographics help most?
For this article, the Korean version already had several diagrams. The English version uses separate English PNG images so readers are not forced through translated SVG labels.
Add screenshots where readers need proof, not decoration
Screenshots are useful in three places:
- A trace view showing input, retrieved context, tool calls, cost, and latency
- A dataset or golden-set view showing how cases are stored
- A CI result showing pass/fail deltas between two versions
Screenshots are less useful when they only show a blank dashboard or a marketing page. The reader needs to see the operational surface.
Use infographics where the mental model is the product
Harness engineering is abstract. Diagrams help because they show boundaries: model vs context, answer vs trace, retrieval vs generation, eval vs deployment gate.
The best visual in this topic is not a model architecture diagram. It is the feedback loop from production failure to golden set to CI gate to deployment.
Keep image text in the target language
This sounds small, but it matters. If the article is in English and the diagram text is Korean, the diagram becomes decorative. For an article about operational clarity, the image itself should be operationally clear.
That is why this English version uses a separate /images/posts/harness-engineering-ai-apps-en/ image set.
Where should security and privacy controls live?
Security belongs inside the harness, not after it.
Prompt injection is a harness failure, not only a model failure
Prompt injection works by smuggling instructions through content that the model treats as evidence. A harness should label untrusted content, separate system instructions from retrieved documents, and define which text can influence tool use.
For RAG systems, retrieved documents should be evidence, not authority. For agents, tool permissions should be enforced outside the model because the model can be manipulated.
Tool permissions should be external and explicit
Do not rely on the prompt alone to prevent dangerous actions. The harness should enforce permissions at the tool layer:
- Read-only tools by default
- Separate scopes for search, write, delete, purchase, send, and deploy
- Confirmation for irreversible actions
- Argument validation before execution
- Allow-lists for domains, repositories, tables, and APIs
- Audit logs for every tool call
The model can recommend an action. The harness decides whether the action is allowed.
Privacy controls should run before and after the model
The harness should redact or minimize sensitive input before the model sees it. It should also scan model output before showing it to the user or sending it to another system.
Useful controls include:
- PII detection and redaction
- Secret detection for tokens and credentials
- Data retention rules by workflow
- Access control tied to user identity
- Source-level permissions in retrieval
- Audit logs for regulated workflows
In other words, privacy is not one checkbox. It is a data path through the harness.
If a tool can send email, spend money, delete data, deploy code, or expose private records, the permission check must live outside the model. Prompts can guide behavior; they should not be the final enforcement layer.
How do you raise harness maturity?
Harness maturity grows in stages. Most teams start with manual testing and gradually add datasets, traces, CI, production monitoring, and governance.
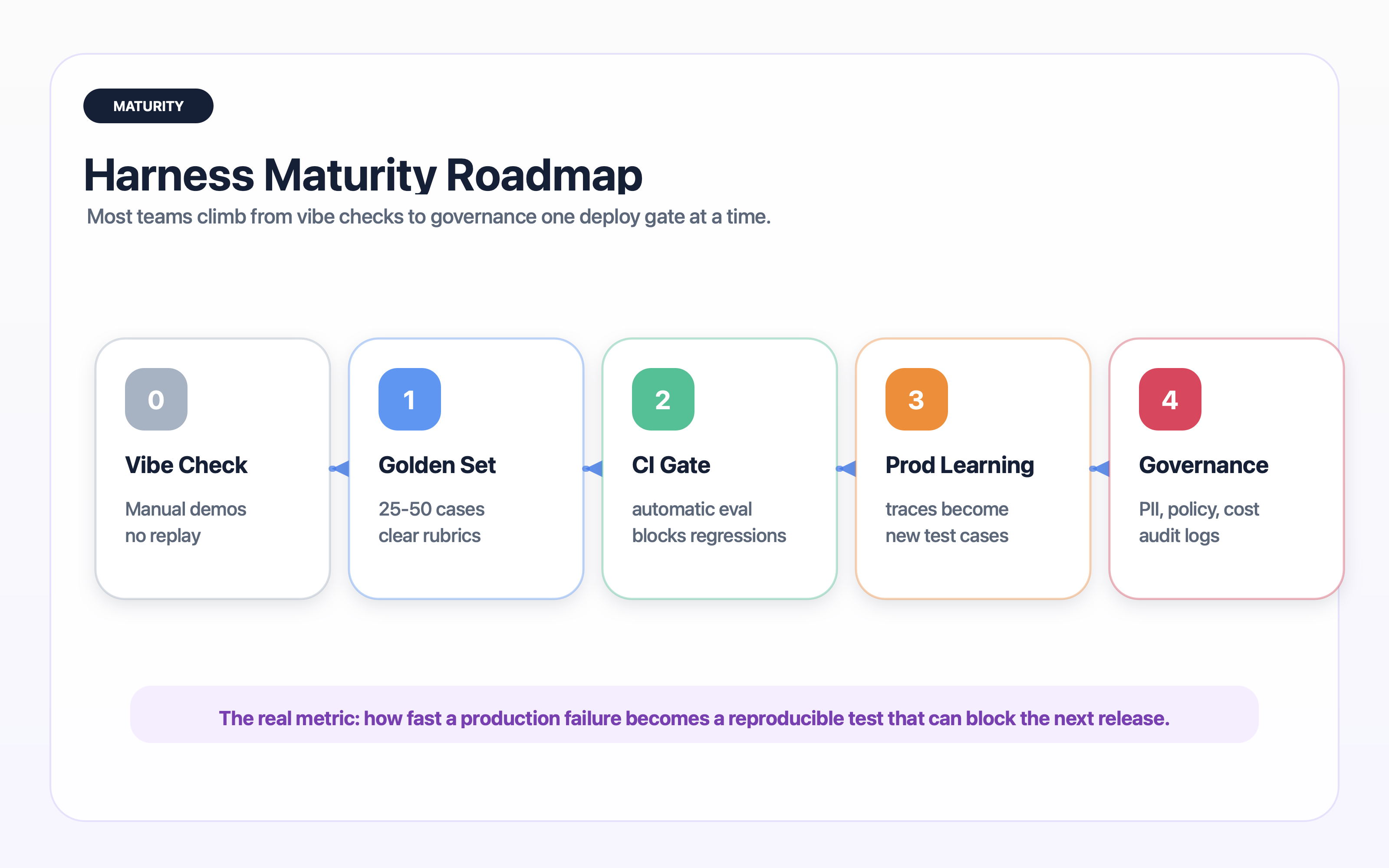
Level 0: vibe checks
The team tries a few examples in a chat window. This is normal at the prototype stage, but it is not a release process.
Risk: every improvement is anecdotal.
Level 1: saved examples
The team stores important examples in a document, spreadsheet, or notebook. This creates memory, but not automation.
Risk: cases become stale and nobody knows which version passed.
Level 2: golden set with deterministic checks
The team stores cases in a structured file and runs basic assertions. This catches format and policy regressions.
Risk: semantic quality still slips through.
Level 3: semantic evals and trace replay
The team adds LLM-as-judge scoring, human labels, and trace replay. Now failures can be reproduced and compared.
Risk: judge quality must be monitored and calibrated.
Level 4: CI gates and rollout rules
Prompt, retrieval, model, and tool changes trigger eval runs. Deployments can be blocked when quality drops.
Risk: teams may overfit to the golden set and ignore new production behavior.
Level 5: production learning loop
Production traces are sampled, labeled, clustered, and fed back into the golden set. The harness becomes a learning system.
Risk: privacy, governance, and annotation quality become more important.
Level 6: governed AI product system
The harness includes release policy, audit logs, red-team tests, data retention, incident review, and business metrics.
This is where AI apps become normal software products instead of fragile demos.
What is the smallest harness you can build today?
You can build a useful harness in one afternoon. It will not be perfect, but it will be far better than manual prompt tweaking.
The one-day starter harness
Create a folder like this:
ai-harness/
cases.jsonl
run_eval.ts
scorers/
schema.ts
faithfulness.ts
safety.ts
traces/
reports/
README.mdEach case should have:
{
"id": "refund-policy-001",
"input": "Can I get a refund after 31 days if the item arrived broken?",
"expected_behavior": "Explain the damaged-item exception, ask for order details, and avoid promising a refund before verification.",
"required_sources": ["refund_policy_v4"],
"must_not": ["promise automatic refund", "ask for full card number"],
"risk": "customer_support"
}Then run the same cases against the current version and the proposed version. Store the result. That is enough to start seeing regressions.
The first CI gate
Your first gate can be simple:
- 100 percent of schema checks pass
- No critical safety case fails
- Faithfulness average does not drop
- p95 latency does not increase more than 20 percent
- Cost per successful task stays under budget
This is not perfect science. It is deployment discipline.
The first production feedback loop
Sample a small percentage of production traces. Review the worst cases weekly. Add the best failure examples to cases.jsonl. Track which failures repeat after fixes.
That last step is where the harness starts to compound.
What should you trust, and what should you keep questioning?
Harness engineering is powerful, but it has traps.
Trust the trend, question the measurement
Evals help, but they can be wrong. LLM judges can prefer verbose answers, miss subtle factual errors, or overfit to rubric language. Human labels can be inconsistent. Golden sets can go stale.
The solution is not to reject evals. The solution is to evaluate the evaluators.
Use calibration sets, spot-check judge decisions, compare against human labels, and track judge drift when model versions change.
Do not optimize only for benchmark score
If the eval suite becomes the only target, the system can overfit to it. A harness should include fresh production cases, red-team cases, and business outcomes.
For a support agent, answer faithfulness matters, but so do resolution rate, escalation quality, customer satisfaction, and policy compliance.
Do not confuse traces with understanding
A trace shows what happened. It does not automatically explain why it happened. You still need engineering judgment to separate root cause from coincidence.
This is why review workflows matter. The harness should make failures visible, but people still decide which fixes are real.
Frequently asked questions
Is harness engineering just a new name for LLMOps?
Do I need a full evaluation platform before shipping an AI feature?
How many test cases are enough at the beginning?
Can LLM-as-judge replace human review?
What is the most common mistake?
Where should a small team start?
Conclusion: where does AI product quality actually come from?
AI product quality comes from the whole system around the model.
The prompt tells the model what to do. The context tells it what to know. The tools let it act. The eval suite tells the team whether behavior improved. The trace tells the team what happened. The CI gate decides whether a change can ship. The security layer decides what the model is allowed to touch. The feedback loop turns failure into institutional memory.
That is harness engineering.
The practical takeaway is simple: stop treating AI quality as a private conversation with a model. Treat it as a product system that can be measured, replayed, governed, and improved.
If you want the broader context for AI coding workflows, read Karpathy’s LLM Wiki concept guide. If you want a concrete retrieval-heavy companion, read the Graphify hands-on guide. And if your team is already using coding agents, the Claude Code review guide is a useful next step for turning model output into reviewable engineering work.
Was this helpful?
One tap shapes what gets written next.

What Is PlayMCP? Kakao's MCP Hub and OpenClaw Integration Explained
A current guide to what PlayMCP really is, how Kakao's toolbox and mcp-gateway work, and why the OpenClaw integration matters.
Read
What Is Vectorless RAG? Is PageIndex a Real RAG Alternative?
A current guide to why PageIndex says it can search long documents without vector databases or chunking, and how to read its pricing, MCP surface, FinanceBench claims, and real limits.
Read
Andrej Karpathy's 4 AI Coding Warnings and the 100K-Star CLAUDE.md Repo
A deep dive into the four bad AI coding habits Karpathy warned about, the CLAUDE.md repo's four operating principles, what evidence supports them, and where the limits still are.
Read