RTX 4090에서 직접 돌려본 로컬 코딩 에이전트 후기 — Qwen 3.6 27B (2026)
RTX 4090과 Mac M4 Max에서 직접 돌려본 로컬 코딩 에이전트 후기. SWE-bench 77%·1M 컨텍스트·Apache 2.0 오픈소스 모델 Qwen 3.6 27B의 설치, VRAM, Claude 대비 실력을 정리했다.

빠른 결론
먼저 이렇게 보면 됩니다
약 39분 읽기한 줄 판단
RTX 4090과 Mac M4 Max에서 직접 돌려본 로컬 코딩 에이전트 후기. SWE-bench 77%·1M 컨텍스트·Apache 2.0 오픈소스 모델 Qwen 3.6 27B의 설치, VRAM, Claude 대비 실력을 정리했다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- 로컬 LLM · Qwen · 로컬 코딩 에이전트
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
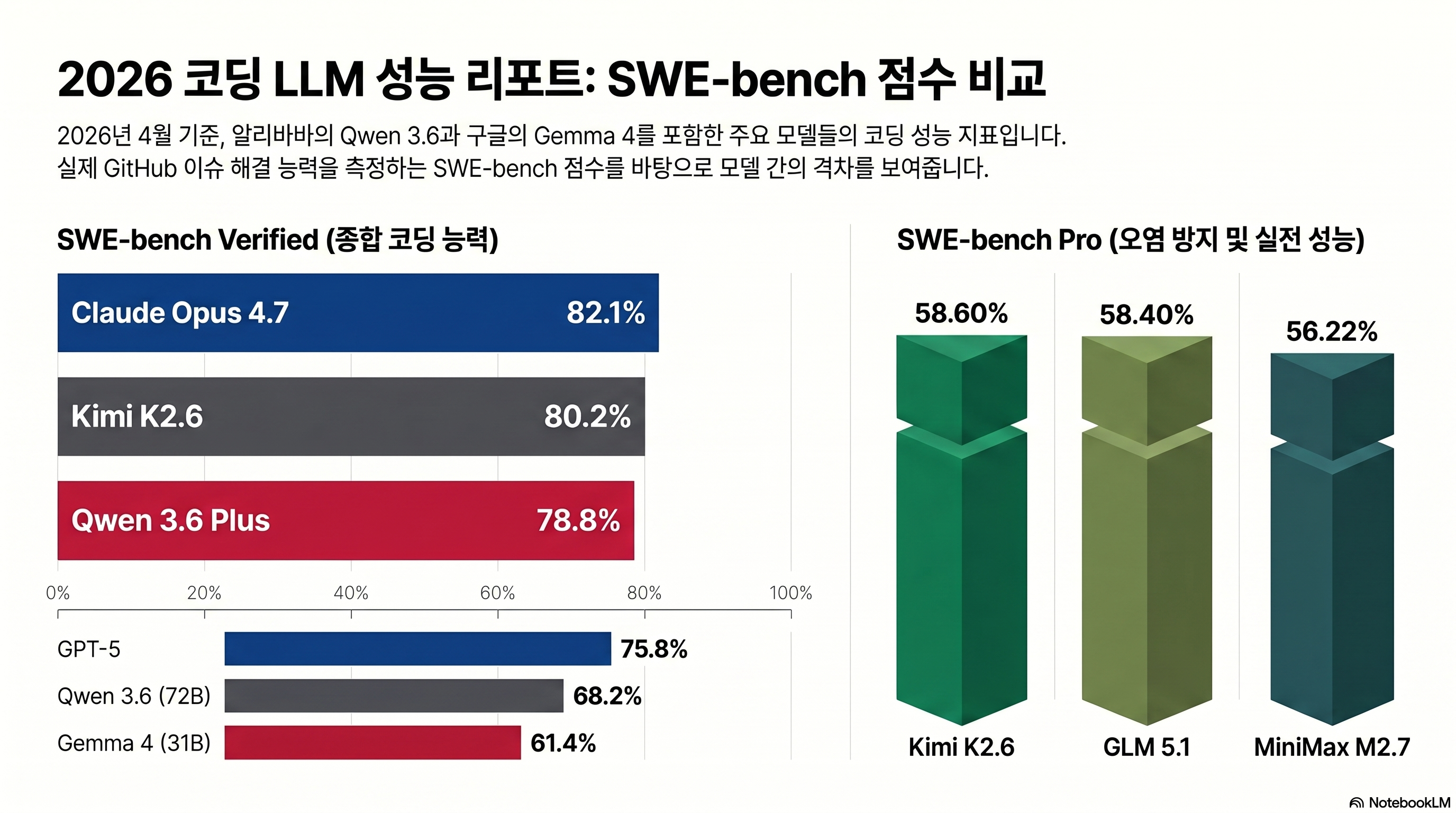
- Claude Opus 4.7 한 달 청구서가 부담스러운 1인 개발자라면, RTX 4090 24GB 단 한 장으로도 SWE-bench Verified 77.2%를 찍는 Qwen 3.6 27B를 본격 검토할 시점이다.
- 27B Dense는 Q4_K_M 양자화 시 약 17GB VRAM, 코드 작업에서 RTX 4090 단일 기준 약 60 t/s까지 나오고, 35B-A3B(MoE)는 같은 GPU에서 활성 3B 덕분에 더 빠르다.
- 다만 Terminal-Bench 2.0 자체 측정치(38.2%)와 공식치(59.3%) 사이의 격차, GitHub의 빈 tool-call·무한루프 이슈, DashScope 데이터 중국 라우팅 이슈 같은 한계도 분명히 남는다.
목차
- Qwen 3.6 27B는 정말 Claude Opus 4.7과 어깨를 나란히 할 수 있을까?
- RTX 4090 24GB로 4bit 양자화 돌려보면 토큰 속도는 얼마나 나올까?
- Claude API 비용을 0원으로 줄이려면 27B와 35B-A3B 중 뭘 써야 할까?
- Mac M4 Max 통합 메모리로도 코딩 에이전트가 실용적으로 돌까?
- Apache 2.0 라이선스, 사내 데이터에 그냥 올려도 정말 안전할까?
- SWE-bench Verified 77%·Terminal-Bench 2.0 59%, 한국어 코드 PR도 잘 풀까?
- Qwen 3.6 27B를 Cline·OpenCode·Aider 어디에 붙이는 게 가장 효율적일까?
- 한 달 써보니 한계는 뭐였나?
- 결론: 누가 써야 할까?
Claude Opus 4.7의 토큰당 단가가 한 달 청구서로 돌아오는 1인 개발자에게, 2026년 4월 알리바바가 공개한 Qwen 3.6 27B는 단순한 또 다른 오픈소스 모델이 아니다. RTX 4090 한 장(약 290만 원) 위에서 SWE-bench Verified 77.2%를 찍는 Dense 모델이 Apache 2.0으로 풀려나왔다는 사실은, 비용 페이로드가 큰 코딩 워크로드의 비용 구조를 다시 계산해야 한다는 뜻이다. 이 글은 27B와 35B-A3B(MoE) 두 개의 오픈 가중치 라인업을 RTX 4090·dual 3090·Mac M4 Max에서 직접 돌려본 외부 실측을 모아 정리한 후기다.
1. Qwen 3.6 27B는 정말 Claude Opus 4.7과 어깨를 나란히 할 수 있을까?
결론부터 적으면 코딩 정확도는 근접, 에이전트 실행은 여전히 격차다. 같은 한 줄 답이지만 어느 축을 보느냐에 따라 평가가 갈리는 모델이다.
공식 벤치마크: 27B Dense가 397B MoE를 모든 코딩 항목에서 추월
가장 강력한 한 문장은 Qwen 공식 모델 카드에 그대로 적혀 있다.
“With only 27B parameters, it outperforms the Qwen3.5-397B-A17B (397B total / 17B active) on every major coding benchmark — SWE-bench Verified (77.2 vs 76.2), SWE-bench Pro (53.5 vs 50.9), Terminal-Bench 2.0 (59.3 vs 52.5), SkillsBench (48.2 vs 30.0).”
같은 알리바바 라인 안에서 14배 작은 Dense 모델이 직전 세대 거대 MoE를 코딩 전 항목에서 추월했다는 점이 핵심이다. 모델 크기 경쟁이 끝났다는 한 줄짜리 증거에 가깝다.

Claude Opus 4.7과의 직접 비교
비교 대상은 2026-04-16에 GA된 Claude Opus 4.7이다. Opus 4.5와 4.6은 이전 버전이므로 4.7 수치로 통일해 표를 정리하면 이렇다.
| 벤치마크 | Qwen3.6-27B | Qwen3.6-35B-A3B | Qwen3.5-397B-A17B | Claude Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 77.2 | 73.4 | 76.2 | 80.9 |
| SWE-bench Pro | 53.5 | 49.5 | 50.9 | 57.1 |
| SWE-bench Multilingual | 71.3 | 67.2 | 69.3 | 77.5 |
| Terminal-Bench 2.0 | 59.3 | 51.5 | 52.5 | 74.7 |
| SkillsBench | 48.2 | 28.7 | 30.0 | 45.3 |
| AIME 2026 | 94.1 | 92.7 | 93.3 | 95.1 |
| LiveCodeBench v6 | 83.9 | 80.4 | 83.6 | 84.8 |
읽는 법은 두 갈래다. SWE-bench Verified·LiveCodeBench v6 같은 코드 정확도 항목에서는 27B가 Opus 4.7과 3~4pp 차로 붙는다. SkillsBench(48.2 vs 45.3)에서는 오히려 27B가 추월한다. 반면 Terminal-Bench 2.0은 59.3 vs 74.7로 15.4pp 격차가 나는데, 여기가 멀티 스텝 도구 호출과 자율 실행이 평가되는 항목이다. “코드 한 줄을 정확히 쓰는 능력”은 거의 따라잡았지만 “에이전트로 명령을 끝까지 밀어붙이는 능력”은 여전히 Claude가 앞선다. 출처: Qwen3.6-27B 공식 카드, Anthropic Claude Opus 4.7 발표.
외부 검증의 톤은 더 보수적이다
byteiota 리뷰는 공식 벤치마크를 “directional guidance”로만 보라고 못 박는다.
“Qwen3.6-27B is likely competitive with mid-tier proprietary models. It probably beats GPT-3.5-level performance. It almost certainly lags Claude Opus and the best of GPT-4. Run your own tests.”
공식 카드 수치와 자체 측정 결과는 워크로드에 따라 결과가 갈리므로, 어느 한 축에만 의존하기보다 두 출처를 함께 보는 편이 실제 운영 판단에 가깝다.
2. RTX 4090 24GB로 4bit 양자화 돌려보면 토큰 속도는 얼마나 나올까?
페르소나 A(RTX 3090/4090 보유 로컬 빌더)가 가장 먼저 묻는 질문이다. 단일 GPU에서 27B를 굴렸을 때 코드 자동완성으로 쓸 만한 속도가 나오는가, 가 핵심이다.
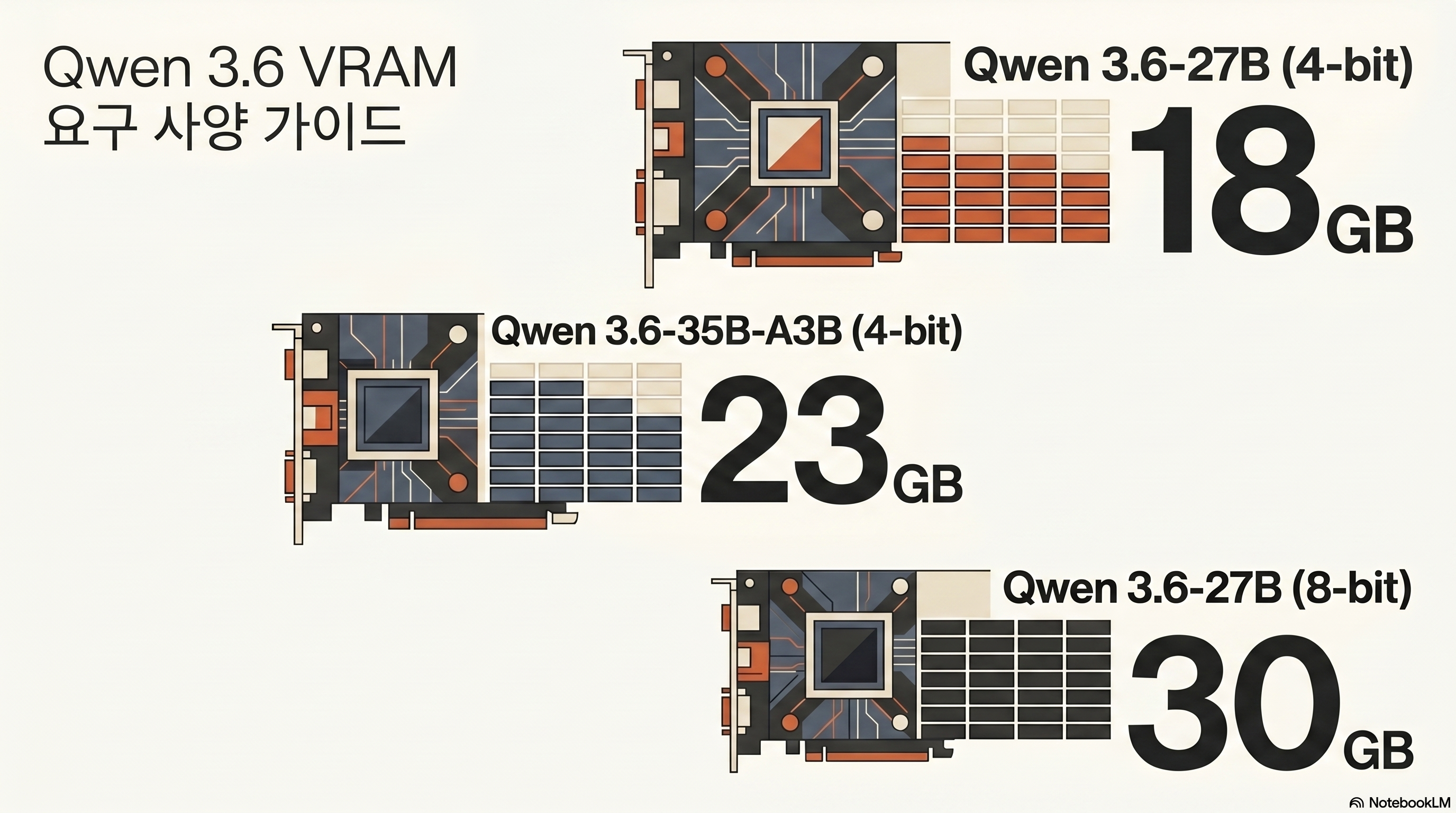
양자화별 VRAM 요구치
Unsloth 가이드 기준 27B Dense의 VRAM 요구치는 다음과 같다.
| 양자화 | 필요 VRAM | 권장 하드웨어 | 비고 |
|---|---|---|---|
| Q4_K_M (UD-Q4_K_XL) | 약 17 GB | RTX 3090/4090 (24GB) | 코드 작업 표준 |
| Q5_K_M / Q6_K_M | 약 24 GB | RTX 3090/4090 (24GB) | 정확도 중시 |
| Q8_0 | 약 30 GB | RTX 5090 (32GB) / Dual 3090 | 보존형 양자화 |
| BF16 (full) | 약 55 GB | A100 80GB / Dual 3090 80GB | 연구·파인튜닝 |
35B-A3B(MoE)는 Q4 기준 약 23GB가 필요하지만 활성 파라미터가 3B라 추론 속도는 27B Dense보다 빠르다. 출처: bartowski/Qwen3.6-35B-A3B-GGUF 양자화 카드.
환경별 토큰/초 실측
같은 모델이라도 GPU와 추론 엔진 조합에 따라 속도가 크게 갈리므로, 환경별 1차 측정을 한 표로 모아 reference range로 본다.
| 환경 | 모델·양자화 | 토큰/초 (실측) | 출처 |
|---|---|---|---|
| RTX 4090 단일 (mainline llama.cpp + 3.5-4B draft) | 27B Q8, 8K ctx | 평균 43, 피크 67 | outsourc-e/qwen36-4090-recipes |
| RTX 4090 단일 (Q4_K_M) | 27B 코드 작업 | 약 60~63 | byteiota·daily neural digest |
| Dual RTX 3090 (vLLM TP-2, AWQ-INT4) | 27B 256K ctx | 약 100 | Chris Dzombak |
| RTX 5090 (vLLM 0.19) | 27B 218K ctx | 약 80 | Daily Neural Digest |
| RTX 5090 + 4090 | 27B Q8 26만 ctx | 약 170 | r/LocalLLaMA Epicguru |
| Mac M4 Max 128GB (mlx_lm bf16) | 35B-A3B 배치 4 | 62~86 | walterra.dev 2026-04-18 |
가장 자주 인용되는 수치 하나만 골라낸다면 r/LocalLLaMA “Qwen 3.6, 드디어 쓸 만한 로컬 모델” 스레드의 Epicguru 코멘트다.
“5090+4090에서 Q8 모델을 26만 컨텍스트 풀로 로드해서 초당 약 170 토큰을 뽑아내는데, 이것도 내가 써본 모델 중에 제일 빠른 편이야. 10번 중에 9번은, 그냥 ‘끝났다’고 한 다음에 스스로 변경 사항을 검토해달라고 하면 잘못된 부분을 잡아내서 수정하더라고.”
물론 이 수치는 GPU 두 장 환경이라 일반적이지 않다. 단일 RTX 4090 사용자가 보수적으로 잡을 수 있는 reference는 Chris Dzombak의 dual 3090 vLLM Docker Compose 레시피의 약 100 t/s, 또는 단일 3090 환경에서 Q4 약 40 t/s 정도다. 한국 사용자 Threads @dextune의 실측이 가장 보수적이다.
“RTX 3090으로 Qwen3.6-27B Q4 모델 구동에 대한 얘기. 해외 블로그에서 vLLM을 통해 80tps가 나온다는 이야기가 있었는데 안정성에 문제가 있는 거 같다. llama.cpp 기준으로는 100K 정도 컨텍스트까지 밀면 대략 35~40tps 정도로 보는 게 맞을 듯하다. 그래도 이 정도면 개인이 27B급 모델을 테스트하기엔 충분히 의미가 있는 수치.”
요약하면 단일 RTX 3090/4090에서 Q4_K_M으로 약 40~63 t/s가 현실적인 reference이고, 듀얼 GPU나 vLLM tensor parallel로 100 t/s 이상을 노려볼 수 있다.
3. Claude API 비용을 0원으로 줄이려면 27B와 35B-A3B 중 뭘 써야 할까?
페르소나 B(API 비용 부담 1인 개발자)에게는 모델 선택보다 손익분기점 계산이 먼저다.
토큰 단가 비교
DashScope 가격 기준으로 정리한 표다. 같은 양의 입력·출력을 처리할 때 Opus 4.7과 Qwen3.6-72B가 30배 이상 차이가 난다.
| 모델 | Input ($/M) | Output ($/M) | Opus 4.7 대비 |
|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | 기준 |
| GPT-5 | $2.50 | $15.00 | 약 절반 |
| Qwen3.6-72B (DashScope) | $0.20 | $0.80 | 약 1/30 |
| Gemma 4 31B (참고) | $0.14 | $0.42 | 약 1/40 |
비용 모델만 보면 “전부 Qwen으로 옮겨라”가 답처럼 보이지만, 실제 운영은 그렇게 단순하지 않다. byteiota가 정리한 결정 프레임이 가장 실용적이다.
“After a $1,600 hardware investment (RTX 4090), every token processed costs effectively nothing. GPT-4 charges $2.50 per million input tokens. Process 640 million tokens and you’ve paid for the GPU. Claude Opus at $5 per million input tokens makes local deployment even more attractive — the same RTX 4090 pays for itself after just 320 million tokens.”
월 50M 토큰 이하면 API, 월 100M 토큰 이상이면 로컬, 50~500M 구간은 DevOps 역량으로 결정하라는 frame이다. RTX 4090을 기준으로 잡으면 월 사용량이 GPT-4 기준 6.4억 토큰, Opus 4.7 기준 3.2억 토큰에서 손익분기가 잡힌다. 출처: byteiota Qwen3.6 RTX 4090 리뷰.
27B Dense vs 35B-A3B MoE 선택 기준
같은 24GB VRAM 환경에서 두 모델은 명확히 다른 트레이드오프를 가진다.
- 27B Dense: Q4 17GB, 단순한 배포, 일관된 latency, gating/expert 라우팅 없음. 코드 정확도 기준치(SWE-bench Verified 77.2)가 더 높다.
- 35B-A3B MoE: Q4 23GB, 활성 3B 덕분에 같은 GPU에서 27B Dense 대비 약 3.5배 빠른 토큰/초가 나오는 환경도 있다(R_Duncan 측정 50
59 vs 190197 t/s). 다만 SWE-bench Verified는 73.4로 27B Dense보다 약 4pp 낮다.
코드 정확도가 우선이면 27B Dense, 토큰 처리량(예: 대량 리팩터링·문서 자동 생성)이 우선이면 35B-A3B다. 가격·라우팅 측면에서 Kimi K2.6 (Claude Opus 4.7을 88% 싸게 대체하는 법)이나 GLM 5.1 (Claude Code 비용 1/5)을 함께 검토하면 오픈 가중치 진영의 가격대가 더 선명하게 보인다.
4. Mac M4 Max 통합 메모리로도 코딩 에이전트가 실용적으로 돌까?
Apple Silicon은 통합 메모리(unified memory)라는 무기로 큰 모델을 끌어다 쓰지만, 메모리 양과 모델 크기가 맞아야 의미가 있다.
M4 Max 128GB는 35B-A3B의 sweet spot
walterra.dev 2026-04-18 후기는 M4 Max 128GB + mlx_lm + bf16 환경에서 35B-A3B의 실측 토큰/초를 정리했다.
- Fast chat (256/256): 62 t/s
- Long-context RAG (8K/128): 59 t/s
- Heavy code gen (512/2048): 59 t/s
- Batch=4: 86 t/s
작성자는 “Fast enough for coding tasks, free, and everything stays on my machine”이라고 평한다. 4-bit MLX 변형으로 떨어뜨리면 커뮤니티 보고로 약 91 t/s까지 보이지만 그 만큼 정확도 손해가 따른다. M2 Max 환경에서도 35B-A3B는 활성 3B 덕분에 30+ t/s가 나온다.
M4 mini 32GB는 비추, 16GB는 9B급까지
같은 통합 메모리라도 32GB 이하는 27B/32B급 모델이 곧장 한계에 부딪힌다. 클리앙의 페이즈가 정리한 후기가 가장 솔직하다.
- "M4 Max 128GB에 mlx_lm으로 35B-A3B를 올렸더니 코드 작업에서 60~80 t/s가 안정적으로 나온다. 모든 데이터가 내 기기에서 끝나는 점이 매력적이다." — walterra.dev 2026-04-18
- "5090+4090 조합으로 27B Q8을 26만 컨텍스트 풀로 올리고 170 t/s. 10번 중 9번은 끝났다고 답한 뒤 검토 요청하면 잘못된 부분을 스스로 잡아낸다." — r/LocalLLaMA Epicguru
- "Qwen 3.5 32B는 답변을 기다리다 '늙어 죽겠다'는 생각이 들 정도로 느립니다. 32GB 램으로는 버거운 느낌입니다. 결국 OpenAI-OSS-20B로 갈아탔습니다." — 클리앙 페이즈 (M4 mini 32GB)
- "RTX 3090에서 vLLM 80 tps 보고는 안정성에 문제가 있어 보인다. llama.cpp 기준 100K 컨텍스트까지 밀면 35~40 t/s가 현실이다." — Threads @dextune
M4 mini 32GB·맥북 16GB 사용자는 Qwen 3.6 27B/32B를 직접 돌리기보다, 클라우드 DashScope나 Oh My OpenAgent 같은 멀티 모델 하네스의 백엔드로 끼워 쓰는 편이 현실적이다.
5. Apache 2.0 라이선스, 사내 데이터에 그냥 올려도 정말 안전할까?
페르소나 C(사내 AI 도입 IT 담당자)가 가장 먼저 확인할 항목이다. 라이선스와 컴플라이언스는 별도 축이라는 점을 분리해서 짚는다.
Apache 2.0의 의미
Apache License 2.0 원문을 그대로 풀면 다음과 같다.
- 상업 이용 허용
- 수정과 재배포 허용
- 사유화(proprietary fork) 허용
- 명시적 patent grant 포함 (Apache 2.0의 차별점)
- 의무: copyright notice + license text + 수정 진술서 첨부
- 로열티·매출 공유·승인 불요, GPLv3와 호환
즉 27B/35B-A3B 가중치를 사내 GitLab에 올리고, 사내 RAG에 파인튜닝하고, 자사 SaaS 제품에 임베딩까지 가능하다. patent grant 덕분에 특허 소송 리스크가 낮다는 점이 법무팀 설득 포인트다.
단, DashScope API는 별개의 컴플라이언스 이슈
오픈 가중치 라이선스가 깨끗하다고 해서 DashScope API 호출까지 안전한 것은 아니다. theplanettools 분석이 이 부분을 명확히 분리한다.
“The Apache 2.0 license has no MAU caps, no revenue-share requirements, and no acceptable-use restrictions. The compliance question is separate: if you route traffic through the DashScope API, data goes through Alibaba Cloud infrastructure in China, which may not meet regulated-industry compliance (healthcare, finance, defense).”
healthcare·finance·defense 같은 규제 산업에서는 DashScope를 회피하고 자체 호스팅 또는 서구 3rd-party(Fireworks·Together·DeepInfra·Groq)를 쓰는 게 안전하다. byteiota는 자체 호스팅 측면에서 한 가지 강력한 사례를 든다.
“GDPR data residency requirements? Satisfied automatically. Air-gapped environments? Deploy locally and disconnect the internet.”
초기 약 54GB(BF16) 또는 17GB(Q4) 가중치를 한 번 받아두면 인터넷 연결 없이 사내망에서 폐쇄형으로 돌릴 수 있다. 사내 도입 검토 시 라이선스(Apache 2.0)·인프라(self-host vs DashScope)·데이터 거버넌스 세 축을 분리해 평가하는 것이 정석이다.
규제 산업이거나 사내 데이터가 외부로 나가면 안 되는 경우 DashScope API는 회피한다. Fireworks·Together·DeepInfra·Groq 같은 서구 호스팅이 DashScope 대비 ±20% 가격대로 같은 모델을 서빙한다. 완전 air-gapped 환경에서는 가중치를 한 번 받아두고 인터넷 연결을 끊는다.
6. SWE-bench Verified 77%·Terminal-Bench 2.0 59%, 한국어 코드 PR도 잘 풀까?
수치만 보면 깔끔하지만 두 가지 단서가 필요하다. 자체 측정과 공식치의 격차, 그리고 한국어 워크로드 검증 부재다.
공식 vs 자체 측정 — Terminal-Bench의 38.2% 갭
공식 카드는 27B의 Terminal-Bench 2.0을 59.3%로 적지만, r/LocalLLaMA “Local model on coding has reached a certain threshold” 스레드 사용자가 자체 harness로 Q4_K_M·기본 timeout으로 재측정하니 38.2%(34/89)가 나왔다. 21pp 격차다. 원인 분석은 다음과 같다.
“Main factor is benchmark task timeout, then quantization, harness, inference engine.”
벤치마크 timeout, 양자화 수준, harness 구현, 추론 엔진 차이로 동일 모델·동일 벤치마크에서도 결과가 크게 갈린다. 공식 카드 수치만 보고 도입을 결정하기보다 자기 환경에서 한 번 재측정하는 절차가 안전하다.
한국어 코드 PR — 정량 데이터는 비어 있다
Qwen 3.6은 공식 카드 기준 119개 언어를 지원하고 SWE-bench Multilingual 71.3을 기록했지만, 한국어 자연어 PR 설명·이슈 트리아징·한국어 코드 주석 보존 같은 정량 데이터는 공식적으로 공개돼 있지 않다. 아카라이브 알파카 채널의 정성 평가 정도가 한국어 사용자가 참고할 수 있는 가장 가까운 자료다. 채널 글은 “벤치마크 기준으로 Qwen3.6(27B, 35B)이 Qwen3.5 122B 모델 성능에 근접하거나 능가”, “한국어 자연스러움 GPT-4o 수준에 근접”이라고 정리한다.
박재홍의 실리콘밸리 블로그는 Plus 기준 평가이지만 한국어 분석 중 가장 균형 잡힌 톤이다.
“Opus 4.5급 성능을 4분의 1 가격에 제공”, “거의 SOTA급 성능을 훨씬 싼 가격에 제공”. 단 “도구 호출 시 환각 발생”, “30만 토큰 이상에서 컨텍스트 품질 저하”, “100만 토큰 스펙과 실제 효과 간의 괴리”가 있어 “프로덕션 투입 전 직접 검증 필수”다.
수치를 그대로 받아들이지 말고 한국어 PR·이슈 워크로드에서 직접 한 주 정도 시범 운영해 보는 절차가 필요하다.
7. Qwen 3.6 27B를 Cline·OpenCode·Aider 어디에 붙이는 게 가장 효율적일까?
모델 자체보다 어떤 클라이언트에 어떻게 붙이느냐가 일상 워크플로의 체감 차이를 만든다. 단일 GPU 사용자와 멀티 GPU·동시 요청 환경의 권장 조합이 다르다.
가장 단순한 시작: llama.cpp + OpenCode
deskriders.dev 가이드 기준 단일 RTX 4090 사용자가 가장 빠르게 가는 길은 llama-server로 OpenAI 호환 endpoint를 띄우고 OpenCode에 붙이는 방식이다.
llama-server -hf unsloth/Qwen3.6-27B-GGUF:UD-Q4_K_XL --port 9090 -c 262144 -fa -ngl 99~/.opencode/config.json 에는 다음 블록을 합친다.
{
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama.cpp local",
"options": { "baseURL": "http://127.0.0.1:9090/v1" },
"models": {
"qwen36-27b-local": {
"name": "Qwen3.6-27B (Local)",
"limit": { "context": 262144, "output": 32000 }
}
}
}
}
}이 조합은 OpenCode의 Build·Plan agent에서 그대로 모델 선택만 바꿔 쓰면 된다. OpenCode 자체의 멀티 에이전트 활용은 Oh My OpenAgent 솔직 후기에서 따로 정리한 적이 있다.
vLLM은 멀티 GPU·동시 요청 환경
dual 3090 이상이면 vLLM이 throughput을 더 끌어낸다. Chris Dzombak의 vLLM Docker Compose 레시피가 가장 잘 정리된 reference다.
vllm serve Qwen/Qwen3.6-27B --port 8000 --tensor-parallel-size 2 \
--max-model-len 262144 --reasoning-parser qwen3 \
--enable-auto-tool-choice --tool-call-parser hermesreasoning-parser qwen3로 Thinking 출력을 분리하고, tool-call-parser hermes로 OpenCode·Cline의 tool call 포맷과 호환되게 한다.
Cline·Aider 통합
- Cline (VS Code 확장): Settings → API Provider =
OpenAI Compatible→ Base URLhttp://localhost:8000/v1→ Modelqwen3.6-27b→ Context Window 32K 이상. Cline의 시스템 프롬프트가 길어 32768 미만이면 컨텍스트가 빠르게 터진다. - Aider:
aider --openai-api-base http://localhost:8080/v1 --model qwen3.6:27b --architect로 architect/editor 두 역할을 분리하면 27B가 약한 long-horizon tool calling을 회피할 수 있다. - Claude Code:
claude config set --global default_model qwen3.6:27b후--api-base를 vLLM endpoint로 지정. Claude Code 자체 흐름은 클로드 코드 완전 정복에서 별도 다뤘다.
Ollama 라이브러리의 정확한 태그는 qwen3.6:27b다. qwen:27b-v3.6-q4_0 같은 변형 표기는 라이브러리에 등록돼 있지 않으니 주의해야 한다. 또한 vision 기능은 mmproj 파일이 별도로 분리돼 있어 Ollama 패키징이 아직 vision을 자동으로 묶어주지 못한다. 텍스트 코딩만 한다면 ollama run qwen3.6:27b로 충분하지만, 비전·멀티모달이 필요하면 llama.cpp 또는 vLLM에서 mmproj를 직접 로드하는 편이 안정적이다.
Thinking 모드 권장 파라미터
Qwen 공식 모델 카드는 Thinking 활성화 시 다음 샘플링을 권장한다.
temperature=0.6, top_p=0.95, top_k=20, min_p=0.0,
presence_penalty=0.0, repetition_penalty=1.0, max_output=32768vLLM 사용 시 한 가지 주의가 있다.
“Due to the preprocessing of API requests in vLLM, which drops all reasoning_content fields, the quality of multi-step tool use with Qwen3 thinking models may be suboptimal.”
워크어라운드는 Thinking 컨텐츠를 OpenAI 호환 응답에서 추출하지 말고 그대로 패스시키는 것이다. 다단계 tool call이 잦은 워크플로에서는 이 한 줄이 결과 품질을 크게 좌우한다.
8. 한 달 써보니 한계는 뭐였나?
긍정 사례만큼 명확하게 짚어야 할 한계가 여럿 보고됐다. 운영 도입 전에 한 번씩 점검해야 할 다섯 가지를 정리한다.
한계 1 — Terminal-Bench의 자체 측정 38.2%
공식 59.3%는 특정 timeout·harness 조건에서 측정된 값이고, Q4_K_M·기본 timeout 환경에서는 38.2%까지 떨어진다. 출처: r/LocalLLaMA.
한계 2 — silent corruption bug
outsourc-e/qwen36-4090-recipes 보고에 따르면 ik_llama.cpp + cross-vocab speculative decoding 조합에서 약 102 t/s로 빨라 보이지만 실제 출력은 다음과 같이 깨진다.
“Output is unusable for anything structured.”
JSON 중괄호, 리스트 구분자, 따옴표 이스케이프, tool-call 경계가 silently 깨지는 케이스다. 회피책은 mainline llama.cpp + Qwen3.5-4B same-vocab draft 조합, q8 KV cache, 8K/32K 컨텍스트별 권장 설정을 따르는 것이다.
한계 3 — GitHub 오픈 이슈
2026-04-30 시점 QwenLM/Qwen3.6 GitHub Issues에 다음과 같은 미해결 보고가 있다.
- #150 (2026-04-28): Qwen3.6-27B frequently stopped with empty tool call
- #147 (2026-04-24): qwen3.6-35b-a3b 工具调用异常 (tool calling 이상)
- #145 (2026-04-23): Qwen3.5/3.6 시리즈가 권장 sampling으로 reasoning 시 무한루프
- #115 (2026-03-31): Qwen3.5-27B vllm 0.17.0 long context에서 gibberish/repetitive loops
reasoning-parser qwen3 사용·Thinking 활성화·long context 조합을 동시에 쓰면 이 이슈들이 한꺼번에 터질 수 있다. 본격 운영 전 짧은 sanity test를 한 번 돌리는 편이 안전하다.
한계 4 — OOM·벤더 함정
- DFlash 구현은 24GB에서도 OOM
- vLLM INT4는 hybrid attention에서 hang
- TurboQuant TQ3_4S는 런타임 미지원
- mainline llama.cpp의 32K 초과 + q8 KV는 hang (q4 KV 권장)
- CUDA 13.2는 gibberish 출력 (사용 금지)
한계 5 — 영어 창의 글쓰기와 8회+ tool call
theplanettools 48시간 production 후기는 두 가지 영역에서 Claude Opus 4.7과의 격차를 분명히 짚는다. 영어 블로그·마케팅·내러티브 문서는 Opus 4.7 대비 noticeably less polished, 8회 이상 순차 tool call이 필요한 long-horizon agentic 워크플로에서는 logical errors 빈도가 늘어 Claude가 안전하다.
9. 결론: 누가 써야 할까?
페르소나별 권장 옵션과 근거를 한 표로 정리하면 다음과 같다.
| 페르소나 | 권장 옵션 | 근거 |
|---|---|---|
| RTX 3090/4090 보유 로컬 빌더 | 27B Q4 단일 GPU 또는 dual 3090 vLLM | Q4 17GB 단일 GPU 가능, 100K 컨텍스트까지 35~63 t/s 안정 |
| Claude/GPT API 비용 부담 1인 개발자 | 월 100M 토큰 넘으면 즉시 로컬 + Claude hybrid | RTX 4090은 Opus 대비 320M 토큰에 손익분기 |
| 사내 AI 도입 IT 담당자 | Apache 2.0 자체 호스팅 (DashScope 회피) | GDPR 자동 준수·patent grant·air-gapped 가능 |
| Mac M4/M5 Max 사용자 | M4 Max 128GB 이상이면 35B-A3B mlx_lm | 62~86 t/s, 32GB 이하는 9~12B급 권장 |
| 트렌드·벤치마크 소비자 | 공식 카드 표만 인용 + 자체 측정 단서 명시 | SWE-bench Verified 77.2 / Terminal-Bench 2.0 59.3 / SkillsBench 48.2(Opus 추월) |
핵심 요약
Qwen 3.6 27B는 SWE-bench Verified 77.2%로 Claude Opus 4.7과 코드 정확도에서 근접한 첫 오픈 가중치 Dense 모델이지만, Terminal-Bench 2.0의 15pp 격차에서 보듯 long-horizon tool 실행은 여전히 Claude가 앞선다. RTX 4090 한 장이면 Q4_K_M으로 충분히 실용적인 속도(약 40~63 t/s)가 나오고, Apache 2.0 라이선스 덕분에 사내 air-gapped 환경에서도 합법적 운용이 가능하다. 단, DashScope API와 자체 호스팅의 컴플라이언스는 별도 축으로 분리해 검토해야 한다.
- RTX 3090/4090 보유 1인 개발자: Claude Opus 4.7 청구서가 부담스럽다면 단일 GPU에서 27B Q4_K_M부터 시작.
- 사내 AI 도입을 검토하는 IT 담당자: Apache 2.0 + 자체 호스팅으로 GDPR·데이터 주권 이슈를 한 번에 풀 수 있다.
- M4 Max 128GB 사용자: 35B-A3B를 mlx_lm로 올리면 코딩 워크로드에서 60~80 t/s가 안정적으로 나온다.
장점
- + Dense 27B로 397B MoE를 코딩 전 항목에서 추월(SkillsBench는 Opus 4.7도 추월)
- + Q4_K_M 17GB로 RTX 4090 단일 GPU에서 100K 컨텍스트까지 실용적 속도 확보
- + Apache 2.0 + patent grant로 사내 도입·파인튜닝·재배포 모두 합법
- + DashScope·자체 호스팅·서구 3rd-party·Ollama·llama.cpp·vLLM 등 배포 옵션이 다양
단점
- − Terminal-Bench 2.0에서 Opus 4.7 대비 15.4pp 격차 — 8회+ 순차 tool call에 약함
- − Terminal-Bench 자체 측정(38.2%)과 공식치(59.3%) 사이 21pp 갭, harness 의존도 큼
- − Ollama vision 자동 통합 부재, mmproj 파일 별도 처리 필요
- − GitHub 오픈 이슈(empty tool call·무한루프·gibberish loop)로 운영 전 sanity test 필수
- − DashScope API는 Alibaba Cloud 중국 인프라 라우팅 — 규제 산업은 자체 호스팅 권장
1단계 — 하드웨어 확인
RTX 3090/4090 24GB 또는 M4 Max 64GB 이상 통합 메모리 확보. 32GB 이하 Mac은 9~12B급 모델 권장.
2단계 — 가중치 로드 (선택지 2개)
(a) Ollama 사용자: ollama run qwen3.6:27b (텍스트 전용). (b) llama.cpp 사용자: unsloth/Qwen3.6-27B-GGUF UD-Q4_K_XL을 받아 llama-server로 띄운다.
3단계 — OpenAI 호환 endpoint 노출
llama-server 또는 vLLM으로 http://localhost:8000/v1 (또는 9090) 노출. tool-call-parser hermes, reasoning-parser qwen3 옵션 활성화.
4단계 — 코딩 에이전트 클라이언트 연결
OpenCode·Cline·Aider·Claude Code 중 익숙한 도구에 endpoint 연결. Cline은 컨텍스트 윈도우 32K 이상 필수.
5단계 — 짧은 sanity test
GitHub issue #150·#145·#115를 의식해 5분짜리 멀티스텝 tool 작업으로 무한루프·empty tool call·gibberish 여부를 먼저 확인한다.
6단계 — 운영 도입 검토
월 토큰 사용량 ≥ 100M이거나 사내 데이터 air-gapped가 필요하면 RTX 4090 자체 호스팅, 그 미만이면 hybrid(API+로컬)로 시작.
- Qwen3.6-27B 공식 모델 카드
- Qwen3.6-35B-A3B-GGUF 양자화 카드
- byteiota — RTX 4090 Local 리뷰
- Chris Dzombak — Dual RTX 3090 vLLM Docker Compose
- walterra.dev — M4 Max 128GB 35B-A3B 실측
- outsourc-e/qwen36-4090-recipes — silent corruption bug
- QwenLM/Qwen3.6 GitHub Issues
- Anthropic Claude Opus 4.7 발표
- Apache License 2.0 원문
- r/LocalLLaMA — Qwen 3.6 코딩 후기
- theplanettools — Qwen 3.6 vs Gemma 4
- 클리앙 — M4 mini 32GB 로컬 LLM 후기
- Threads @dextune — RTX 3090 실측
- 박재홍 실리콘밸리 — Qwen3.6-Plus 평가
- 아카라이브 알파카 비교분석
Qwen 3.6 27B는 RTX 4080 16GB에서도 돌아가나요?
Ollama로 그냥 ollama run qwen:27b-v3.6-q4_0 하면 되나요?
27B Dense와 35B-A3B MoE 중 뭘 골라야 하나요?
Thinking 모드는 어떻게 켜고 어떤 샘플링을 써야 하나요?
사내 도입할 때 가장 먼저 챙겨야 할 게 라이선스인가요?
Claude Code에 Qwen 3.6 27B를 백엔드로 붙일 수 있나요?
한국어 코드 PR 리뷰도 잘하나요?
1M 컨텍스트라는데 RTX 4090에서도 1M까지 다 쓸 수 있나요?
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.
주제 태그

Gemma 4 완전 정리: 벤치마크, 한국어 성능, 로컬 설치까지
구글 Gemma 4의 모델 구성, 벤치마크 성능, Llama 4·Qwen 3.5 비교, 한국어 실사용 후기, Ollama 로컬 설치법까지 한 글에 정리한다.
읽기
맥북 로컬 AI 서버 끝판왕? Rapid-MLX 설치·성능·Ollama 비교
Rapid-MLX가 무엇인지, 맥북에서 어떻게 설치해 쓰는지, Ollama·LM Studio와 비교하면 무엇이 다른지 최신 기준으로 정리한다.
읽기
클로드 코드 토큰 절약법, 60~90% 줄이는 rtk 사용법 (2026)
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.
읽기