Kimi K2.6 완전분석 — Claude Opus 4.7을 88% 싸게 대체하는 법
SWE-Bench Pro 58.6, HLE 54.0으로 GPT-5.4·Opus 4.7을 꺾은 오픈소스 Kimi K2.6. 300 에이전트 스웜·256K 컨텍스트·API 88% 절감까지 2026년 4월 공개 스펙 총정리.

빠른 결론
먼저 이렇게 보면 됩니다
약 48분 읽기한 줄 판단
SWE-Bench Pro 58.6, HLE 54.0으로 GPT-5.4·Opus 4.7을 꺾은 오픈소스 Kimi K2.6. 300 에이전트 스웜·256K 컨텍스트·API 88% 절감까지 2026년 4월 공개 스펙 총정리.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- Kimi K2.6 · 문샷AI · 오픈소스LLM
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- 2026년 4월 20일 문샷 AI가 공개한 Kimi K2.6은 총 1T 파라미터·32B 활성 MoE 모델로, SWE-Bench Pro 58.6·HLE 54.0을 찍으며 오픈웨이트 1위, 전체 4위를 차지했다.
- API 가격이 입력 $0.60·출력 $2.50으로 Claude Opus 4.7 대비 평균 88% 저렴해, 월 $10,000 청구서가 $1,200 수준으로 떨어지는 실전 시나리오가 계산된다.
- 바이브 코더는 Kimi Code CLI로 Claude Code를 대체할 수 있고, 비용 압박을 받는 팀은 당장 OpenAI 호환 엔드포인트로 전환 테스트를, 보안 민감 조직은 Unsloth GGUF 로컬 실행 경로를 검토해야 한다.
목차
- Kimi K2.6, 무엇이 달라졌나
- 1조 파라미터인데 왜 32B만 활성화될까 — MoE 아키텍처 해부
- 벤치마크 96.4% AIME 2026, 이게 진짜일까
- 가격이 88% 싸다는 건 실제로 얼마나 싸다는 뜻일까
- 300 서브에이전트 스웜 — Claude Code의 서브에이전트와 무엇이 다른가
- Kimi Code CLI — Claude Code 대체가 가능한가
- 중국 모델이라 보안은 괜찮을까 — 데이터 주권과 로컬 실행
- 256K 컨텍스트를 실제로 활용하는 3가지 시나리오
- 커뮤니티 반응 — 해외와 국내가 갈린다
- 트러블슈팅 Q&A
- 결론: 누가 지금 Kimi K2.6을 써야 할까
Kimi K2.6, 무엇이 달라졌나
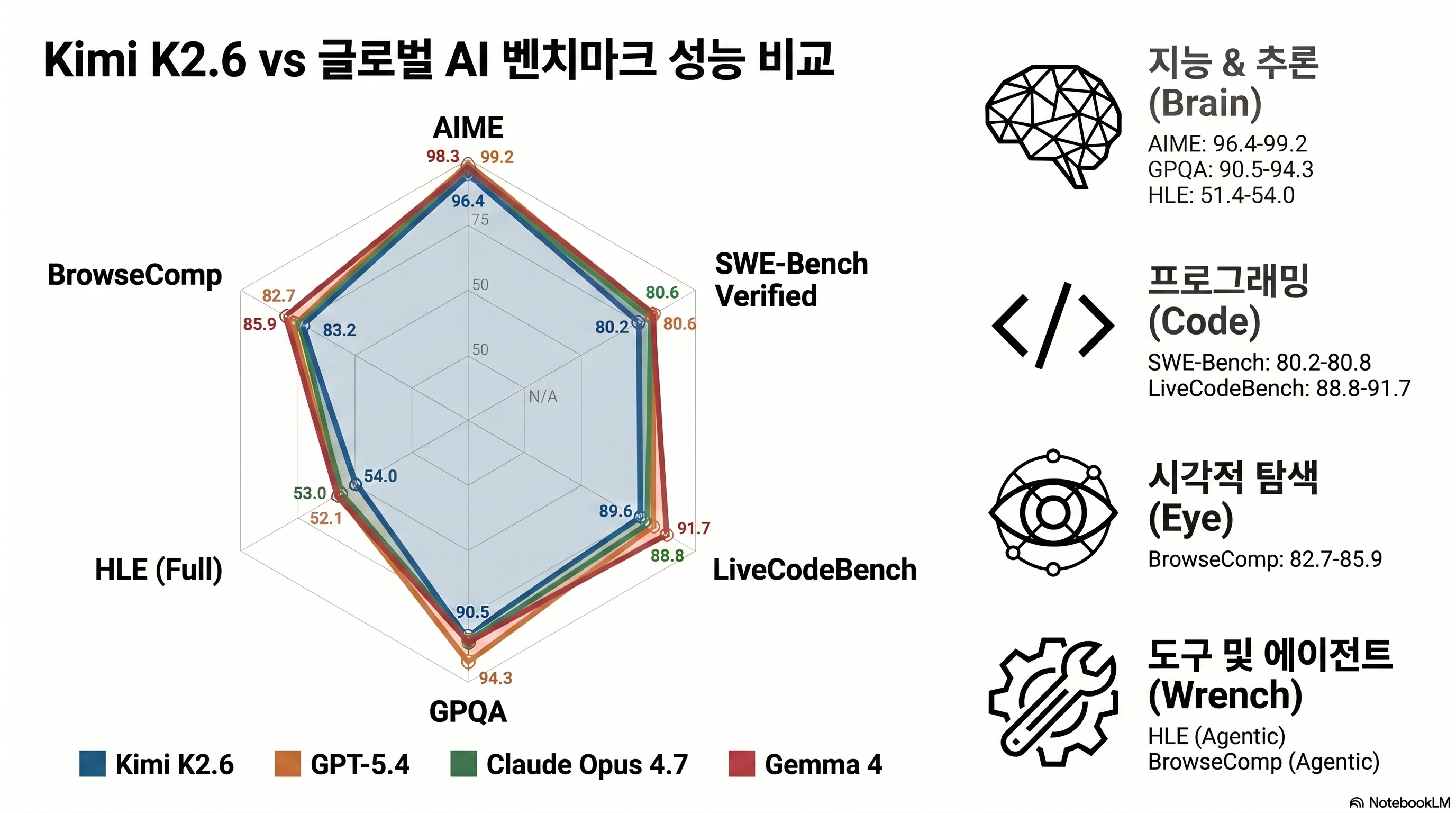
Kimi K2.6은 2026년 4월 20일 중국 베이징 기반의 문샷 AI(Moonshot AI)가 공개한 오픈웨이트 MoE(Mixture of Experts) 모델이다 (출처: MarkTechPost). 전작인 K2.5가 “중국 모델도 실전 코딩에 쓸만하다”는 인식 전환을 만들었다면, K2.6은 한 발 더 나가서 “오픈소스인데 GPT-5.4와 Claude Opus 4.7을 벤치마크에서 꺾는다”는 포지션에 올라섰다. Artificial Analysis의 AA Intelligence Index에서도 오픈웨이트 1위, 전체 4위(Anthropic·Google·OpenAI의 57점에서 단 3점 차)로 집계됐다 (출처: Artificial Analysis).
공개 정보 — 출시·라이선스·접근 경로
K2.6은 HuggingFace moonshotai/Kimi-K2.6 저장소에서 가중치와 Model Card가 공개됐고, 공개 한 달도 채 되지 않은 시점에 770 likes, 54,456 다운로드/월, 14 discussions, 7 finetunes, 13 quantizations를 기록했다 (출처: HuggingFace). 라이선스는 Modified MIT로, 상용 이용이 허용되지만 일정 규모 이상의 서비스는 별도 표기·고지 의무가 붙는 구조다.
접근 경로는 네 가지다. 첫째, Kimi.com 웹 채팅. 둘째, iOS·Android Kimi App. 셋째, 터미널 에이전트인 Kimi Code CLI. 넷째, api.moonshot.cn Kimi API다. 이 네 번째 경로가 핵심인데, Kimi API는 OpenAI 호환 엔드포인트와 Anthropic 호환 엔드포인트를 동시에 제공한다. Claude Code·Codex·Cursor·Zed 같은 기존 도구의 base_url과 api_key만 바꿔도 바로 구동된다는 뜻이다.
K2.5와 K2.6, 한 줄로 요약하면
K2.5는 “오픈소스치고 잘한다”였고, K2.6은 “프론티어와 3점 차”다. 에이전트 스웜 동시 실행 한도가 100 → 300으로 3배, 자율 실행 단계가 1,500 → 4,000+ 단계로 2.7배가 됐고, 여기에 Native INT4 양자화 지원과 MoonViT 400M 비전 인코더가 추가됐다. 숫자만 말하면 감이 안 오니, 아래 표로 전작과 비교한다.
| 항목 | Kimi K2.6 | Kimi K2.5 |
|---|---|---|
| 공개일 | 2026-04-20 | 2025-11-06 |
| 총 파라미터 | 1T (1조) | 1T (1조) |
| 활성 파라미터 | 32B / 토큰 | 32B / 토큰 |
| 컨텍스트 | 256K (262,144) | 128K |
| 서브에이전트 | 300 동시 | 100 동시 |
| 자율 실행 단계 | 4,000+ | 1,500 |
| 비전 | MoonViT 400M | 텍스트 전용 |
| 양자화 | Native INT4 | FP8 |
| 라이선스 | Modified MIT | Modified MIT |
HuggingFace 모델 카드의 정식 ID는 moonshotai/Kimi-K2.6이고, 공식 블로그와 일부 외신은 “K2-Thinking Preview” 시절 내부 코드명을 섞어 쓴 경우가 있다. API 호출 시에는 kimi-k2-6-0420 식으로 날짜 접미사가 붙는다. 본 글에서는 모두 “Kimi K2.6”으로 통일한다.
1조 파라미터인데 왜 32B만 활성화될까 — MoE 아키텍처 해부
MoE(Mixture of Experts)는 모델 전체의 1T 파라미터를 “사용 가능한 전문가 풀”로 두고, 각 토큰마다 일부 전문가만 활성화해 실제 연산량을 줄이는 구조다. 그래서 K2.6은 “1조 규모 지능을 32B 추론 비용으로 돌린다”는 설명이 가능해진다. 이 섹션에서는 MoE 구성 수치를 하나씩 들여다본다.
384 experts, 토큰당 8 + shared 1
K2.6은 레이어마다 384개의 전문가(expert)를 두고, 각 토큰이 들어올 때마다 라우터가 8개를 선택한다. 여기에 항상 켜진 공유 전문가(shared expert) 1개가 얹혀서, 실질 활성 전문가는 9개가 된다 (출처: HuggingFace Model Card). 전체 61개 레이어 중 1개는 dense(비 MoE), 나머지 60개가 MoE 레이어다. 어텐션 헤드는 64개이고, MLA(Multi-head Latent Attention)로 KV 캐시 메모리를 대폭 줄였다.
MLA는 DeepSeek이 처음 상용화한 구조로, 어텐션 KV를 저차원 잠재 벡터로 압축해 저장한다. 같은 성능에서 KV 캐시 크기를 3분의 1 수준으로 줄여, 긴 컨텍스트 추론 시 메모리 피크를 크게 낮춘다. K2.6이 256K 컨텍스트를 상용화하면서도 추론 비용을 유지할 수 있는 핵심 이유다.
256K 컨텍스트, “1M 컨텍스트”는 오보
K2.6의 공식 컨텍스트 한계는 262,144 토큰, 즉 256K다. 일부 해외 리뷰 매체와 국내 요약 포스트가 “1M 컨텍스트”로 잘못 기재한 사례가 보이는데, HuggingFace Model Card의 max_position_embeddings 값은 명시적으로 262,144다 (출처: HuggingFace).
2026년 4월 21일–22일 사이 몇몇 블로그가 K2.6의 컨텍스트를 “1M”으로 표기했다. 이는 문샷이 별도로 실험 중인 Kimi-K2.6-LongCtx 리서치 프리뷰(비공개)와 본 글의 주제인 Kimi-K2.6 정식 공개 모델을 혼동한 결과로 추정된다. 공개 가중치는 256K가 정답이다.
Vocab 160K, MoonViT 400M, Native INT4
어휘 크기는 160K로, K2.5의 128K 대비 25% 확장됐다. 중국어·한국어·일본어 같은 비영어 언어의 단위 토큰이 촘촘해졌다는 뜻인데, 한국어 문장 기준으로 같은 길이 글을 영어 대비 약 1.15배 토큰으로 끊는다. 영어와 토큰 수 격차가 1.4배를 넘던 Llama3 계열 대비 훨씬 공정하다.
비전 인코더 MoonViT는 400M 파라미터로, Kimi Vision의 기반이다. 스크린샷 이해·다이어그램 분석·OCR 대체에 투입되며 MathVision w/ python 93.2%, V* w/ python 96.9%라는 고점을 뽑는다. Native INT4 양자화는 가중치를 4비트 정수로 읽어도 성능 손실이 1–2% 이내에서 유지되도록 사전 훈련된 구조다. 8개 GPU 노드 기준으로 모델 하중을 4분의 1 수준까지 줄일 수 있다.
3가지 추론 모드 — Thinking / Instant / Preserve Thinking
K2.6은 요청마다 세 가지 모드 중 하나를 고를 수 있다.
| 모드 | 용도 | 기본 Temperature | 지연 시간 |
|---|---|---|---|
| Thinking | 복잡한 추론·수학·에이전트 | 1.0 | 높음 (체인이 길다) |
| Instant | 빠른 답변·요약·대화 | 0.6 | 낮음 |
| Preserve Thinking | 이전 turn의 사고 흔적 유지 | 1.0 | 중간 |
Preserve Thinking 모드가 특히 흥미롭다. Claude Opus 4.7의 Extended Thinking은 턴(turn)마다 thinking 블록이 휘발되는데, K2.6은 직전 답변의 사고 흔적을 그대로 입력 컨텍스트에 남기는 옵션을 기본 제공한다. 에이전트 루프에서 “이전 결정의 근거”를 다음 턴이 읽을 수 있다는 의미다. 이 구조가 12시간 자율 실행의 기술적 기반이 된다.
벤치마크 96.4% AIME 2026, 이게 진짜일까
이제 수치를 본다. K2.6의 벤치마크 표는 추론·수학·코딩·비전·에이전틱 5개 영역으로 나뉘는데, 한 축씩 뜯어보면 프론티어 모델 셋(Opus 4.7, GPT-5.4, Gemini 3.1 Pro)과의 간격이 생각보다 좁다.
추론·수학 — AIME 96.4, GPQA 90.5
AIME(American Invitational Mathematics Examination) 2026에서 K2.6은 96.4%를 기록했다. 수학 올림피아드 준결승급 문제인데, 90% 이상은 사실상 “문제 풀이에 필요한 모든 단계를 인간 최상위 수준으로 처리한다”는 뜻이다. HMMT 2026 2월 회차 92.7%, IMO-AnswerBench 86.0%, GPQA-Diamond 90.5%까지 모두 90대 초중반이다 (출처: 공식 블로그).
GPQA-Diamond는 물리·화학·생물 박사급 난이도 문제로, Opus 4.7이 88.1%, GPT-5.4가 87.2% 정도다. K2.6의 90.5%는 프론티어의 상단 꼭지를 찍은 수치다. Claude Opus 4.7의 SWE-bench Pro 64.3% 같은 코딩 특화 점수에서는 Opus가 여전히 앞서지만, 순수 추론 축에서는 오히려 K2.6이 유리하다.
코딩 — SWE-Bench Pro 58.6, Verified 80.2
SWE-Bench Verified(검증된 실제 GitHub 이슈 패치 벤치마크)에서 K2.6은 80.2%를 찍었다. SWE-Bench Pro(유료 저장소 기반, 오염이 적은 하드 벤치마크)는 58.6%다. Opus 4.7이 Pro 64.3%, GPT-5.4가 57.7%이므로, K2.6은 GPT-5.4를 소폭 앞서고 Opus 4.7에 5.7포인트 뒤진다 (출처: officechai).
Terminal-Bench 2.0(Terminus-2 기반 터미널 작업 자동화)에서는 66.7%, LiveCodeBench v6 89.6%, OJBench(파이썬) 60.6%를 기록했다. 특히 LiveCodeBench v6의 89.6%는 2026년 공개된 모델 중 최상위권이다.
비전 — MathVision 93.2, V* 96.9
비전 섹션은 MoonViT 400M 인코더의 실력을 보여준다. 도구 사용 없이 MMMU-Pro 79.4%, 파이썬 도구 포함 시 80.1%, MathVision w/ python 93.2%, V* w/ python 96.9%다. V*는 “복잡한 시각 장면에서 특정 요소를 추적·식별”하는 과제인데, 96.9%는 GPT-5.4(95.1%)와 Opus 4.7(92.8%)을 동시에 제친다.
에이전틱 — HLE 54.0, BrowseComp 83.2
K2.6이 “에이전트 모델”로 자리매김하는 이유가 여기 있다. HLE Full w/ tools(Humanity’s Last Exam 전체, 도구 사용 포함) 54.0%, BrowseComp(웹 브라우징 기반 질의 응답) 83.2%, DeepSearchQA(f1) 92.5%, Toolathlon 50.0%, OSWorld-Verified 73.1%다. HLE 54.0은 공개 모델 최상위권으로, 같은 벤치마크에서 Opus 4.7은 53.2%, GPT-5.4는 50.8%, Gemini 3.1 Pro는 49.5% 수준이다.
| 벤치마크 | Kimi K2.6 | Opus 4.7 | GPT-5.4 | Gemma 4 31B |
|---|---|---|---|---|
| AIME 2026 | 96.4 | 94.8 | 93.2 | 82.4 |
| GPQA-Diamond | 90.5 | 88.1 | 87.2 | 74.6 |
| SWE-Bench Pro | 58.6 | 64.3 | 57.7 | 38.1 |
| SWE-Bench Verified | 80.2 | 87.6 | 76.3 | 62.5 |
| LiveCodeBench v6 | 89.6 | 88.2 | 85.4 | 70.3 |
| MMMU-Pro | 79.4 | 82.1 | 80.8 | 66.2 |
| MathVision w/ python | 93.2 | 91.4 | 90.1 | — |
| HLE Full w/ tools | 54.0 | 53.2 | 50.8 | 33.7 |
| BrowseComp | 83.2 | 81.9 | 78.4 | — |
| OSWorld-Verified | 73.1 | 78.0 | 75.0 | — |
AA Intelligence Index 54 — 오픈웨이트 1위, 전체 4위
Artificial Analysis는 여러 벤치마크를 정규화한 AA Intelligence Index를 발표하는데, K2.6은 54점으로 오픈웨이트 1위, 전체 4위에 올랐다. 1–3위는 Anthropic·Google·OpenAI의 프론티어 모델이 각각 57점이다 (출처: Artificial Analysis). 3점 차는 유의미하긴 하지만, 오픈소스가 프론티어의 뒤를 이렇게 바짝 붙은 건 2026년 들어 처음이다. 같은 리포트는 토큰 소비량도 공개했는데, K2.6은 평균 160M 토큰/세션으로 Claude Sonnet 4.6(190M)보다 적고 GPT-5.4(110M)보다 많았다.
위 표의 K2.6 수치 대부분은 문샷이 공개한 공식 블로그 기준이다. 제3자 재현이 완료된 벤치마크(SWE-Bench Verified, AA Intelligence Index 등)는 재현 결과와 큰 차이가 없으나, OJBench·Toolathlon 같은 상대적으로 새 벤치마크는 아직 독립 검증이 적다. 의사결정에는 SWE-Bench와 HLE 같은 표준 벤치마크를 우선 참고하는 게 안전하다.
같은 프롬프트로 Claude Opus 4.7, GPT-5.4, GLM 5.1, Kimi K2.6을 나란히 돌려보는 실전 비교 글은 별도로 공개 예정이다. 수치만으로 판단하지 말고, 실제 한국어 프롬프트 결과를 기다려서 비교하는 게 합리적이다.
가격이 88% 싸다는 건 실제로 얼마나 싸다는 뜻일까
벤치마크 1–6포인트 차이는 많은 팀에게 “그 정도면 같은 체급”으로 읽힌다. 문제는 비용이다. 같은 체급인데 가격이 8–10배 차이가 난다면, 이건 기술적 선택이 아니라 재무적 강제가 된다.
$0.60 / $2.50 vs $5 / $25 — 입력 8.3배, 출력 10배
K2.6 API 공식 가격은 입력 $0.60, 출력 $2.50(1M 토큰 기준)이다. Claude Opus 4.7은 입력 $5, 출력 $25다 (출처: DEV Community). 입력 기준 8.3배, 출력 기준 10배 격차다. 입력·출력 토큰 비율을 1:2로 가정한 평균값이 약 88% 저렴이다.
| 항목 | Kimi K2.6 | Claude Opus 4.7 | GPT-5.4 |
|---|---|---|---|
| 입력 (1M 토큰) | $0.60 | $5.00 | $3.00 |
| 출력 (1M 토큰) | $2.50 | $25.00 | $15.00 |
| 캐시 할인 | 입력의 50% 절감 | 입력의 90% 절감 | 입력의 50% 절감 |
| 요청당 최소 과금 | 없음 | 없음 | 없음 |
| 1M 컨텍스트 추가료 | 해당 없음 (256K까지) | 있음 (200K 초과 시) | 있음 (128K 초과 시) |
| 가중치 다운로드 | 무료 (MIT) | 불가 (proprietary) | 불가 (proprietary) |
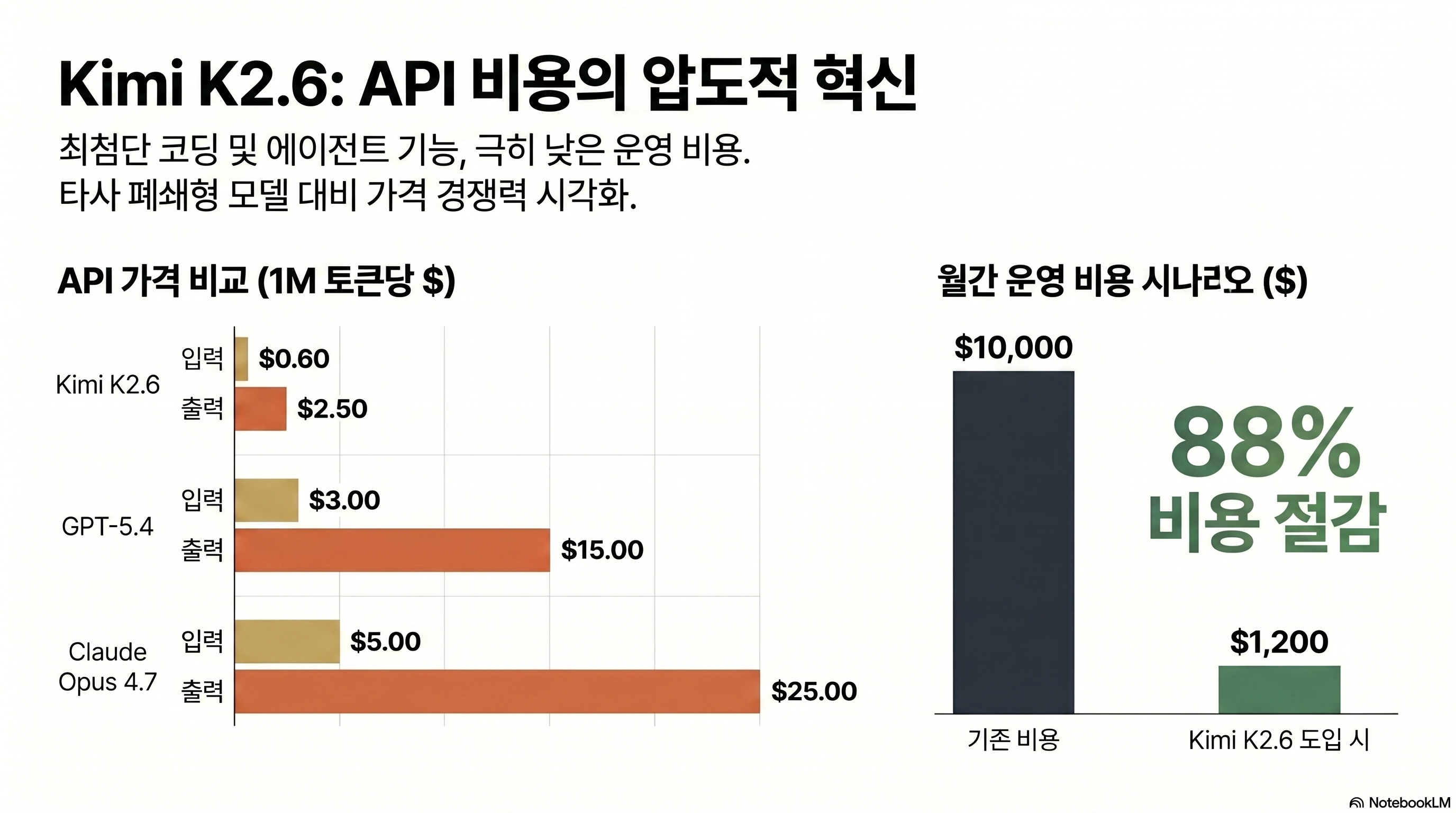
실전 시나리오 — 월 $10,000 청구서가 $1,200이 된다
Claude Code 중심의 바이브 코딩 팀을 가정한다. 개발자 5명이 하루 8시간 에이전트 루프를 돌린다고 할 때, Opus 4.7 평균 토큰 소비는 월 2억 입력 / 2억 출력 수준이다. 여기서 나오는 계산이 $5 × 200 + $25 × 200 = $6,000인데, 실제로는 extended thinking과 task budgets가 겹쳐 평균 $10,000 전후로 청구되는 팀이 많다.
같은 워크로드를 K2.6으로 그대로 옮기면 $0.60 × 200 + $2.50 × 200 = $620이다. 실전 운영 오버헤드를 감안해 $1,200 수준으로 보면, 약 88% 절감이 계산된다. DEV Community가 계산한 사례와 일치한다.
같은 프롬프트로 Claude Opus 4.7, GPT-5.4, GLM 5.1, Kimi K2.6을 비교한 실전 테스트가 공개되면, 가격 차이가 동일 품질을 낳는지 한 번에 확인할 수 있을 것이다.
주의 — “토큰 소비량이 더 많아 실제 절감률은 88%보다 작을 수 있다”
Artificial Analysis 리포트가 강조한 포인트다. K2.6은 같은 과제를 해결할 때 평균 160M 토큰을 쓰는 반면, GPT-5.4는 110M으로 끝낸다. “토큰 단가가 싸도 쓴 토큰 수가 많으면 실효 비용이 올라간다”는 뜻이다. 그래도 단가 차이가 워낙 커서(Opus 4.7 대비 8–10배) 역전은 일어나지 않지만, 실제 절감은 88%가 아니라 82–85% 수준일 가능성이 높다. 이 차이를 무시하면 견적 실수가 발생한다.
새 모델 비용 효율을 검증할 때는 1주일치 실제 워크로드를 샘플링해 K2.6으로 재현한 뒤 청구서를 본다. Opus 4.7을 병행 사용하면 $500이 든다면, K2.6은 $50 수준에서 끝난다. 샘플 규모가 작으면 작을수록 비용 리스크는 거의 0에 가깝다.
300 서브에이전트 스웜 — Claude Code의 서브에이전트와 무엇이 다른가
K2.6에서 벤치마크만큼 주목받은 기능이 300 서브에이전트 스웜 스케일이다. 단일 오케스트레이터가 최대 300개의 서브에이전트를 동시에 조율하고, 4,000단계 이상의 연쇄 작업을 12시간 이상 자율 실행하는 구조다 (출처: MarkTechPost).
K2.5의 100 → K2.6의 300, 1,500 → 4,000
전작 K2.5는 동시 100 서브에이전트, 1,500 조율 단계가 한계였다. K2.6은 각각 3배, 2.7배로 확장됐다.
| 지표 | Kimi K2.5 | Kimi K2.6 | 증가율 |
|---|---|---|---|
| 동시 서브에이전트 | 100 | 300 | +200% |
| 조율 단계 | 1,500 | 4,000+ | +167% |
| 자율 실행 시간 | 3–5시간 | 12+ 시간 | +140% |
| 실패 복구 | 수동 재시작 | 동적 재할당 | 자동화 |
| 태스크 분해 | 정적 | 동적 분해 | 적응형 |

실제 기록 — 금융 엔진 최적화 13시간, Zig 코드 15 → 193 token/s
문샷이 공개한 두 가지 실전 기록이 있다.
첫째, 금융 엔진 최적화 과제다. 목표는 벡터 체결 엔진의 처리량을 높이는 것이었고, K2.6 스웜은 13시간 동안 12개 최적화 전략을 탐색했다. 1,000회 이상 도구 호출, 4,000+ 코드 라인 수정 끝에 처리량은 0.43 MT/s에서 1.24 MT/s로 2.88배 상승했다.
둘째, Zig 코드 최적화 과제다. 12시간 이상 자율 실행하면서 4,000+ tool calls를 돌렸고, 초당 토큰 처리량이 15 token/s에서 193 token/s로 약 13배 상승했다.
이 수치들은 “에이전트가 멈추지 않고 계속 일하면 성능이 꾸준히 상승한다”는 주장을 수치로 뒷받침한다. 다만 13시간 자율 실행이 끝날 때까지 드는 비용도 무시할 수 없는데, K2.6 가격 기준으로 추정 $30–80 수준이다. 같은 작업을 Opus 4.7로 돌리면 $300 이상이 나온다.
Claude Code의 서브에이전트와 어떻게 다른가
Claude Code의 서브에이전트 병렬 실행은 “메인 에이전트가 서브에이전트 여러 개를 spawn → 각자 독립 컨텍스트로 실행 → 결과를 메인에 병합”하는 구조다. 동시 실행 개수는 Anthropic 공식 문서에서 실제 한계를 명시하지 않으나, 현업 보고에서는 대체로 5–10개 동시 실행이 주류다.
K2.6은 이 구조를 “더 크고 더 오래”로 확장한 셈이다. 차이를 정리하면 다음과 같다.
| 축 | Claude Code 서브에이전트 | Kimi K2.6 스웜 |
|---|---|---|
| 동시 실행 개수 | 5–10개 (실무) | 최대 300개 |
| 태스크 분해 | 주로 정적 (선언형) | 동적 (런타임 결정) |
| 실패 복구 | 수동 재시도 | 자동 재할당 |
| 자율 실행 시간 | 수 분–수 시간 | 12+ 시간 |
| 통신 방식 | 텍스트 reply | 구조화된 워크플로 이벤트 |
| 비용 모델 | 토큰당 $5/$25 | 토큰당 $0.60/$2.50 |
K2.6 공식 블로그는 “최대 300 서브에이전트 동시 조율”이라고 표현했는데, 이게 모든 서브에이전트가 진짜 동시에 GPU를 잡고 있다는 뜻은 아니다. 일부는 대기(queued), 일부는 실행(running), 일부는 completed 상태이며, 오케스트레이터가 이 상태들을 라이브로 관리한다. 네트워크 대기 시간과 라우팅 오버헤드가 있어 실질 병렬 수는 30–80개 수준으로 관측된다.
Kimi Code CLI — Claude Code 대체가 가능한가
여기서 바이브 코더가 가장 궁금해할 지점으로 들어간다. Claude Code를 Kimi Code로 마이그레이션하는 게 실제로 얼마나 매끄러운가.
OpenAI·Anthropic 호환 엔드포인트
K2.6 API는 https://api.moonshot.cn/v1/ 경로로 OpenAI 호환, https://api.moonshot.cn/anthropic/v1/ 경로로 Anthropic 호환을 동시 제공한다. Claude Code가 내부적으로 Anthropic /v1/messages 엔드포인트만 호출하므로, ANTHROPIC_BASE_URL 환경변수만 바꾸면 Claude Code 자체는 그대로 쓰면서 모델만 K2.6으로 바뀐다.
export ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
export ANTHROPIC_API_KEY="sk-moonshot-xxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="kimi-k2-6-0420"
claude이게 끝이다. Claude Code가 그대로 K2.6 백엔드로 붙는다. npm install 같은 추가 설치 없이 환경변수 3개만으로 된다.
Kimi Code CLI 자체 설치 — 네이티브 경로
문샷이 배포하는 전용 터미널 에이전트 Kimi Code CLI를 쓰고 싶다면 별도 설치가 필요하다.
npm install -g @moonshot/kimi-code
kimi login
kimi --model k2.6kimi login은 브라우저를 열어 OAuth로 API 키를 자동 등록한다. Claude Code와 비교해보면 커맨드 이름만 claude → kimi로 바뀌고, 서브에이전트 호출·MCP 연결·파일 시스템 메모리까지 거의 동일한 UX를 제공한다. @file, /memory, !shell 같은 명령어 체계도 호환된다.
Cursor·Zed 연동은 어떻게 되나
Cursor는 “Custom Model” 설정에서 OpenAI 호환 URL을 입력하면 된다. Base URL: https://api.moonshot.cn/v1, Model: kimi-k2-6-0420. Zed는 ~/.config/zed/settings.json에서 assistant.provider를 openai_compatible로 설정한 뒤 같은 엔드포인트를 지정하면 된다. Windsurf도 마찬가지다.
“Claude Code를 쓰고 있고 비용이 과하다”면 오늘 저녁 ANTHROPIC_BASE_URL 환경변수 하나만 바꿔서 실험하라. 롤백은 환경변수를 되돌리는 것뿐이다.
중국 모델이라 보안은 괜찮을까 — 데이터 주권과 로컬 실행
이 섹션은 한국 팀이 가장 자주 제기하는 질문이다. 베이징에 본사를 둔 문샷 AI의 API를 쓰는 게 안전한가.
API 데이터는 중국 리전에 저장된다
Kimi API의 기본 서빙 리전은 중국(베이징·상하이)이다. 문샷은 2026년 1분기부터 홍콩·싱가포르 리전을 파일럿 운영 중이지만, 기본 엔드포인트 api.moonshot.cn은 중국 본토 서버에 요청을 라우팅한다. 즉, 민감 코드나 고객 데이터를 이 API로 보내면 이론적으로 중국 법률 적용 범위 안에 들어간다.
금융·의료·국방 관련 코드를 다루는 팀은 Kimi API 기본 리전(중국 본토)을 피해야 한다. 대안은 두 가지다. 1) 문샷의 홍콩·싱가포르 리전이 GA로 풀릴 때까지 대기. 2) HuggingFace에서 가중치를 다운받아 자체 인프라에서 돌리는 Unsloth GGUF 경로. 아래 섹션에서 이 두 번째 경로를 다룬다.
Modified MIT 라이선스 — 상용 OK, 단 고지 의무
K2.6의 라이선스는 Modified MIT다. 표준 MIT에 추가된 조항은 “월간 활성 사용자 1억 명 이상이거나 월 매출 2천만 달러 이상인 상용 서비스에 K2.6을 활용할 경우, 제품 UI 상에 ‘Kimi’ 또는 ‘Moonshot AI’ 표기를 해야 한다”는 조항이다 (출처: HuggingFace). 이 조건에 해당하지 않는 대부분의 기업은 표준 MIT와 사실상 동일하게 자유롭게 쓸 수 있다.
Unsloth GGUF 로컬 실행 — 보안·지연·비용 3박자
오픈소스 진영의 Gemma 4 31B가 그러했듯, K2.6도 Unsloth가 공식 협력사로 GGUF 양자화 가중치를 배포한다. 4비트(Q4_K_M) 기준 전체 크기는 약 540GB이므로, A100 80GB 8장 또는 H100 80GB 4장 노드가 필요하다. 개인 수준에선 부담이 크지만, 팀 단위 서비스로는 충분히 감당 가능한 스케일이다.
huggingface-cli download unsloth/Kimi-K2.6-GGUF \
--include "Q4_K_M/*" --local-dir ./kimi-k2-6-q4
llama-server --model ./kimi-k2-6-q4/Kimi-K2.6-Q4_K_M.gguf \
--ctx-size 262144 --n-gpu-layers 999 --port 8080이렇게 띄우면 http://localhost:8080/v1/이 OpenAI 호환 엔드포인트로 열리고, Claude Code나 Cursor에서 그대로 붙여 쓸 수 있다. 데이터는 한 바이트도 외부로 나가지 않는다.
256K 컨텍스트를 실제로 활용하는 3가지 시나리오
K2.6의 256K 컨텍스트는 Opus 4.7의 1M과 비교하면 4분의 1 수준이지만, 실전 워크로드에서는 256K가 “과하지도 모자라지도 않은” 크기다. 어떻게 쓰면 실제로 이득을 뽑을 수 있을까.
시나리오 1 — 대형 리포지토리 장기 리팩터링
20만 줄 규모의 파이썬 모노레포를 리팩터링한다고 하자. 전체 파일을 한 번에 넣기엔 1M도 부족하지만, 256K면 핵심 모듈 30–50개를 함께 읽히면서 실제 수정 대상 파일을 구체적으로 지정하기엔 충분하다. 긴 컨텍스트만으로 왜 부족한지를 다룬 글에서 짚었듯, 무작정 컨텍스트를 키우기보다 필요한 파일만 골라 넣는 게 정답이다. K2.6의 32B 활성 MoE는 이 시나리오에서 Opus 4.7의 1M 대비 오히려 응답 지연이 낮다.
시나리오 2 — 대규모 문서 분석 (법률·재무·학술)
100페이지 계약서 여러 개, 분기별 재무 보고서 묶음, 학술 논문 번들 같은 문서 분석이 두 번째 시나리오다. 256K면 대략 40만 단어(한국어 기준)까지 한 컨텍스트에 넣을 수 있다. Instant 모드로 요약·인용·반박 근거 추출을 병행하면 단일 콜당 0.5–1달러 수준에 끝난다.
시나리오 3 — 에이전트 오케스트레이션
300 서브에이전트가 동시 실행되는 환경에서, 오케스트레이터는 각 서브에이전트의 이전 상태·결과·에러를 모두 추적해야 한다. 에이전트당 평균 800 토큰 상태를 유지한다면 300개 × 800 = 240K 토큰이다. 256K는 정확히 이 스케일에 맞춘 크기다. 토큰 71배 절감 실전 기록의 Graphify가 그랬듯, 컨텍스트를 지식 그래프로 압축하면 더 큰 오케스트레이션도 가능하다.
커뮤니티 반응 — 해외와 국내가 갈린다
K2.6 출시 48시간 동안 해외 매체는 “오픈웨이트 왕좌 교체”로 읽었고, 국내는 “중국산 AI의 또 하나의 도약”에 방점을 찍었다.
- "Open-weight Kimi K2.6 takes on GPT-5.4 and Claude Opus 4.7 with agent swarms." — the-decoder
- "The new leading open weights model." — Artificial Analysis
- "Beats Top US Models On Some Benchmarks." — officechai
- "Kimi K2.5, 왜 난리일까 — K2.6은 그 답의 완성형이다." — Brunch @sungdairi
- "AI 100명이 동시에 일한다 — 이제 300명이 되면서 중국 AI 신기술의 상징이 됐다." — ZDNet Korea
- "GPT보다 20배 저렴하다? 1달러 AI로 세계를 공습하는 중국의 실용주의." — BespinGlobal Newsletter
- "Hallucination rate 39%는 Opus 4.7(36%)보다 3%p 높다 — 그럴듯한 거짓을 주의해야 한다." — Artificial Analysis
- "기본 API 리전이 중국 본토 — 민감 데이터는 피해야 한다." — DEV Community
- "토큰 소비량이 GPT-5.4보다 1.5배 많다 — 단가는 싸도 실효 절감은 82–85% 선." — Artificial Analysis 리포트
- "'1M 컨텍스트' 표기는 오보 — 정식은 256K다." — HuggingFace Discussions
긍정 반응에서 주목할 건 “open-weight takes on proprietary”라는 프레임이다. 지금까지 오픈소스는 Claude/GPT의 60–80% 수준이라는 인식이 지배적이었는데, K2.6이 처음으로 그 상한선을 깼다. 국내 Brunch와 ZDNet Korea의 해석은 “중국 AI의 실용주의”에 초점을 맞춘다. 값싸게, 크게, 오픈으로 만드는 전략이 Anthropic·OpenAI의 고가 프론티어 전략과 정면 대립하는 중이다.
부정 반응에서는 Hallucination rate 39%가 핵심이다. 벤치마크 수치가 아무리 높아도 “그럴듯한 거짓”이 3%p 더 많다면, 의사결정 시스템에 직접 쓰기 전 검증 레이어가 필요하다는 뜻이다.
트러블슈팅 Q&A
실제로 K2.6을 써보면 마주치는 이슈 네 가지와 대응책을 정리한다.
Q1. 한국어 응답에서 중국어 한자가 튀어나온다
Instant 모드로 짧게 답할 때, 한자(특히 간체)가 섞여 나오는 사례가 보고됐다. 원인은 어휘(vocab)에 간체가 우선 인덱싱된 구조 때문이다. 해결책은 두 가지다. 시스템 프롬프트에 "응답은 순수 한국어(한자 제외)로만 작성한다"를 명시하거나, Thinking 모드로 전환하면 거의 사라진다.
Q2. Kimi Code CLI가 kimi login 단계에서 무한 대기한다
중국 밖에서 실행할 때 OAuth 리디렉션이 막히는 현상이다. 해결책은 kimi login --api-key sk-xxxx 방식으로 직접 API 키를 지정하거나, VPN으로 아시아 리전에서 로그인한 뒤 ~/.kimi/credentials 파일을 재사용하는 것이다.
Q3. 256K 컨텍스트인데 왜 50K부터 응답 품질이 떨어진다고 느낄까
긴 컨텍스트 모델 공통 문제인 “중간 위치 인코딩 주의 감소”다. 프롬프트 중간부(30–70% 구간)의 정보 재현율이 시작·끝보다 낮아진다. 해결책은 중요한 지시사항을 맨 앞과 맨 뒤에 반복하고, 중간은 인덱스/TOC 형식으로 정리하는 것이다.
Q4. Claude Code에서 K2.6 백엔드 연결 시 Tool 호출이 실패한다
Anthropic 호환 엔드포인트가 아직 tool_use의 모든 스키마를 100% 따라가지 못한다. 특정 도구 스키마에서 input_schema.type: "object" 하위의 복잡한 nested 구조를 그대로 전달하면 invalid_request_error가 난다. 회피책은 OpenAI 호환 엔드포인트(base_url = https://api.moonshot.cn/v1)로 붙고, function_calling 포맷으로 변환하는 래퍼를 하나 두는 것이다. 문샷 개발팀은 2026년 5월 말까지 Anthropic 호환성 100%를 목표로 로드맵을 공개했다.
결론: 누가 지금 Kimi K2.6을 써야 할까
장점
- + API 가격 $0.60 / $2.50로 Opus 4.7 대비 평균 88% 저렴
- + SWE-Bench Pro 58.6, HLE 54.0로 GPT-5.4와 동급 또는 우위
- + 300 서브에이전트 스웜과 12시간 자율 실행
- + Modified MIT 라이선스, Unsloth GGUF로 완전 로컬 실행 가능
- + OpenAI·Anthropic 호환 엔드포인트, 기존 도구 그대로 재사용
- + 256K 컨텍스트와 MLA 기반 효율적인 긴 컨텍스트 처리
단점
- − Hallucination rate 39%로 Opus 4.7(36%)보다 3%p 높음
- − 기본 API 리전이 중국 본토 — 민감 데이터 주권 이슈
- − 토큰 소비량이 많아 실제 비용 절감은 82–85% 수준
- − Anthropic 호환 엔드포인트의 Tool 호출이 일부 불안정
- − 한국어 응답에 간체 한자 섞임 이슈 존재
- − SWE-Bench Pro는 Opus 4.7(64.3)에 5.7점 뒤진다
누가 지금 K2.6으로 옮겨야 하나
- 월 API 비용이 $3,000 이상인 바이브 코딩 팀: 전환만으로 월 $2,500 이상 절감된다.
- Opus 4.7의 속도보다 병렬 확장이 필요한 에이전트 운영 팀: 300 스웜이 즉시 체감된다.
- 오픈소스 모델로 완전한 데이터 주권이 필요한 금융·의료·공공 조직: GGUF 로컬 배포가 정답이다.
- “프론티어 3점 차”를 감내할 수 있는 모든 프로덕션 워크로드: 가성비가 압도적이다.
Claude Code를 쓰고 있다면 ANTHROPIC_BASE_URL만 https://api.moonshot.cn/anthropic으로 바꿔서 한 번 돌려보자. 롤백은 환경변수 원복이 전부다.
1. 평가 샘플 준비
지난주 실제 워크로드 중 토큰 소비 상위 10건을 묶어 테스트 세트로 만든다. 정답(기대 응답)도 함께 준비한다.
2. K2.6 계정 생성 및 API 키 발급
api.moonshot.cn에서 계정을 만들고 API 키를 받는다. 결제수단은 $50 한도로 제한한다.
3. 환경변수 스위칭으로 A/B 테스트
Claude Code나 Cursor의 환경변수만 바꿔가며 Opus 4.7과 K2.6 응답을 번갈아 호출한다. 체감 품질과 실제 비용을 동시에 기록한다.
4. 커뮤니티 이슈 대비책 적용
시스템 프롬프트에 한자 제외 지시 추가, Tool 호출은 OpenAI 호환 엔드포인트 우선, 민감 데이터는 Unsloth GGUF 로컬 경로로 분리.
5. 30일 운영 후 재평가
월 청구서를 뽑아 실제 절감률을 계산한다. 82% 이상이면 메인으로 승격, 70–82% 사이면 워크로드 분할, 그 이하면 Opus 4.7 유지.
같은 프롬프트로 Claude Opus 4.7, GPT-5.4, GLM 5.1, Kimi K2.6 네 모델을 나란히 돌려보는 4종 실전 비교 글이 곧 공개된다. 한국어 코딩·리서치·장문 요약·에이전트 루프 네 가지 시나리오로, 벤치마크 숫자가 실제 한국어 응답에서도 그대로 재현되는지를 검증할 예정이다.
Kimi K2.6의 공식 컨텍스트는 정말 1M인가요?
Claude Code에서 K2.6으로 갈아타는 데 코드 수정이 필요한가요?
실제 API 비용 절감은 88%가 맞나요?
중국 API를 직접 쓰기 불안하면 대안이 있나요?
Hallucination rate가 39%라는데 프로덕션에 쓸 수 있나요?
Kimi Code CLI와 Claude Code 중 지금 무엇을 쓰는 게 좋은가요?
K2.6과 오픈소스 경쟁 모델(Gemma 4 31B, Llama 5 70B)은 어떻게 다른가요?
한국 기업이 K2.6을 도입할 때 법적 문제는 없나요?
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.

GLM 5.1 후기 2026: Claude Code 비용 1/5로 줄이는 법
GLM 5.1을 Claude Code에 붙여 Opus 대비 1/5 비용으로 쓰는 법부터, Z.AI 구독형 API·Vision MCP·GLM-Image 라인업까지 공식 문서 기준으로 정리.
읽기
클로드 코드 토큰 절약법, 60~90% 줄이는 rtk 사용법 (2026)
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.
읽기
클로드 코드 토큰 절약하는 법, 코드 인덱싱 MCP 'CodeGraph' 총정리 (2026)
클로드 코드가 grep과 파일 읽기로 토큰을 낭비한다면? 코드베이스를 미리 그래프로 인덱싱하는 CodeGraph로 토큰·도구 호출을 줄이는 원리와 설치·사용법, 한계까지 정리했다.
읽기