RAG는 끝났다? Karpathy가 제안한 LLM 위키의 정체 (2026 총정리)
RAG 한계에 부딪혔다면? Karpathy가 공개한 LLM 위키 패턴을 뜯어봤다. 3계층 아키텍처, 95% 토큰 절감, 2주 만에 폭발한 생태계까지 2026년 개념편 총정리.

빠른 결론
먼저 이렇게 보면 됩니다
약 38분 읽기한 줄 판단
RAG 한계에 부딪혔다면? Karpathy가 공개한 LLM 위키 패턴을 뜯어봤다. 3계층 아키텍처, 95% 토큰 절감, 2주 만에 폭발한 생태계까지 2026년 개념편 총정리.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- RAG 대안 · LLM 지식베이스 · Karpathy LLM 위키
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- Andrej Karpathy가 2026년 3월 말 공개한 gist 하나가 1,600만 회 조회를 찍으며 “RAG 이후”를 논하는 기준점이 됐다. 핵심은 벡터 DB를 버리고 마크다운 위키에 지식을 누적 컴파일하는 file-over-app 철학이다.
- 3계층(Raw / Wiki / Schema) 분리 덕분에 쿼리당 약 95% 토큰 절감이 보고되고, gist 공개 2주 만에 5개 파생 구현체가 쏟아지며 생태계가 먼저 움직였다.
- 다만 규모 임계치·환각 오염·린트 누락 같은 함정이 있어 “RAG with extra steps”라는 비판도 만만치 않다. 이 글은 2026년 4월 시점의 개념·구현·한계를 한 번에 정리한다.
목차
- Karpathy가 갑자기 'LLM 위키'를 왜 꺼냈을까?
- RAG는 왜 개인 지식 관리에 맞지 않을까?
- 긴 컨텍스트만으로는 왜 안 될까?
- LLM 위키의 3계층 아키텍처는 어떻게 작동하나?
- RAG와 LLM 위키는 정확히 뭐가 다를까?
- LLM 위키 생태계는 지금 얼마나 폭발했나?
- 실제로 쓰는 사람들은 뭐라고 하나?
- LLM 위키의 한계 3가지 — 무엇을 조심해야 하나?
- 지금 이 글을 읽는 당신은 뭐부터 해야 하나?
- 자주 묻는 질문
Karpathy가 갑자기 ‘LLM 위키’를 왜 꺼냈을까?
Andrej Karpathy가 2026년 3월 말 깃허브 gist 하나를 올렸다. 제목은 평범했다. “How I use LLMs to manage my knowledge base”. 그런데 이 글이 6주 만에 1,600만 회 조회를 기록했다 (출처: remio.ai 분석). OpenAI 공동 창업자이자 Tesla AI 디렉터 출신의 “사용 후기”치고는 유난한 반응이었다.
단순 팁 글이 패러다임 논쟁으로 번진 이유
gist에 담긴 주장은 한 문장으로 요약된다. “RAG는 stateless 시스템이고, 개인 지식 관리에는 stateful 컴파일이 맞다” (출처: Karpathy gist). RAG(Retrieval-Augmented Generation)는 질문이 들어올 때마다 원본 문서를 잘라 벡터 DB에서 꺼내 해석한다. 반면 Karpathy의 패턴은 수집 시점에 LLM이 한 번 종합(compile)해 사람이 읽는 마크다운으로 저장한다. 그다음부터는 꺼내 쓸 뿐이다.
VentureBeat는 이 주장을 “Karpathy가 RAG 파이프라인을 우회하는 지식 베이스 아키텍처를 공개했다”라고 요약했다 (출처: VentureBeat 커버리지). 핵심은 ‘우회’라는 단어였다. 해석, 대체, 보완이 아니라 우회. 전제 자체를 갈아엎는다는 뜻이다.
논쟁의 지형 — 지지자와 반대자
지지자는 “개인 지식 관리에서 RAG 체험이 왜 그렇게 형편없었는지 드디어 말로 설명됐다”고 했다. 반대자는 “Semantic Web 재탕, 작을 때만 동작하는 구조인데 RAG의 대안처럼 포장됐다”고 했다. 양쪽 다 데이터를 들고 왔다. 지지 측은 Reddit r/ClaudeCode에서 보고된 84% 컨텍스트 토큰 감소를, 반대 측은 규모 임계치(약 40만 단어) 이후 결국 하이브리드가 필요하다는 점을 근거로 들었다.
이 글의 목표
이 글은 Karpathy LLM 위키 패턴(약어 LLM-KB, file-over-app)이 무엇인지, 무슨 문제를 풀려고 했는지, 어디까지 검증됐고 어디서 깨지는지를 2026년 4월 현재 시점으로 정리한다. 제품 소개 글이 아니라 개념편이다. 실제 구현 도구(Graphify, llm-wiki-mcp 등)는 생태계 타임라인 섹션에서만 언급한다.
RAG는 왜 개인 지식 관리에 맞지 않을까?
RAG 자체가 틀렸다는 주장이 아니다. 엔터프라이즈 FAQ 챗봇이나 사내 문서 검색처럼 업데이트 빈도가 낮고 쿼리 풀이 한정된 시나리오에서 RAG는 여전히 잘 동작한다. 문제는 Karpathy가 상정한 ‘개인 연구 아카이브’처럼 소스가 이질적이고 지식이 누적돼야 하는 환경이다.
stateless — 매번 처음부터 다시 해석한다
RAG는 쿼리가 들어올 때마다 유사도 검색을 돌려 청크를 뽑고 LLM에 밀어넣는다. 같은 질문을 어제도, 오늘도 물으면 LLM은 매번 처음 본 것처럼 원본을 해석한다. 어제의 통찰이 오늘의 답변에 자동으로 녹지 않는다. 이걸 remio.ai는 “복리 효과의 부재”로 표현했다 (출처: remio.ai). 소스를 아무리 추가해도 지식망이 촘촘해지지 않는다는 뜻이다.
블랙박스 — 벡터 DB는 읽을 수 없다
벡터 embedding은 1,536차원 float 배열이다. 사람이 열어서 “이 문서는 이렇게 이해됐구나”를 확인할 수 없다. 색인이 틀렸는지, 청크 경계가 잘못 잘렸는지, retrieval miss가 얼마나 자주 일어나는지 추적이 어렵다. techbuddies.io는 이걸 “감사 불가능성”으로 지적했다 (출처: techbuddies.io). 특히 retrieval이 실패하면 시스템은 그냥 “못 찾겠다”고 하지 않고 그럴싸한 답을 만든다. Silent failure.
종합 깊이의 한계 — 청크는 청크일 뿐
개인 지식 관리의 본질은 “여러 소스가 같은 개념에 대해 뭐라고 하는지 교차참조하는 것”이다. RAG는 top-k 청크를 가져와 단발성으로 합친다. 다섯 논문이 같은 저자의 서로 다른 주장을 담고 있다면, RAG는 그중 일부 청크만 가져와 LLM에게 “알아서 합쳐봐”라고 한다. 이건 종합이 아니라 샘플링에 가깝다. 그리고 Gemma 4의 함수 호출 6%→86% 급등 같은 최신 모델 성능 개선과도 무관하다. 좋은 모델을 써도 입력이 부족하면 종합은 얕다.
Karpathy 본인도 gist 댓글에서 확인했다. “대규모 기업 검색·법률 문서 Q&A 같은 시나리오에는 RAG가 여전히 맞다. 내가 말하는 건 개인 규모의 스태틱한 아카이브다” (출처: Karpathy gist 댓글). 이 글의 비교는 ‘개인/소규모 지식 관리’ 맥락에 한정된다는 점을 먼저 짚어둔다.
긴 컨텍스트만으로는 왜 안 될까?
“모델 컨텍스트가 100만 토큰이면 그냥 다 넣으면 되는 거 아닌가?” 이 질문이 가장 흔하다. Gemini 3.1 Pro의 1M 토큰, Claude Opus 4.7의 1M 컨텍스트 등 프론티어 모델이 본격적으로 초장문 지원을 내놓으면서 더 자주 나오는 반론이다. 그런데 실제로 써보면 세 가지 벽에 동시에 부딪힌다.
토큰 비용은 선형이 아니다
컨텍스트를 2배로 늘리면 비용도 2배다. 그런데 LLM 위키 패턴은 약 95% 수준의 토큰 절감을 보고한다 (출처: levelup.gitconnected 분석). 이유는 단순하다. 쿼리 시 원본 40만 단어를 다 로딩하는 대신, 미리 컴파일된 요약 페이지와 관련 wikilink 5–10개만 따라간다.
Lost in the middle 문제
컨텍스트를 꽉 채우면 모델이 중간 부분을 놓친다는 연구는 여러 번 재현됐다. 100만 토큰을 실제로 활용하려면 retrieval 전략이 필요한데, 그럼 결국 검색 레이어가 다시 끼어든다. 긴 컨텍스트는 한 방 해결책이 아니다.
영구 보관 vs 임시 세션
컨텍스트 윈도우에 올려놓은 정보는 세션이 끝나면 사라진다. 내일 같은 작업을 하려면 다시 올려야 한다. 복리 효과가 생기지 않는다. 반면 위키는 디스크에 남는다. 다음 쿼리는 이미 종합된 상태에서 시작한다.
| 접근 | 단위당 토큰 | 영속성 | 관리 비용 |
|---|---|---|---|
| RAG retrieval | 중간 (top-k 청크) | 벡터 DB 재인덱싱 필요 | 파이프라인 유지 |
| 긴 컨텍스트 전량 투입 | 매우 높음 (매 쿼리 풀로딩) | 세션 종료 시 소멸 | 낮음 (다만 비용 폭발) |
| LLM 위키 컴파일 | 낮음 (요약+wikilink) | 영구 마크다운 | 린트/수집 시 집중 투자 |
LLM 위키의 3계층 아키텍처는 어떻게 작동하나?
Karpathy gist의 실질적 기여는 ‘3계층 분리 원칙’이다. 각 계층은 소유자가 다르고 수정 권한도 다르다.
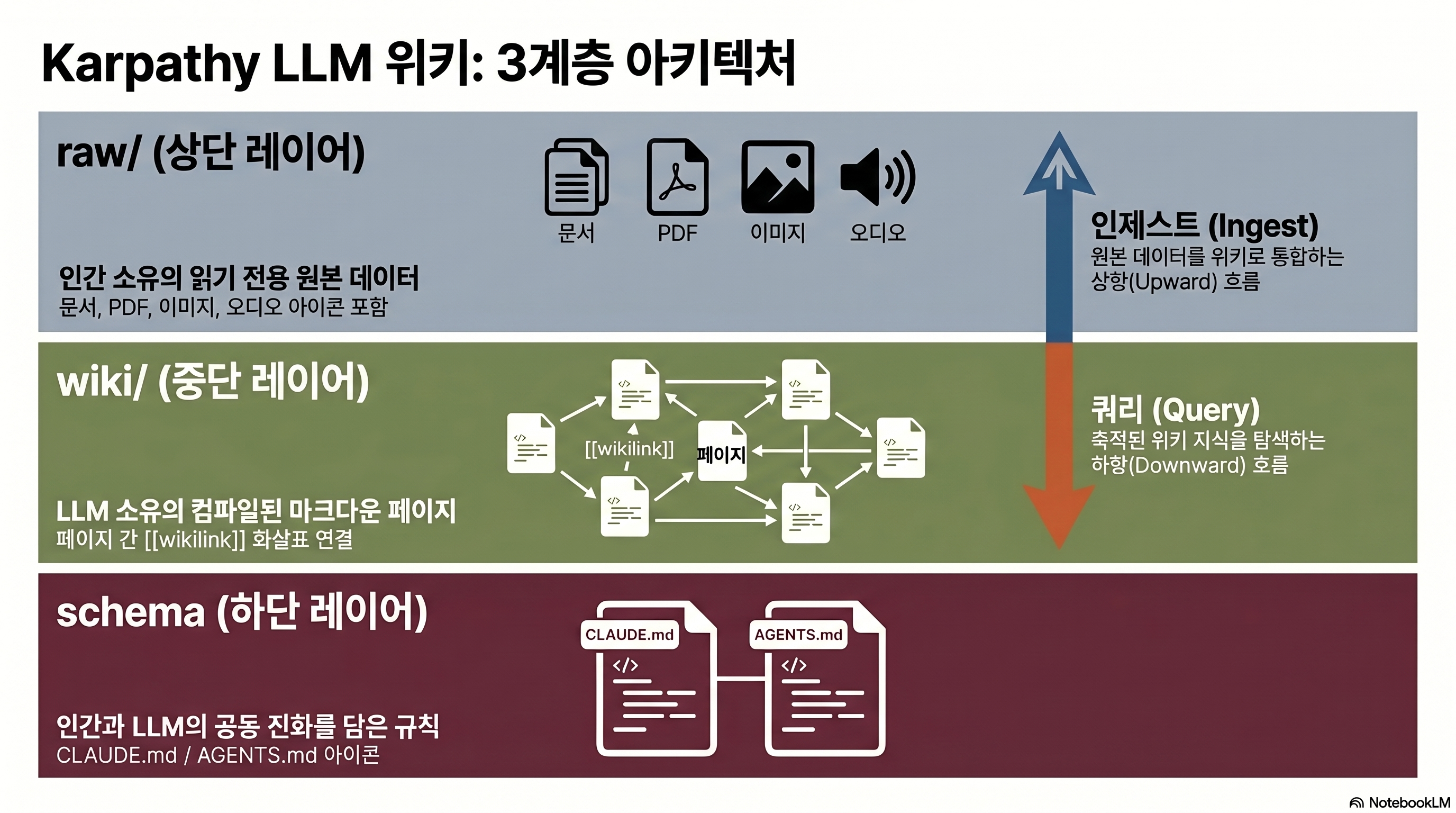
Raw 계층 — 건드리면 안 되는 원천
raw/ 디렉터리에는 PDF, 마크다운, transcript, 이미지가 원본 그대로 들어간다. Obsidian Web Clipper로 웹 아티클을 통째로 저장하면 이미지까지 로컬로 내려온다. 이 계층은 읽기 전용이다. 오염됐다고 판단되면 wiki 계층을 지우고 raw에서 재빌드한다. 깃 히스토리의 원본 커밋 같은 역할이다.
Wiki 계층 — LLM이 쓰는 종합 지식
wiki/ 디렉터리에는 컴파일된 페이지가 마크다운 + YAML frontmatter + [[wikilinks]] 형태로 쌓인다. 새 소스가 들어오면 LLM은 한 번의 수집 작업에서 10–15개 페이지를 동시에 수정한다. 요약 페이지를 쓰고, entity/concept 페이지를 만들거나 갱신하고, 교차참조 링크를 박고, 모순이 발견되면 플래그를 달고, index.md를 업데이트한다. 이게 “컴파일”의 실체다.
Schema 계층 — 인간과 LLM이 함께 키우는 규칙
CLAUDE.md 또는 AGENTS.md에는 워크플로우 계약이 담긴다. ingest / query / lint 순서, 네이밍 규칙, 디렉터리 구조, “모순 발견 시 어떻게 플래그할지” 같은 컨벤션. 이 파일은 개발 도구 생태계에서 이미 실물화됐다. Claude Code의 CLAUDE.md 시스템이 대표적이다. 코드베이스 규약을 LLM에게 알려주는 앵커 파일 패턴이 그대로 지식 작업에 이식된 셈이다.
index.md — 벡터 DB 없이 검색하는 장치
특수 파일 index.md에는 카테고리별 페이지 목록과 한 줄 요약이 모여 있다. LLM은 쿼리가 들어오면 index.md를 먼저 읽고, 관련 페이지로 drill-down한다. 벡터 DB가 없는데 어떻게 검색이 되냐는 질문의 답이 바로 여기다. 다만 실질 한계는 100–200 페이지 수준으로 알려져 있다 (출처: rohitg00 확장 gist). 그 이상이면 index.md 자체가 비대해져 다시 쪼개야 한다.
| 계층 | 소유자 | 파일 형식 | 변경 규칙 |
|---|---|---|---|
| Raw | 인간 | PDF / MD / 이미지 / transcript | 읽기 전용, 원본 보존 |
| Wiki | LLM | Markdown + frontmatter + [[wikilinks]] | ingest 시 LLM이 10~15개 동시 수정 |
| Schema | 인간 + LLM (공진화) | CLAUDE.md / AGENTS.md | 계약 변경 시 수동 커밋 |
RAG와 LLM 위키는 정확히 뭐가 다를까?
아키텍처를 봤으니 정면 비교로 넘어간다. 여기서는 토큰 비용 / 정확도 / 유지보수 세 축으로 본다.

토큰 비용 — 왜 95% 절감이 가능한가
RAG 대비 약 95% 토큰 절감이 보고된다 (출처: levelup.gitconnected 분석). 이유는 구조적이다. RAG는 질문마다 top-k 청크(보통 5–10개)를 매번 인코딩해 넣는다. LLM 위키는 이미 합성된 요약 페이지 1–3개와 관련 wikilink만 따라가기 때문에 입력 크기 자체가 한 자릿수로 줄어든다. 파생 구현체 중에는 raw 파일 전량 로딩 대비 쿼리당 71.5배 적은 토큰을 보고한 벤치마크도 있다 (출처: Analytics Vidhya 분석).
정확도 — retrieval miss 사라지다
RAG는 top-k에서 답이 안 뽑히면 조용히 실패한다. LLM 위키는 index.md가 관련 페이지를 놓치면 적어도 “해당 페이지가 없다”는 사실을 LLM이 확인할 수 있다. 컨텍스트 한도 내에서는 100% 재현이다. 단, 한도를 넘기면 다시 검색 레이어가 필요하다는 점은 한계 섹션에서 다룬다.
유지보수 — self-healing 린트
LLM 위키는 주기적으로 ‘lint 모드’를 돌린다. 중복 entity 페이지 병합, 깨진 wikilink 복구, 오래된 요약 갱신, 모순 플래그 정리. 이 과정이 지식망을 스스로 치유한다. RAG는 같은 동작을 하려면 재인덱싱 파이프라인을 다시 돌려야 하고, 그래도 embedding 레벨의 오류는 보이지 않는다.
| 차원 | RAG | LLM 위키 |
|---|---|---|
| 상태성 | Stateless (쿼리마다 재발견) | Stateful (누적 컴파일) |
| 저장 형식 | 불투명 vector embedding | 사람이 읽는 markdown |
| 검색 파이프라인 | 유사도 검색 (벡터 DB) | index.md 스캔 → drill-down |
| 인프라 복잡도 | 벡터 DB + 임베딩 모델 + 청커 | 파일시스템 + LLM 에이전트 |
| 토큰 비용 | 쿼리마다 retrieval | raw 로딩 대비 약 95% 절감 |
| 신뢰성 | retrieval miss 시 silent failure | 컨텍스트 한도 내 100% |
| 유지보수 | 재인덱싱 파이프라인 | LLM 능동적 self-healing 린트 |
| 감사 가능성 | 어려움 (벡터 블랙박스) | 투명 (파일 diff 가능) |
| 종합 깊이 | 얕음 (one-shot top-k) | 깊음 (incremental compile) |
이 표는 ‘기술 성능 비교’가 아니라 ‘데이터 모델 비교’다. RAG는 검색 문제로 지식 관리를 푼다. LLM 위키는 컴파일 문제로 푼다. 이 프레임 차이가 표의 9개 행을 전부 결정한다.
LLM 위키 생태계는 지금 얼마나 폭발했나?
이론은 gist에 있었다. 구현이 문제였다. 그런데 2주 만에 최소 5개의 파생 구현체가 쏟아졌다. “이 패턴으로 뭘 할 수 있는지”를 보여주는 증거다.
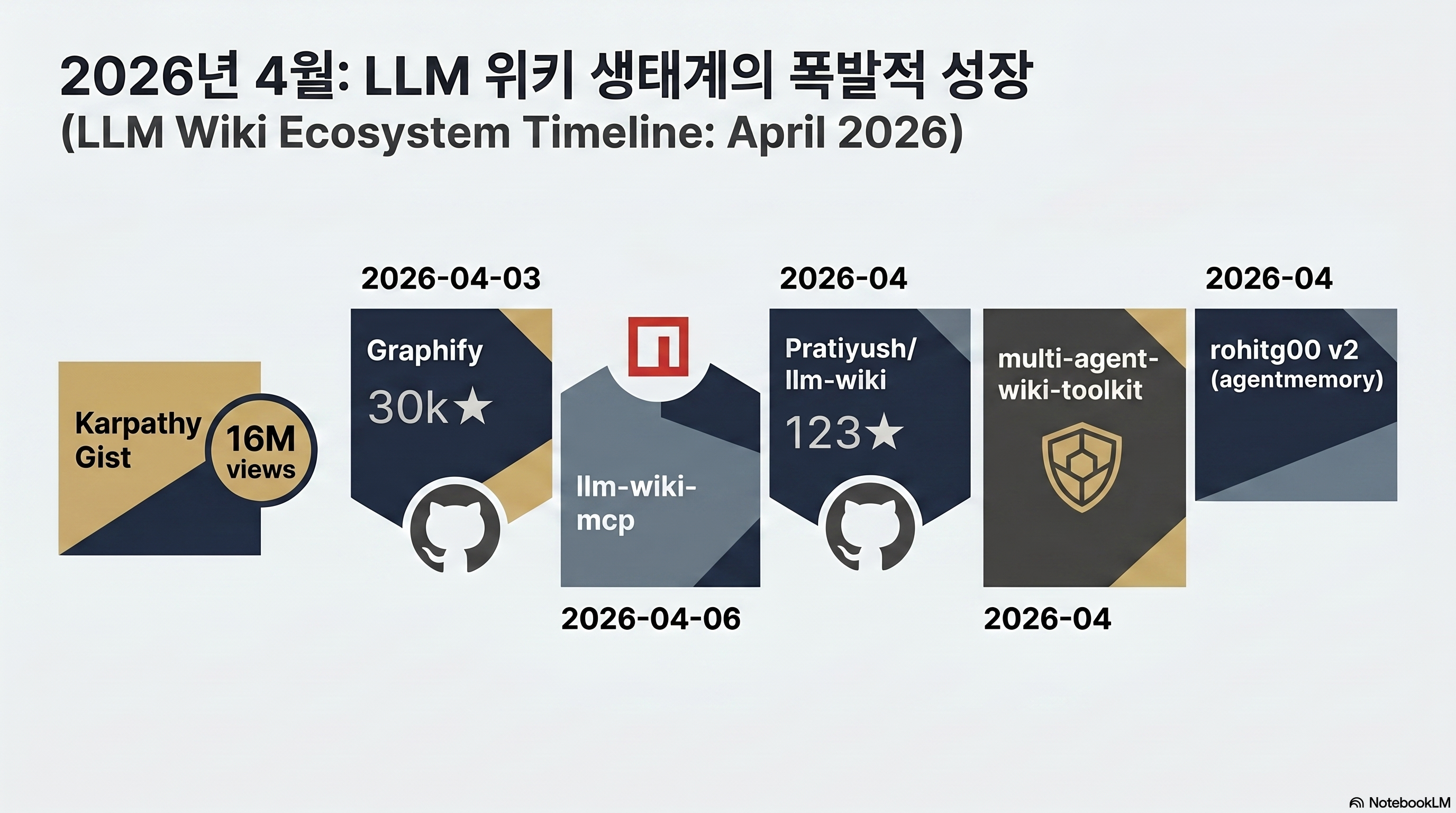
관전 포인트 — 서사 속도
gist 공개 직후 48시간 안에 첫 본격 구현체가 깃허브에 올라왔다 (출처: 바이럴 포스트). 며칠 사이 MCP 서버화, Claude Code 세션 자동 컴파일, 다중 에이전트 확장, agentmemory 결합까지 서로 다른 방향으로 뻗었다. 생태계는 “누가 가장 빨리 잡냐”의 속도 게임이 됐다.
파생 구현체 맵 — 어떤 각도로 갈라졌나
각 구현체는 같은 패턴에서 서로 다른 부분을 강조한다. 1편에서는 카테고리별 포지션만 본다. 실전 설치·사용법은 이 시리즈 2편에서 각각 깊이 다룬다.
| 구현체 | 축 (접근 각도) | 특징 한 줄 |
|---|---|---|
| safishamsi/graphify | 멀티모달 + 그래프 토폴로지 | Leiden 커뮤니티 탐지로 코드·PDF·이미지·비디오를 클러스터화, CLI 스킬로 탑재 |
| llm-wiki-mcp (npm) | 프로토콜화 | MCP 서버로 Claude Desktop 네이티브 연동 |
| Pratiyush/llm-wiki | 세션 로그 자동 컴파일 | Claude Code 대화가 곧 위키 페이지로 적재 |
| redmizt/multi-agent-wiki-toolkit | 다중 에이전트 안전성 | contamination firewall로 에이전트 간 오염 차단 |
| rohitg00/llm-wiki-v2 | 장기 메모리 결합 | agentmemory 레이어로 과거 맥락 지속 |
생태계의 대표 주자 — Graphify 짧게 보기
5개 중 커뮤니티가 가장 먼저 몰린 곳은 safishamsi/graphify다. 눈길을 끈 이유는 세 가지다. 첫째, 입력 범위가 넓다 — 코드만 아니라 PDF·이미지·비디오까지 받아 지식 그래프로 자동 변환한다. 둘째, 다른 파생 구현체가 마크다운 파일 집합에 머무는 반면 Graphify는 Leiden 커뮤니티 탐지로 그래프 토폴로지를 만든다 — 단순 wikilink가 아닌 클러스터 단위로 의미를 압축한다. 셋째, Claude Code·Cursor·Gemini CLI에 “스킬” 형태로 바로 꽂힌다. 기존 워크플로우를 갈아엎지 않고 얹는 방식이다. 이 세 특성이 겹쳐서 2주 만에 깃허브 스타 3만을 넘겼다.
다만 이 글은 개념편이다. Graphify의 실제 설치, 폴더 설계, 첫 ingest 검증, 한국어 소스 파이프라인, 그리고 이게 정말 RAG 대안이 되는지 측정하는 방법은 이 시리즈 2편이 전담한다. 여기서는 “이 생태계에 Graphify라는 축이 있다”는 좌표만 기억하면 된다.
왜 이렇게 빨랐을까
Karpathy gist 자체가 구현 힌트를 이미 다 담고 있었다. 3계층 디렉터리 구조, index.md 드릴다운, lint 루틴, wikilink 문법 — 따라 만들기만 하면 되는 설계도였다. 독자적인 리서치 없이 엔지니어가 주말에 깎아 올릴 수 있는 복잡도라, 진입 장벽이 낮아 속도전이 됐다.
실제로 쓰는 사람들은 뭐라고 하나?
- "6개월 묵은 리서치 노트를 컴파일했더니 내가 여러 번 같은 결론에 도달했다가 잊어버린 패턴이 드러났다. 검색으로는 절대 못 찾을 연결이었다." — Reddit r/learnmachinelearning
- "Claude Code 플러그인으로 자동화했더니 컨텍스트 토큰이 84% 줄었다. 비용이 체감될 정도다." — Reddit r/ClaudeCode (103 upvotes)
- "수동 노트 작성이 사실상 사라졌다. 대화가 곧 위키 페이지가 된다. 진짜 패러다임 전환이다." — Reddit r/ClaudeCode 플러그인 쇼케이스
- "Semantic Web이 30년째 풀지 못한 모순 구조 문제를 여전히 못 푼다. 이름만 바꾼 재탕이다." — Hacker News 코멘트
- "작을 때만 동작한다는 모순이 있다. 결국 규모 커지면 RAG에 벡터 검색 얹어야 하고, 그럼 RAG with extra steps 아닌가?" — Reddit r/MachineLearning
- "LLM이 당신 위키를 써주는 건 당신의 성장에 무가치하다. 정리 과정 자체가 학습이다." — Reddit 댓글 (75 upvotes)
긍정 반응의 공통 키워드 — ‘복리’
긍정 후기의 공통점은 “시간이 지날수록 더 강해진다”는 체감이다. 첫 주에는 효과가 미미한데 3–6개월 뒤부터 답변 품질이 달라진다는 증언이 많다.
부정 반응의 공통 키워드 — ‘자기 기만’
반면 비판은 “이게 정말 새로운 것이냐”로 수렴한다. Semantic Web 재탕, RAG with extra steps, 학습 외주화. 세 갈래 다 뿌리가 같다. 포장이 과하다는 의심이다.
LLM 위키의 한계 3가지 — 무엇을 조심해야 하나?
이 섹션은 중립이 아니라 ‘방어’에 가깝다. 패턴을 도입하기 전에 알아야 할 함정들이다.
규모 임계치 — 40만 단어에서 무너진다
Karpathy 본인의 사용 규모는 문서 100개, 약 400,000단어 수준이다 (출처: techbuddies.io). 이 언저리에서 index.md 기반 검색이 한계를 맞이한다는 보고가 반복된다. 그 이상 규모면 결국 하이브리드(마크다운 + 벡터 검색)가 필요하고, 이 지점이 “RAG with extra steps” 비판의 근거가 된다.
환각 오염 영구화 — 한 번 잘못 쓴 사실은 박힌다
LLM이 컴파일 과정에서 틀린 사실을 한 번 wiki 페이지에 기록하면, 이후 모든 쿼리가 그 오류를 참조한다. RAG는 그래도 매번 원본에서 다시 해석하기 때문에 오염이 일회성이다. 위키는 영구화된다. 주기적인 lint + 원본 대조 + Silent Drift 탐지(freshness 메타데이터)가 필수다.
Lint 누락 — 가장 먼저 건너뛰는 단계
DIY 구현에서 가장 흔히 스킵되는 게 린트다. 수집은 재미있는데 정리는 지루하다. 그런데 린트 없는 위키는 3개월만 지나면 내부 모순과 중복으로 무너진다. rohitg00 확장이 린트 자동화를 핵심 feature로 내세운 이유다.
| 한계 | 증상 | 완화 전략 |
|---|---|---|
| 규모 임계치 (~40만 단어) | index.md 비대화, drill-down 실패율 증가 | 카테고리별 서브 index, 하이브리드 벡터 검색 병행 |
| 환각 오염 영구화 | 잘못된 entity 페이지가 반복 참조됨 | 주기적 lint + raw 원본 diff + freshness 메타데이터 |
| Silent Drift | 오래된 정보를 자신 있게 반환 | 페이지별 last_verified 필드 + 만료 알림 |
| Lint 스킵 | 중복·모순 누적으로 위키 열화 | ingest 워크플로우에 lint 강제 포함 |
| 평가 메트릭 부재 | 건강도 측정 불가 | 커뮤니티 표준 대기, 현재는 커버리지/링크 밀도로 대체 |
규모 임계치는 나중에 닥칠 문제지만 환각 오염은 첫 주부터 쌓인다. ingest 직후 같은 날 안에 raw 원본과 대조하는 1차 감사를 습관화해야 한다. 늦게 발견하면 수정 비용이 기하급수적으로 증가한다.
지금 이 글을 읽는 당신은 뭐부터 해야 하나?
이 글의 핵심 한 줄
LLM 위키는 ‘검색 최적화’가 아니라 ‘지식 컴파일’ 패러다임이다. 개인·소규모 아카이브에서 RAG보다 토큰 효율과 감사 가능성이 앞서지만, 40만 단어 임계치·환각 오염·린트 누락 세 가지를 피하지 못하면 3개월 안에 자멸한다. 시작은 raw/wiki/schema 3폴더를 만드는 30분으로 충분하다.
- 개인 연구 노트·논문·북마크가 몇 백 개 단위로 쌓여 있고, 검색이 점점 안 되는 사람
- Claude Code / Cursor / Obsidian 환경이 이미 익숙한 개발자·리서처
- RAG 기반 개인 지식 봇을 만들어봤는데 “왜 이렇게 답이 얕지?”를 느껴본 사람
- 반대로 초심자·글쓰기 학습자·지식을 “정리 과정에서 체화”하려는 사람에게는 권하지 않는다. 학습 외주화 비판이 이 그룹에 정확히 적중한다.
오늘 당장 할 수 있는 3단계
Obsidian vault + 3폴더 준비
raw/, wiki/, index.md 세 개 폴더·파일만 먼저 만든다. 플러그인도 Web Clipper 하나면 충분하다. 30분이면 끝난다.
파생 구현체 하나 골라 ingest 테스트
생태계 5개 구현체 중 자신의 에디터·워크플로우에 맞는 것을 하나 선택해 기존 노트 10~20개를 ingest해본다. 첫 컴파일 결과를 반드시 raw 원본과 비교해 환각 유무를 확인한다. 구현체별 설치·실전 가이드는 이 시리즈 2편에서 다룬다.
CLAUDE.md 초안 작성 + 주 1회 lint 스케줄 고정
ingest/query/lint 순서와 네이밍 규칙을 100자 내외로 적는다. 매주 같은 요일에 lint 세션을 돌려 중복·모순을 정리한다. 이 루틴이 없으면 3개월 뒤 위키가 무너진다.
1편에서 2편으로 — 지금까지 잡은 것, 다음에 잡을 것
여기까지가 “LLM 위키가 왜 나왔고, 무슨 구조이고, 왜 지금 터졌나”의 이론편이다. 이 지점에서 독자가 느낄 질문은 대체로 같다. “개념은 알겠어. 그럼 내 폴더에 어떻게 붙이지?” 그 질문부터가 2편의 시작점이다.
이 글은 Karpathy LLM 위키 시리즈의 1편 — 개념편이다. 2·3편은 지금까지 언급만 하고 지나간 것들을 실물로 잡는다.
- 2편 — Graphify 실전 구축기 (지금 읽기): 이 글에서 좌표만 찍어둔 Graphify로 실제 위키를 구축한다. 폴더 설계(
raw/·wiki/·index.md),/graphify명령 흐름, 첫 ingest 결과를 원본과 대조해 환각 검증하는 법, 한국어 소스(HWP·PDF·뉴스 스크랩) 파이프라인, Claude Code의 CLAUDE.md와 연동하는 지점까지 스크린샷 단위로 따라간다. - 3편 — 6개월 운영 후기 (발행 예정): 이 글의 “한계 3가지” 섹션을 실사용 데이터로 검증한다. 40만 단어 임계치에서 실제로 뭐가 깨지는지, 환각 오염이 어떻게 발견·복구되는지, 린트를 빼먹었을 때 위키가 얼마 만에 무너지는지.
지금 당장은 raw/·wiki/·index.md 세 폴더만 만들어두면 2편에서 바로 이어갈 수 있다.
- Karpathy 원문 gist (1,600만 조회, 댓글 토론이 본문만큼 가치 있음)
- VentureBeat 커버리지 (업계 맥락 정리)
- levelup.gitconnected의 95% 토큰 절감 분석 (실측 수치)
- rohitg00 확장 gist (index.md 100–200 페이지 한계 실측)
자주 묻는 질문
지금 프로덕션에 쓸 만큼 성숙한가?
Obsidian 없이도 할 수 있나?
RAG를 완전히 버려야 하나?
한국어 소스(논문·블로그)도 잘 처리하나?
개인 정보 누출 위험은 없나?
비용은 얼마나 드나?
초보자는 어디서 시작해야 하나?

벡터리스 RAG란? PageIndex가 진짜 RAG 대안일까
PageIndex가 왜 벡터 DB와 청킹 없이 긴 문서를 찾는다고 말하는지, 가격·MCP·FinanceBench·한계를 2026년 5월 기준으로 정리한다.
읽기
Kronos란? 금융 시계열 AI 모델, Chronos·TimesFM과 비교
Kronos가 왜 금융 시계열 특화 AI 모델로 주목받는지, 논문 수치와 공식 문서 기준으로 Chronos·TimesFM·TimeGPT와 비교해 정리한다.
읽기
맥북 로컬 AI 서버 끝판왕? Rapid-MLX 설치·성능·Ollama 비교
Rapid-MLX가 무엇인지, 맥북에서 어떻게 설치해 쓰는지, Ollama·LM Studio와 비교하면 무엇이 다른지 최신 기준으로 정리한다.
읽기