맥북 로컬 AI 서버 끝판왕? Rapid-MLX 설치·성능·Ollama 비교
Rapid-MLX가 무엇인지, 맥북에서 어떻게 설치해 쓰는지, Ollama·LM Studio와 비교하면 무엇이 다른지 최신 기준으로 정리한다.

빠른 결론
먼저 이렇게 보면 됩니다
약 32분 읽기한 줄 판단
Rapid-MLX가 무엇인지, 맥북에서 어떻게 설치해 쓰는지, Ollama·LM Studio와 비교하면 무엇이 다른지 최신 기준으로 정리한다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- Rapid-MLX · MLX · Apple Silicon
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- Rapid-MLX는 새 AI 모델이 아니라 Apple Silicon용 로컬 AI 서버이자 에이전트 런타임이다.
- 진짜 강점은
표준 API 호환 + 도구 호출 복구 + 프롬프트 캐시 + Claude Code/Cursor 연결성조합이다. - 다만
4.2배 빠름같은 헤드라인은 최고 사양 맥 기준 자체 벤치마크이고, 하이브리드 모델 캐시 이슈와 선택형 클라우드 라우팅은 반드시 같이 봐야 한다.
목차
- Rapid-MLX는 정확히 무엇인가?
- 왜 요즘 Rapid-MLX가 갑자기 주목받나?
- 설치는 정말 간단한가?
- 4.2배 빠르다는 말은 어디까지 사실인가?
- Ollama·LM Studio·mlx-lm serve와 무엇이 다른가?
- Claude Code·Cursor·Aider에도 바로 붙나?
- 어떤 맥에서 어떤 모델까지 현실적인가?
- 지금 조심해서 봐야 할 한계는 무엇인가?
- 누구에게 추천하고 누구에겐 아직 이른가?
- FAQ: Rapid-MLX에 대해 자주 묻는 질문
- 결론: 지금 Rapid-MLX를 갈아탈 이유가 있나?
결론부터 말하면 Rapid-MLX는 “맥북에서 로컬 LLM 한 번 띄워보는 도구”보다 “Apple Silicon에서 코딩 에이전트를 돌리기 위한 로컬 서버”로 읽는 편이 맞다. 이미 Ollama가 잘 돌아가는 환경이라면 무조건 갈아탈 이유는 없다. 대신 Cursor, Claude Code, Aider 같은 툴에 붙일 때 도구 호출 안정성과 캐시, 표준 API 호환성을 더 세밀하게 챙기고 싶다면 Rapid-MLX는 분명 볼 가치가 있다. 다만 속도 헤드라인만 믿고 들어가면 과장에 걸리기 쉽다.
Rapid-MLX는 정확히 무엇인가?
짧게 말하면 Rapid-MLX는 Apple Silicon용 로컬 AI 추론 엔진이자 API 서버다. 중요한 포인트는 “모델”이 아니라는 점이다. 실제 모델은 Qwen, Gemma, Nemotron 같은 외부 오픈 웨이트를 가져오고, Rapid-MLX는 그것을 맥의 MLX 생태계 위에서 빠르게 서빙하는 레이어에 가깝다 (출처: Rapid-MLX README, pyproject.toml).
모델이 아니라 런타임 레이어다
pyproject.toml을 보면 Rapid-MLX는 mlx, mlx-lm, fastapi, uvicorn, mcp 같은 의존성을 중심으로 묶여 있다. 즉 새 모델 가중치를 파는 프로젝트가 아니라, 기존 MLX 생태계를 에이전트 친화적으로 감싼 서버라고 이해하면 된다 (출처: pyproject.toml).
이 설명은 중요하다. 독자 입장에선 종종 “Rapid-MLX가 Ollama보다 똑똑한가?”라는 식으로 읽기 쉬운데, 정확한 질문은 “같은 계열 모델을 Apple Silicon에서 어떤 방식으로 더 잘 서빙하느냐”다.
Rapid-MLX가 얹는 핵심 기능은 무엇인가?
저장소가 전면에 내세우는 건 네 가지다. 첫째, 표준 API 호환성이다. 둘째, 17개 도구 파서와 깨진 도구 호출 복구다. 셋째, 프롬프트 캐시와 reasoning separation이다. 넷째, Claude Code·Cursor·Aider 같은 개발자 도구와의 연결성이다 (출처: Rapid-MLX README).
특히 도구 호출 쪽 포지셔닝이 선명하다. README는 Qwen 계열을 중심으로 100% tool calling과 자동 복구를 강하게 밀고 있고, MHI(Model-Harness Index)라는 자체 지표까지 제시한다. 이 덕분에 Rapid-MLX는 일반 챗 UI보다 에이전트 워크플로우 쪽에서 더 존재감이 크다.
왜 Apple Silicon 전용이라는 점이 핵심인가?
Rapid-MLX가 MLX를 기반으로 삼는 이유는 Apple Silicon의 unified memory 구조 때문이다. MLX 공식 저장소는 CPU와 GPU가 공유 메모리를 쓰고, 배열을 옮기지 않고도 여러 장치에서 연산할 수 있다는 점을 핵심 특징으로 설명한다 (출처: MLX GitHub).
그래서 Rapid-MLX를 단순히 “또 하나의 로컬 LLM 툴”로 보면 절반만 이해한 셈이다. 이 프로젝트는 AI 앱은 프롬프트가 아니라 하네스로 완성된다에서 다뤘던 것처럼, 모델 그 자체보다 실행 환경과 연결면을 다듬는 쪽에 가깝다.

왜 요즘 Rapid-MLX가 갑자기 주목받나?
이 프로젝트가 눈에 띄는 이유는 단순히 “빠르다”가 아니다. 로컬 AI 시장에서 가장 보수적인 선택지였던 Ollama 바깥으로, Apple Silicon 최적화와 코딩 에이전트 친화성이라는 명확한 포지션을 잡았기 때문이다.
저장소 성장 속도가 꽤 빠르다
GitHub API 기준 Rapid-MLX 저장소는 2026년 2월 25일 생성됐고, 2026년 5월 6일 기준 별 1,573개, 포크 223개를 기록하고 있다. 최신 릴리스와 PyPI 패키지는 0.6.14이며 2026년 5월 5일에 올라왔다 (출처: GitHub repo, PyPI).
이 숫자만 보면 작은 실험 레포를 넘긴 상태다. 다만 동시에 아주 빠르게 변하는 프로젝트라는 뜻이기도 하다. 실제로 5월 초 며칠 사이에 0.6.10부터 0.6.14까지 촘촘하게 핫픽스가 이어졌다 (출처: GitHub releases).
로컬 코딩 에이전트 수요와 맞물렸다
README를 보면 이 프로젝트는 처음부터 Cursor, Claude Code, Aider, LangChain, PydanticAI 같은 연결처를 강조한다. 즉 “맥에서 로컬 모델 한 번 대화해보기”보다 “기존 에이전트 툴의 백엔드를 로컬로 바꾸기”가 핵심 시나리오다 (출처: Rapid-MLX README).
이 점은 클로드 코드 완전 정복: 설치, 가격, 활용법 총정리 (2026)에서 다룬 고민과 바로 이어진다. 비용, 프라이버시, 긴 작업 세션을 생각하는 사용자는 결국 “어떤 모델을 쓰나”보다 “내 에이전트가 어디에 붙어 일하나”를 보게 된다.
한국 독자에게는 “맥북 로컬 AI 서버”라는 문제로 읽는 편이 낫다
Rapid-MLX 자체는 아직 한국어 대중 인지도가 높은 이름은 아니다. 그래서 한국어 글에서 중요한 건 “Rapid-MLX가 유명하냐”보다 “맥북에서 로컬 AI 서버를 고를 때 이게 왜 후보가 되느냐”다. 이 글도 그 관점으로 쓴다.
설치는 정말 간단한가?
설치 자체는 생각보다 단순하다. 다만 “간단한 설치”와 “바로 실무 투입”은 다르다.
기본 설치 경로는 세 가지다
README가 제시하는 기본 경로는 Homebrew, pip, 설치 스크립트 세 가지다 (출처: Rapid-MLX README).
# Homebrew
brew install raullenchai/rapid-mlx/rapid-mlx
# pip
pip install rapid-mlx
# install script
curl -fsSL https://raullenchai.github.io/Rapid-MLX/install.sh | bash첫 실행은 예를 들어 아래처럼 간다.
rapid-mlx serve qwen3.5-9b서버가 뜨면 기본 엔드포인트는 http://localhost:8000/v1이다 (출처: Rapid-MLX README).
테크줍줍 워크플로우에서 직접 확인한 범위
이 글을 준비하면서 Apple M4 Pro, Python 3.11.9 환경에서 임시 가상환경에 pip install rapid-mlx를 직접 돌려봤다. 설치는 정상 완료됐고 rapid-mlx doctor도 PASS가 나왔다. 다만 model_load 검사는 테스트 모델 다운로드가 필요해서 SKIP이었다.
즉 “기본 설치와 CLI 상태 확인까지는 실제로 매끄럽게 된다”는 건 확인했다. 반대로 말하면, 이 글의 범위 안에서 특정 모델을 띄워 Cursor나 Claude Code까지 끝까지 붙여 본 것은 아니다. 그 부분은 설치와 별개로 실사용 검증의 영역이다.
진짜 마찰은 Python 버전과 확장 기능에서 생긴다
PyPI와 README 모두 Python 3.10+를 요구한다. macOS 기본 Python이 더 낮다면 먼저 Python을 올려야 한다. 또 vision, audio, embeddings 같은 기능은 별도 extras 설치가 필요하다 (출처: PyPI, Rapid-MLX README).
여기서부터는 “한 줄 설치”라는 표현을 조금 보수적으로 읽는 편이 맞다. 텍스트 전용 모델은 쉽게 시작할 수 있지만, 멀티모달이나 오디오까지 가면 환경 무게가 갑자기 커진다.
4.2배 빠르다는 말은 어디까지 사실인가?
Rapid-MLX가 가장 크게 내세우는 문구는 “Ollama보다 2~4배 빠르다”, “cached TTFT 0.08초”, “100% tool calling”이다. 이 문구는 완전히 허공의 마케팅은 아니지만, 그대로 일반화하면 곤란하다.
저장소가 실제로 주장하는 수치는 무엇인가?
README의 벤치마크 섹션은 Mac Studio M3 Ultra 256GB에서 여러 모델의 decode speed와 cached TTFT를 제시한다. 예를 들어 Qwen3.5-9B는 108 tok/s, Qwen3.6-35B-A3B는 95 tok/s, Qwen3.5-122B는 44~57 tok/s 정도로 적혀 있다. 그리고 일부 모델에서 Ollama 대비 2배 이상 빠른 수치를 앞세운다 (출처: Rapid-MLX README).
그대로 믿으면 안 되는 이유는 세 가지다
첫째, 벤치마크는 저장소 작성자가 직접 낸 수치다. 둘째, 기준 하드웨어가 최고 사양급 M3 Ultra라서 일반적인 16GB~36GB 맥북 체감과는 다르다. 셋째, 비교 대상인 Ollama도 2026년 3월 말부터 MLX 프리뷰를 내놓으며 Apple Silicon 성능을 크게 끌어올리고 있다 (출처: Rapid-MLX README, Ollama MLX preview blog).
| 헤드라인 주장 | 무슨 뜻인가 | 독자가 붙여야 할 조건 |
|---|---|---|
| Ollama보다 최대 4.2배 빠름 | 특정 모델·특정 하드웨어·특정 시점 자체 벤치마크 | 보편적 상수처럼 읽지 말 것 |
| cached TTFT 0.08초 | 캐시가 잘 먹는 조건에서 첫 토큰 반응이 매우 빠름 | 긴 다중 턴·하이브리드 모델에선 다르게 나올 수 있음 |
| 100% tool calling | 주로 Qwen·GLM 등 테스트된 모델 패밀리 기준 강점 | 모든 모델에서 만능처럼 일반화하면 안 됨 |
경쟁 구도 자체가 움직이고 있다
Rapid-MLX를 다룰 때 자주 빠지는 함정은 Ollama를 정지 화면처럼 보는 것이다. 그런데 2026년 3월 30일자 공식 Ollama 블로그를 보면 Apple Silicon에서 MLX 기반 프리뷰를 밀고 있고, TTFT와 decode 성능을 계속 올리고 있다 (출처: Ollama MLX preview blog).
따라서 “Rapid-MLX가 무조건 제일 빠른가?”보다 “지금 내 워크플로우에서 어떤 종류의 속도와 안정성을 더 주는가?”가 맞는 질문이다.
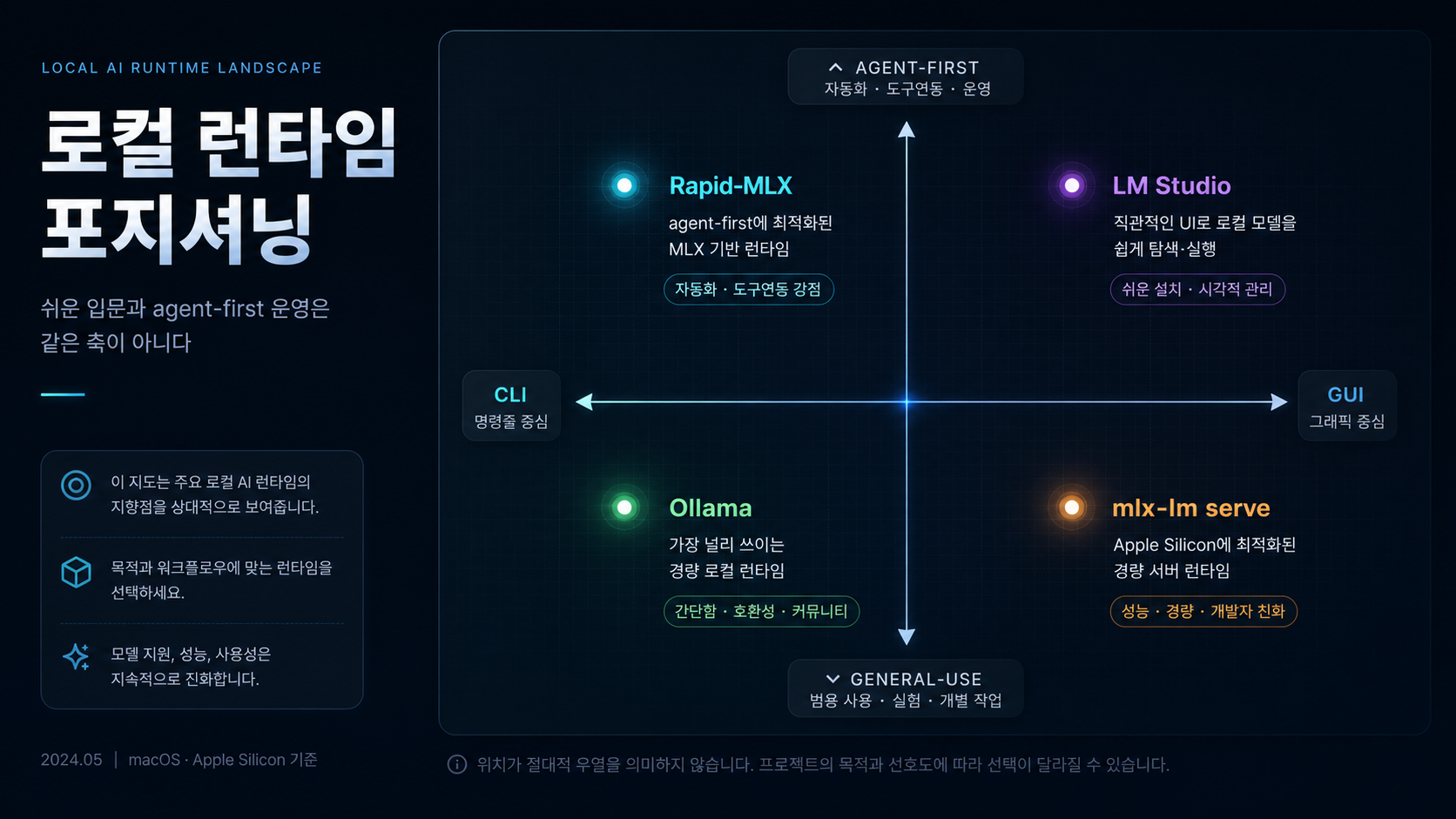
Ollama·LM Studio·mlx-lm serve와 무엇이 다른가?
Rapid-MLX를 이해하는 가장 쉬운 방법은 다른 로컬 런타임과 나란히 놓고 보는 것이다.
Ollama는 표준, Rapid-MLX는 에이전트 최적화에 가깝다
Ollama는 여전히 로컬 AI의 기본값에 가깝다. 설치가 쉽고 모델 풀이 넓고, 최근에는 Apple Silicon에서 MLX 프리뷰도 공개했다. 반면 Rapid-MLX는 표준 API 호환, 도구 파서, 깨진 tool call 복구, reasoning separation, cloud routing 같은 개발자 기능을 전면에 둔다 (출처: Ollama MLX preview blog, Rapid-MLX README).
쉽게 말하면 Ollama는 “로컬 모델을 쉽게 돌리는 표준”에 가깝고, Rapid-MLX는 “에이전트 백엔드로 쓸 때 더 예민한 부분을 다듬은 서버”에 가깝다.
LM Studio는 GUI 친화적이고, Rapid-MLX는 서버 친화적이다
LM Studio 공식 문서는 OpenAI 호환 엔드포인트와 /v1/responses까지 제공한다고 밝힌다. 즉 LM Studio도 Codex나 다른 OpenAI 클라이언트와 붙일 수 있다 (출처: LM Studio OpenAI compatibility docs).
차이는 폼팩터다. LM Studio는 시각적이고 데스크톱 친화적이다. Rapid-MLX는 터미널과 서버 운영, 에이전트 연결에 훨씬 더 기울어져 있다. 그래서 GUI로 모델을 보고 고르고 싶다면 LM Studio가 편하고, 백그라운드 로컬 API 서버로 계속 띄워둘 생각이라면 Rapid-MLX가 더 자연스럽다.
mlx-lm serve는 기반, Rapid-MLX는 그 위의 배터리 묶음이다
MLX 공식 생태계의 mlx-lm은 순수하게 MLX 모델을 띄우는 기반에 가깝다. Rapid-MLX는 그 위에 도구 호출, 시각·오디오 extras, 캐시, doctor, 모델 추천과 같은 실사용용 조각을 얹는다. 그래서 기술적으로는 꽤 많은 기능이 “새 엔진”이라기보다 “더 실무적인 패키징”으로 읽힌다.
| 항목 | Rapid-MLX | Ollama | LM Studio | mlx-lm serve |
|---|---|---|---|---|
| 주 사용 표면 | CLI/API 서버 | CLI/서비스 | GUI + 로컬 서버 | 기본 서버 |
| Apple Silicon 포지션 | MLX 최적화 강조 | MLX 프리뷰 진행 중 | MLX와 GGUF 양쪽 활용 | MLX 기본 경로 |
| 에이전트 연동 초점 | 강함 | 중간 | 중간 | 약함 |
| 도구 호출·복구 | 강하게 전면 배치 | 있지만 포지셔닝이 다름 | 주력 메시지 아님 | 기본 제공 아님 |
| 입문 난이도 | 중간 | 낮음 | 낮음 | 중간 |
Claude Code·Cursor·Aider에도 바로 붙나?
이 질문은 “된다”와 “잘 된다”를 나눠서 답해야 한다.
원리는 단순하다
Rapid-MLX는 표준 API 호환 서버를 제공한다. 그래서 기존 OpenAI 계열 클라이언트나 그 규격을 따라가는 툴이라면 기본적으로는 Base URL만 바꿔 연결할 수 있다. README도 Cursor, Claude Code, Aider, LangChain, PydanticAI 등을 지원 대상으로 적고 있다 (출처: Rapid-MLX README).
예를 들어 Claude Code 쪽은 이렇게 잡을 수 있다.
OPENAI_BASE_URL=http://localhost:8000/v1 claudeAider는 이렇게 붙일 수 있다.
aider --openai-api-base http://localhost:8000/v1 --openai-api-key not-needed위 명령 자체는 README에 나온 실전 예시다 (출처: Rapid-MLX README).
Cursor와 Claude Code 연결은 특히 매력 포인트다
Rapid-MLX를 검토할 가치가 커지는 지점이 여기다. Cursor나 Claude Code를 이미 메인 워크플로우로 쓰는 개발자라면, 로컬 모델을 “별도 챗앱”이 아니라 기존 작업 흐름의 백엔드로 붙일 수 있기 때문이다. 이 감각은 Qwen 3.6 리뷰에서 다뤘던 로컬 코딩 에이전트 이야기와 이어지고, 실제 툴 사용 습관은 Claude Code 완전 정복 글과 함께 보면 더 이해가 빠르다.
호환성과 실전 안정성은 같은 말이 아니다
여기서 한 발 물러서야 한다. Base URL만 바꾸면 붙는다고 해서, 모든 모델·모든 툴·모든 장기 세션에서 같은 품질이 나온다는 뜻은 아니다. 특히 tool calling, reasoning parser, 캐시가 얽히는 순간에는 런타임의 안정성이 모델 품질만큼 중요해진다.
그래서 이 글은 “바로 붙는다”는 연결 가능성은 인정하되, “실서비스급으로 완전히 검증됐다”는 식으로는 말하지 않는다. 실제로 이 워크플로우에서는 설치와 doctor까지만 직접 확인했고, Cursor/Claude Code 풀세션 검증은 별도 테스트 영역으로 남겨뒀다.
어떤 맥에서 어떤 모델까지 현실적인가?
Rapid-MLX를 볼 때 가장 중요한 숫자는 tok/s가 아니라 메모리다. 독자가 맥북 에어나 24GB 맥북프로를 쓰는지, 64GB 이상 스튜디오를 쓰는지에 따라 추천 모델이 완전히 달라진다.
메모리부터 보고 모델 크기를 정해야 한다
README의 “What fits my Mac?” 표를 보면 16GB는 Qwen3.5-4B, 24GB는 Qwen3.5-9B, 32GB는 Qwen3.5-27B 또는 Qwen3.6-35B-A3B, 64GB 이상은 Qwen3.5-35B-A3B, 96GB 이상은 Qwen3.5-122B 같은 식으로 권장선이 나뉜다 (출처: Rapid-MLX README).
| 통합 메모리 | 현실적인 첫 선택 | 왜 이 선이 중요한가 |
|---|---|---|
| 16GB | Qwen3.5-4B 4bit | 가볍고 빠르지만 장기 코딩 에이전트엔 한계가 빨리 온다 |
| 24GB | Qwen3.5-9B 4bit | 입문자용 균형점으로 가장 무난하다 |
| 32GB | Qwen3.5-27B 4bit / Qwen3.6-35B-A3B 4bit | 로컬 코딩 에이전트 감각이 본격적으로 살아난다 |
| 64GB | Qwen3.5-35B-A3B 8bit | 품질과 속도의 실전 균형점에 가깝다 |
| 96GB+ | Qwen3.5-122B mxfp4 | 프런티어급 로컬 실험이 가능해진다 |
로컬 모델 선택은 Rapid-MLX와 별개 문제다
여기서 한 번 더 분리해야 한다. Rapid-MLX는 엔진이고, 어떤 모델을 올릴지는 별도 판단이다. 코딩과 에이전트 워크플로우라면 Qwen 3.6 리뷰를 같이 보는 게 좋고, 오픈 웨이트 로컬 LLM 전반을 보고 싶다면 Gemma 4 리뷰가 좋은 짝이다.
한국어나 한국 업무 맥락이 중요하다면 모델 선택의 논점은 더 달라진다. 그 축은 LG EXAONE 4.5와 한국 로컬 LLM 근황 총정리에서 따로 정리한 것처럼, 런타임보다 모델 라이선스와 한국어 품질이 더 중요해질 때가 많다.
”맥북에서 돌아간다”와 “쓸 만하다”는 다르다
이 차이를 놓치면 글이 금방 허무해진다. 16GB 맥에서도 로컬 모델은 돌아간다. 하지만 Cursor나 Claude Code 뒤에 붙여 장기 수정 세션까지 버티는가, 도구 호출이 튼튼한가, 응답이 답답하지 않은가는 또 다른 문제다. Rapid-MLX가 흥미로운 건 հենց 여기서다. 단순 실행보다 실전 체감 쪽을 노린다.

지금 조심해서 봐야 할 한계는 무엇인가?
Rapid-MLX를 진지하게 볼수록, 강점보다 한계를 더 또렷하게 적어야 한다.
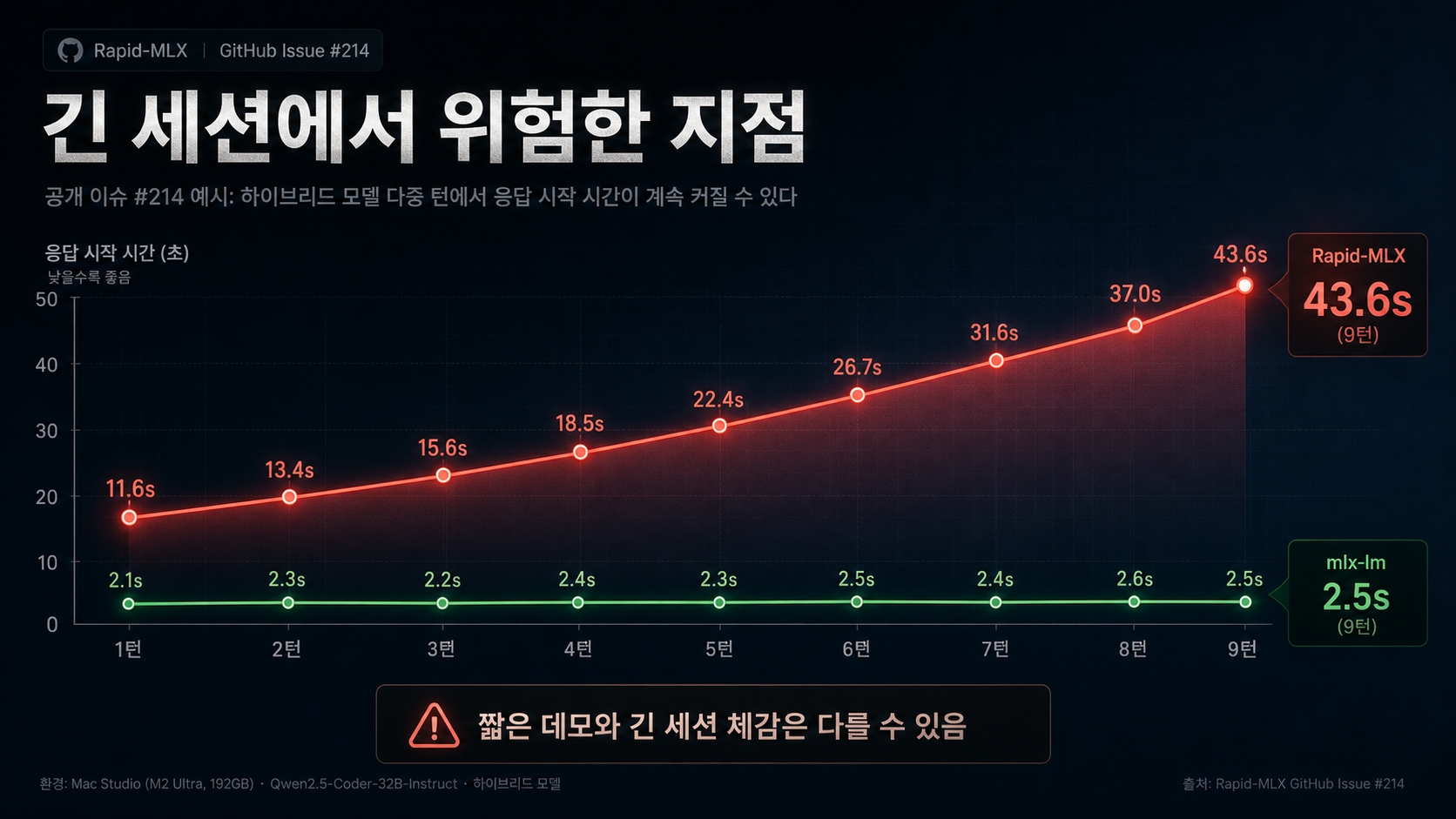
가장 독자 친화적인 경고는 Issue #214다
공개 이슈 #214는 하이브리드 모델 Qwen3.6-35B-A3B에서 다중 턴 대화가 커질수록 prefix cache가 매번 miss 나고, TTFT가 사실상 선형적으로 증가하는 문제를 지적한다. 이슈 본문에는 11.57초 -> 43.58초까지 늘어나는 예시가 공개돼 있다 (출처: Issue #214).
이건 에이전트 워크플로우에선 꽤 치명적이다. 짧은 1~2턴 데모는 멀쩡해 보여도, 실제 코딩 세션처럼 컨텍스트가 점점 쌓이면 체감이 무너질 수 있기 때문이다.
안정성과 보안도 아직 완성형이라 보긴 이르다
오픈 이슈 기준으로는 prefix cache 디렉터리 이름 sanitization이 ..을 충분히 막지 못한다는 medium 이슈 #194, stream이 tool call 중간에 끊기면 partial tool call을 조용히 잃어버릴 수 있다는 #197도 열려 있다 (출처: Issue #194, Issue #197).
이런 항목은 당장 “쓰지 마라”의 근거는 아니다. 하지만 최소한 “아직 빠르게 성장하는 런타임이고, 품질 경계선이 움직이는 중”이라는 읽기는 필요하다.
완전 로컬이라고만 믿으면 안 되는 이유도 있다
README는 분명 “no cloud, no API costs”를 강조한다. 그런데 동시에 --cloud-model, --cloud-threshold 같은 smart cloud routing 옵션도 제공한다. 즉 기본값은 로컬이지만, 사용자가 이 옵션을 켜면 긴 컨텍스트 요청을 GPT나 Claude 같은 외부 모델로 우회시킬 수 있다 (출처: Rapid-MLX README).
또 #236 이슈를 보면 익명 사용 통계 수집 기능이 제안되어 있다. 현재는 shipped 기능이 아니라 proposal 단계이며, 설계 문서상 opt-in과 no PII를 강하게 강조한다. 그래도 독자 입장에선 “로컬 = 영원히 외부 전송 0”이라고 단순화해선 안 된다 (출처: Issue #236).
Rapid-MLX의 장점은 로컬 속도와 에이전트 친화성이다. 하지만 장기 세션 캐시 안정성, 공개 이슈 상태, 선택형 클라우드 라우팅까지 같이 읽지 않으면 글이 저장소 README 복붙처럼 보이기 쉽다.
| 리스크 | 어떤 상황에서 문제인가 | 독자 해석 |
|---|---|---|
| Issue #214 캐시 미스 | 길게 이어지는 코딩/에이전트 세션 | 짧은 데모와 실전 체감이 다를 수 있다 |
| Issue #194 path traversal | 캐시 디렉터리 이름 처리 | 보안 완성도가 아직 움직이는 중이다 |
| Issue #197 partial tool call drop | 스트리밍 중 tool call이 끊길 때 | 도구 호출 안정성은 검증 범위를 따져야 한다 |
| Cloud routing 옵션 | 긴 컨텍스트를 외부 모델로 우회할 때 | 완전 로컬 프라이버시 가정이 깨질 수 있다 |
누구에게 추천하고 누구에겐 아직 이른가?
Rapid-MLX는 좋은 의미로 취향이 분명한 도구다.
이런 사람에겐 잘 맞는다
첫째, Apple Silicon 맥을 메인 개발 머신으로 쓰는 사람. 둘째, Cursor·Claude Code·Aider 같은 코딩 에이전트를 로컬 모델에 붙여 비용과 프라이버시를 챙기고 싶은 사람. 셋째, GUI보다 로컬 API 서버와 CLI 워크플로우가 편한 사람이다.
이런 사용자라면 Rapid-MLX의 진짜 매력은 tok/s 숫자보다 연결성이다. “내 에이전트가 기존 방식 그대로 일하면서 뒤에서 로컬 모델이 받쳐주는가”가 핵심이다.
이런 사람에겐 아직 Ollama나 LM Studio가 더 낫다
GUI가 필요하거나, 팀 전체가 안정성을 최우선으로 보거나, 아직 로컬 모델 백엔드를 자주 바꿔볼 생각이 없다면 LM Studio나 Ollama 쪽이 더 편할 수 있다. 특히 “일단 가장 쉬운 로컬 AI부터”라면 Ollama의 기본값 지위는 아직 강하다.
이미 Ollama를 쓰는 사람은 왜 고민해야 하나?
여기서 판단 기준은 단순하다. 툴 호출 복구, 표준 API 호환, 프롬프트 캐시, Claude Code/Cursor 연동 같은 agent-first 기능이 아쉽다면 Rapid-MLX를 볼 이유가 있다. 반대로 모델 받아서 채팅하고 API 몇 번 부르는 정도면 굳이 갈아탈 이유가 약하다.
FAQ: Rapid-MLX에 대해 자주 묻는 질문
Rapid-MLX는 완전 무료인가요?
맥북 에어 16GB에서도 쓸 수 있나요?
이미 Ollama를 쓰는데 굳이 바꿔야 하나요?
Rapid-MLX는 새 로컬 모델인가요?
Claude Code와 Cursor에도 바로 붙나요?
완전 로컬이면 프라이버시 걱정이 없나요?
결론: 지금 Rapid-MLX를 갈아탈 이유가 있나?
정리하면 Rapid-MLX는 “맥에서 로컬 모델이 돌아간다” 수준의 얘기를 넘어, “맥에서 코딩 에이전트 백엔드를 어떻게 더 세밀하게 다룰 것인가”에 대한 답에 가깝다. Apple Silicon, MLX, 표준 API 호환, tool calling 복구, 캐시라는 조합이 딱 맞는 사용자에겐 꽤 매력적이다.
반대로 이 글을 읽고도 기억해야 할 건 하나다. Rapid-MLX는 아직 빠르게 성장하는 프로젝트다. 지금 시점의 가장 정직한 평가도 “흥미로운 차세대 기본값 후보”이지, 모든 맥 사용자에게 이미 결론 난 승자라고 하긴 어렵다.
한 줄 판단
Apple Silicon에서 Claude Code·Cursor 같은 에이전트를 로컬 모델에 붙이고 싶다면 Rapid-MLX는 지금 가장 눈여겨볼 만한 후보 중 하나다. 다만 속도 수치보다 실전 세션 안정성과 공개 이슈 상태를 먼저 확인하는 편이 맞다.
로컬 모델 자체가 먼저 궁금하면 Gemma 4 리뷰와 Qwen 3.6 리뷰를, 에이전트 연결 워크플로우가 궁금하면 Claude Code 완전 정복과 AI 앱은 프롬프트가 아니라 하네스로 완성된다를 이어서 보는 편이 좋다.
1단계 — 내 맥 메모리 확인
16GB, 24GB, 32GB, 64GB 이상 중 어디에 속하는지 먼저 본다.
2단계 — 작은 모델부터 서버 기동
Rapid-MLX를 설치한 뒤 4B 또는 9B 모델로 먼저 API 서버를 띄워 본다.
3단계 — 에이전트 툴 하나만 연결
Claude Code, Cursor, Aider 중 하나만 골라 Base URL 연결을 시험한다.
4단계 — 긴 세션과 도구 호출 검증
짧은 데모 말고 실제 수정 세션으로 캐시와 도구 호출 안정성을 확인한다.
- Rapid-MLX GitHub
- rapid-mlx PyPI
- MLX GitHub
- Ollama MLX preview blog
- LM Studio OpenAI compatibility docs
- 본문 한계 섹션에서 언급한 공개 이슈
#214,#194,#197,#236
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.

Gemma 4 완전 정리: 벤치마크, 한국어 성능, 로컬 설치까지
구글 Gemma 4의 모델 구성, 벤치마크 성능, Llama 4·Qwen 3.5 비교, 한국어 실사용 후기, Ollama 로컬 설치법까지 한 글에 정리한다.
읽기
RTX 4090에서 직접 돌려본 로컬 코딩 에이전트 후기 — Qwen 3.6 27B (2026)
RTX 4090과 Mac M4 Max에서 직접 돌려본 로컬 코딩 에이전트 후기. SWE-bench 77%·1M 컨텍스트·Apache 2.0 오픈소스 모델 Qwen 3.6 27B의 설치, VRAM, Claude 대비 실력을 정리했다.
읽기
무료로 내 노트북에서 젬마4 12B 로컬 실행하기 (Ollama·LM Studio)
구글 젬마4 12B를 내 노트북에서 무료로 돌리는 법. Ollama·LM Studio 설치, 16GB RAM·VRAM 사양 분기, 맥·윈도우 실행, GPU 인식·속도 오류 해결까지 단계별로 정리했다.
읽기