GLM 5.1 후기 2026: Claude Code 비용 1/5로 줄이는 법
GLM 5.1을 Claude Code에 붙여 Opus 대비 1/5 비용으로 쓰는 법부터, Z.AI 구독형 API·Vision MCP·GLM-Image 라인업까지 공식 문서 기준으로 정리.

빠른 결론
먼저 이렇게 보면 됩니다
약 58분 읽기한 줄 판단
GLM 5.1을 Claude Code에 붙여 Opus 대비 1/5 비용으로 쓰는 법부터, Z.AI 구독형 API·Vision MCP·GLM-Image 라인업까지 공식 문서 기준으로 정리.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- GLM 5.1 · Z.AI · Claude Code
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- GLM 5.1은 Z.AI(지푸 AI)가 2026년 4월 MIT 라이선스로 공개한 754B MoE 오픈웨이트 모델로, SWE-Bench Pro 58.4점을 찍으며 Claude Opus 4.6과 GPT-5.4를 꺾었다.
- Z.AI Coding Plan 월 $18(Lite) ~ $160(Max) 구독으로 Claude Code·Cline·OpenCode 같은 공식 지원 툴에서 전용 API 키를 발급받아 바로 연결할 수 있고, 일반 API 가격도 Opus 4.6 대비 1/5.7 수준이다.
- GLM 5.1 자체는 텍스트 전용이지만 Z.AI 전체 스택에는 GLM-5V-Turbo 비전 코딩 모델, Vision MCP, GLM-Image까지 있어 “싼 코딩 모델 하나” 이상으로 볼 만하다.
목차
- GLM 5.1은 실제로 Claude Opus 4.6을 꺾었을까?
- GLM 5.1 핵심 스펙 — 754B MoE가 Claude 5.7배 싼 이유
- SWE-Bench Pro 1위의 실체 — 벤치마크를 뜯어본다
- GLM 4.6에서 5.1로, 무엇이 달라졌나
- Z.AI Coding Plan 가격 — 월 $18부터 $160까지
- Claude Code에 GLM 5.1 붙이는 3가지 방법
- GLM 5.1만 보면 반쪽이다 — 비전 모델과 이미지 생성 모델
- GLM 5.1의 한계 — 벤치마크가 말하지 않는 것
- Z.AI 가입 절차와 초대코드 혜택
- 커뮤니티 반응 — 해외와 국내가 갈린다
- 트러블슈팅 Q&A
- 결론: 누가 지금 GLM 5.1을 써야 할까
GLM 5.1은 실제로 Claude Opus 4.6을 꺾었을까?
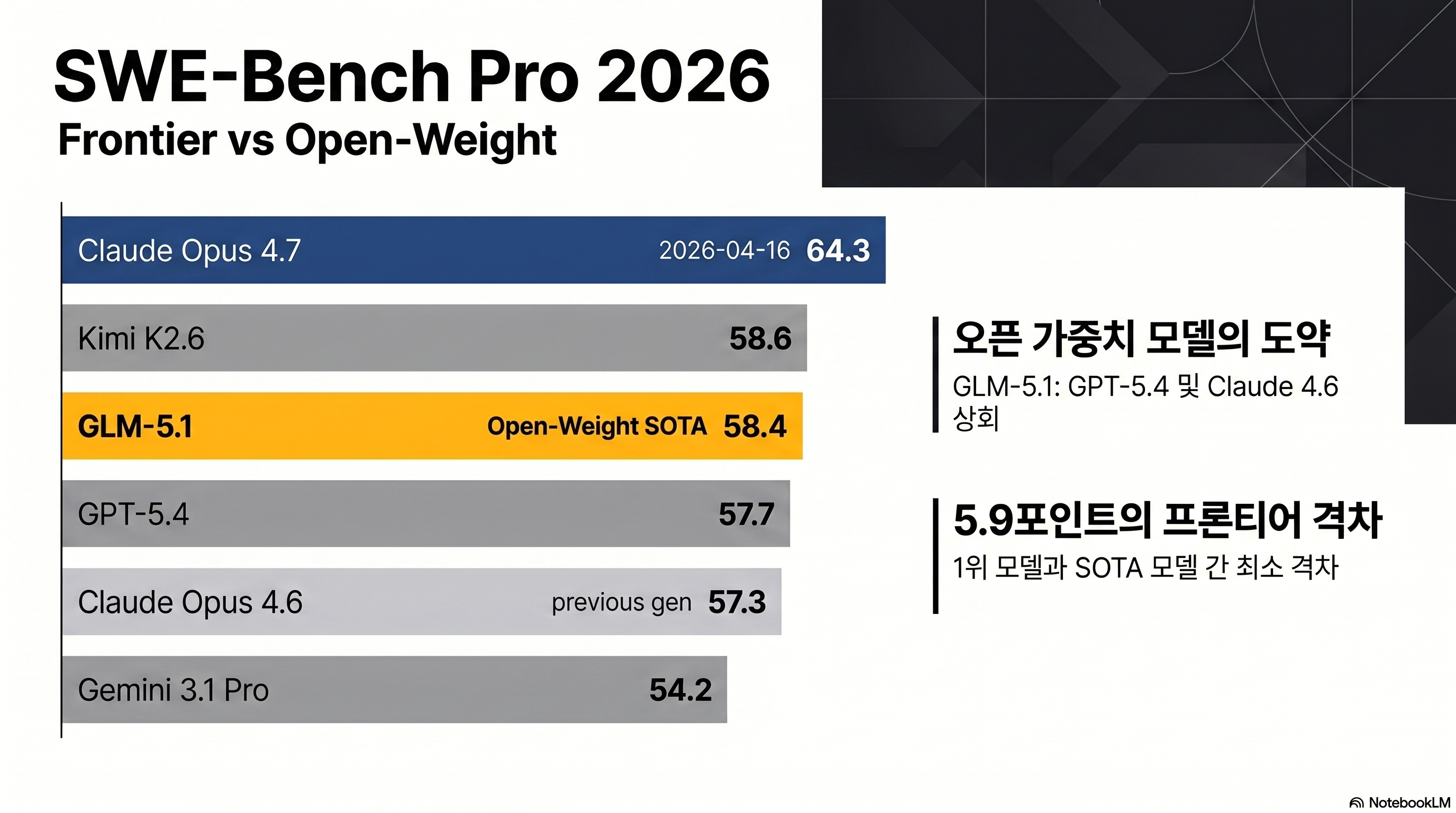
결론부터 말하면 “오픈웨이트 중에선 왕, 프론티어와는 여전히 격차”라는 답이 가장 정확하다. GLM 5.1이 출시 시점(2026-04-07)에 SWE-Bench Pro에서 58.4점을 기록하며 당시 현역이던 Claude Opus 4.6(57.3)과 GPT-5.4(57.7)를 0.7–1.1포인트 차이로 제친 건 수치로 확인된다(출처: Z.AI 공식 기술 리포트). 다만 그로부터 9일 뒤인 4월 16일 Claude Opus 4.7 총정리가 출시되며 상황은 다시 뒤집혔다. Opus 4.7은 SWE-Bench Pro 64.3, SWE-Bench Verified 87.6으로 GLM 5.1보다 각각 5.9 · 9.8포인트 앞선다(출처: Anthropic 공식). Artificial Analysis Intelligence Index(v4.0 신 방법론) 기준으로도 Opus 4.7·GPT-5.4·Gemini 3.1 Pro가 57점으로 공동 1위, GLM 5.1은 51점으로 6점 뒤에 붙어 있다(출처: Artificial Analysis).
한 줄 요약: 코딩 전용 오픈웨이트의 새 왕
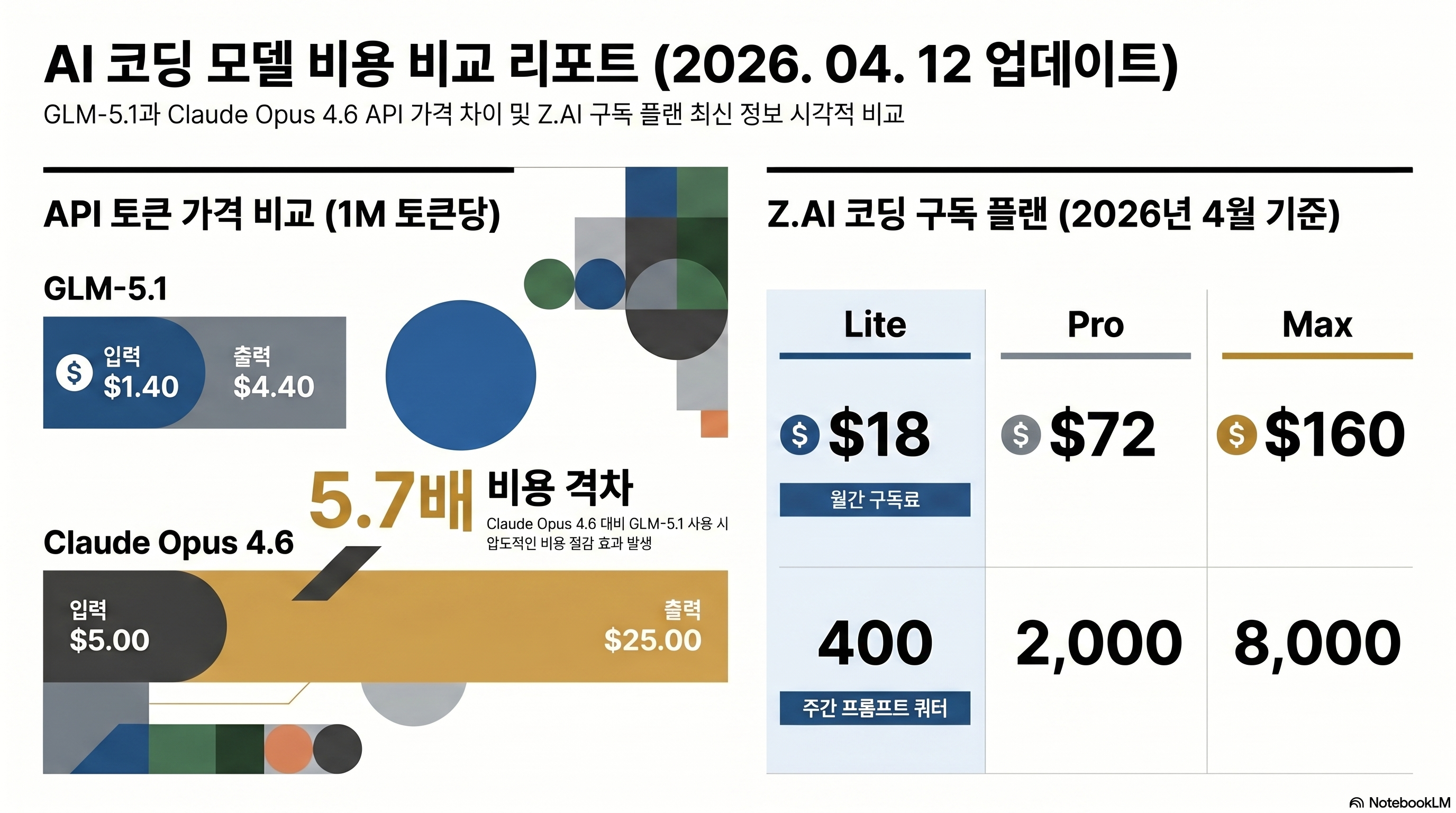
GLM 5.1은 중국 Zhipu AI(지푸 AI)가 2026년 3월 27일 Coding Plan 형태로 선공개하고, 4월 7일 HuggingFace에 MIT 라이선스 오픈웨이트로 풀어둔 모델이다. 총 파라미터 754B에 활성 40B짜리 MoE(Mixture of Experts)고, 200K 컨텍스트·128K 출력·텍스트 전용이다. 핵심 포인트는 라이선스·가격·코딩 성능 3박자가 맞물렸다는 것이다. MIT라 상업적 재학습·배포가 자유롭고, API 기준 입력 1M 토큰당 $1.40로 Opus 4.6의 $5.00 대비 28% 수준이며, SWE-Bench Pro·BrowseComp·Terminal-Bench 2.0에서 오픈웨이트 SOTA를 달고 있다.
왜 지금 이 글을 읽어야 하나
이전 세대 GLM 4.x를 가성비 대안으로 보던 흐름에서, 최근 관심은 자연스럽게 상위 모델인 GLM 5.1로 넘어왔다. 필자도 Claude Code Max와 Coding Plan Pro($72/mo)를 번갈아 3주 정도 써보면서 체감 차이를 정리해봤고, 개인 결론은 “일상 코딩 상당수는 GLM 쪽으로 옮길 수 있지만, 어려운 아키텍처 판단은 여전히 Claude Opus 4.7 총정리가 더 안전하다”는 쪽이다. 이 글은 그 경험과 공식 문서를 함께 묶어 벤치마크·비용·세팅·함정을 정리한다.
이 글이 다루는 범위
- 벤치마크 실체: SWE-Bench Pro·Verified·Terminal-Bench·AIME·GPQA 원본 수치와 신뢰도 검증
- 가격 구조: Z.AI Coding Plan 3개 티어와 API 토큰 단가, OpenRouter 경유 여부 비교
- 실전 세팅: Claude Code에 환경변수로 직접 붙이기, Claude Code Router(CCR)로 모델별 라우팅, API 직접 호출
- 공식 문서 기준 보강: Coding Plan API 사용 범위, Vision MCP, GLM-5V-Turbo, GLM-Image 라인업 재점검
- 한계와 커뮤니티 반응: HackerNews·Reddit·Medium에서 나온 부정적 리포트 원문 인용
GLM 5.1 핵심 스펙 — 754B MoE가 Claude 5.7배 싼 이유
GLM 5.1의 가격 경쟁력은 “큰 모델을 띄엄띄엄 쓴다”는 MoE 설계에서 나온다. 총 754B 파라미터 중 토큰당 활성은 40B뿐이다.
아키텍처: MoE + DSA 조합
256개의 expert 중 쿼리마다 8개만 라우팅하는 희소 활성 구조를 쓰고, 여기에 DeepSeek가 GLM 팀과 공유한 DSA(DeepSeek Sparse Attention)를 얹었다. DSA는 긴 컨텍스트에서 KV 캐시 압축 효율을 끌어올리는 기술로, GLM 5.1이 200K 컨텍스트를 유지하면서도 추론 단가를 낮출 수 있던 배경이다(출처: Z.AI 기술 리포트). 훈련은 28.5T 토큰으로, 흥미롭게도 NVIDIA GPU가 아닌 Huawei Ascend 910B 10만 칩으로 수행되었다(출처: VentureBeat). 미·중 반도체 규제 국면에서 국산화 레퍼런스로 거론되는 대목이다.
대표 경쟁 모델과의 스펙 비교
| 항목 | GLM 5.1 | Claude Opus 4.7 | Kimi K2.6 | GPT-5.4 |
|---|---|---|---|---|
| 총 파라미터 | 754B MoE | 비공개 | 1T MoE | 비공개 |
| 활성 파라미터 | 40B (8/256) | 비공개 | 32B | 비공개 |
| 컨텍스트/출력 | 200K / 128K | 1M / 128K | 256K / 128K | 400K / 128K |
| 멀티모달 | 텍스트 전용 | 텍스트+이미지 | 텍스트+이미지 | 텍스트+이미지+오디오 |
| 라이선스 | MIT 오픈웨이트 | 독점 | Modified MIT | 독점 |
| API 입력 $/1M | 1.40 | 5.00 | 0.60 | 1.25 |
| API 출력 $/1M | 4.40 | 25.00 | 2.50 | 10.00 |
(출처: Z.AI 가격, Anthropic 가격, Moonshot, OpenAI)
5.7배라는 숫자가 실제 비용에서 의미하는 것
Opus 4.7 대비 출력 단가 5.7배라는 숫자는 같은 작업을 반복할 때 차이가 누적된다. Claude Code로 하루 5시간 바이브코딩을 하면 출력 토큰 기준 200만 토큰은 쉽게 찍는 수준인데, 이 워크로드를 API 직접 과금으로 풀면 아래처럼 벌어진다.
월 비용 환산 — 출력 200만 토큰 · 하루 5시간 기준
- Claude Opus 4.7 API 직접: 약 월 $1,500
- GLM 5.1 API 직접: 약 월 $264 (캐시 히트 끼우면 $50 이하)
- Z.AI Coding Plan Pro 구독: 월 $72 (사실상 무제한 체감)
다만 이 차이가 Opus의 판단력까지 5.7배 저렴하게 산다는 뜻은 아니다. 뒤에서 벤치마크로 다시 짚는다. 동급 가격대에서 비교하려면 Kimi K2.6 완전분석을 함께 보면 관점이 잡힌다.
SWE-Bench Pro 1위의 실체 — 벤치마크를 뜯어본다
벤치마크 한두 개만 이기고 SOTA를 외치는 경우가 많으니, 코딩·추론·에이전트·장기 실행을 골고루 본다.
코딩: SWE-Bench Pro에서 0.7점 차 1위, Verified에서는 5위권
| 벤치마크 | GLM 5.1 | Claude Opus 4.7 | Kimi K2.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | 64.3 | 58.6 | 57.7 | 54.2 |
| SWE-Bench Verified | 77.8 | 87.6 | 80.2 | 78.2 | — |
| Terminal-Bench 2.0 | 63.5 | 69.4 | — | 75.1 | 68.5 |
| BrowseComp | 68.0 | 79.3 | — | 89.3 | — |
| AIME 2026 | 95.3 | 미공개 | — | 98.7 | 98.2 |
| GPQA Diamond | 86.2 | 94.2 | 87.6 | 94.4 | 94.3 |
(출처: Z.AI 공식 리포트, benchlm.ai, artificialanalysis.ai)
SWE-Bench Pro는 실제 오픈소스 저장소에서 뽑은 버그 이슈를 LLM이 직접 고쳐 PR을 제출하는 벤치마크다. GLM 5.1의 58.4는 출시 시점에 전체 2위(Kimi K2.6 58.6 다음)였지만, 4월 16일 공개된 Claude Opus 4.7이 64.3으로 치고 올라오면서 GLM 5.1은 오픈웨이트 SOTA, 프론티어 포함 3위로 재조정됐다. 조금 더 정제된 SWE-Bench Verified에서는 77.8로 Claude Opus 4.7(87.6) · Sonnet 4.6(79.6) · Kimi K2.6(80.2) · GPT-5.4(78.2)에 모두 밀리며 5위권이다. 즉 코딩 최상위권이되 프론티어급 완성도는 아직이라는 해석이 적절하다.
추론·수학: 상위권이되 1위는 아님
AIME 2026에서 GLM 5.1은 95.3으로 GPT-5.4(98.7) · Gemini 3.1 Pro(98.2) · Opus 4.6(95.6, Opus 4.7은 AIME 수치 미공개)에 이은 4위다. 무시할 수준은 아니지만 수학 경시대회 난이도에서 3–4% 정도 격차가 존재한다. GPQA Diamond(박사급 과학 추론)는 더 벌어진다. GLM 5.1 86.2 vs Opus 4.7 94.2 · Gemini 3.1 Pro 94.3으로 8포인트 차이가 난다. 복잡한 과학·의학·법률 추론이 주된 작업이라면, 단가가 조금 비싸도 Opus 4.7이나 Gemini 쪽 선택이 안전하다.
에이전트·장기 실행: Vending Bench 2는 여전히 Opus가 앞선다
Vending Bench 2는 8시간 연속 자율 판매·재고·가격 결정 시뮬레이션으로 장기 일관성을 본다. Claude Opus 4.6이 $8,017을 벌 때 GLM 5.1은 $5,634로 약 70% 수준이다(출처: VentureBeat). 다만 Kimi K2.6($1,198) · DeepSeek V3.2($1,034)와 비교하면 GLM 5.1이 오픈웨이트 중에서 압도적으로 장기 실행에 강하다. Z.AI가 “8시간 자율 실행, 1,700 스텝 연속 작업”을 마케팅 포인트로 잡은 근거가 이쪽이다.
웹 에이전트: BrowseComp에서 GLM 5가 쌓은 장점이 이어짐
BrowseComp는 실제 웹을 서핑해 정답을 찾는 벤치마크다. GLM 5.1 68.0은 전세대 GLM 5(62.0) · DeepSeek V3.2(51.4)를 넉넉히 앞선다. Claude Code에서 로컬 개발과 웹 리서치를 함께 시키는 워크플로에는 체감이 꽤 온다.
⚠️ 주의: Z.AI 공식 리포트의 SWE-Bench Pro 수치는 자체 셋업이다. r/LangChain 등 일부 커뮤니티에서는 GLM 5.1이 Opus 4.6을 0.7–1.1포인트 앞섰다는 결과가 훈련 데이터 오염 때문 아니냐는 의혹이 올라왔다(출처: r/LangChain). 실전 워크로드는 본인의 레포로 직접 재봐야 한다.
GLM 4.6에서 5.1로, 무엇이 달라졌나
2025년 9월 30일 출시된 GLM 4.6은 아직도 Claude Code Router 사용자들이 Haiku 대체로 애용하는 모델이다. 5.1로 넘어오면서 바뀐 포인트를 정리한다.
파라미터·아키텍처: 355B → 754B, expert 구조 교체
GLM 4.6은 355B MoE · 32B active였고, 5.1은 754B · 40B로 총량은 2.1배, 활성은 1.25배로 뛰었다. 대신 expert 숫자가 크게 늘어 얇고 많은 expert 방향으로 갔다. 덕분에 동일 활성 파라미터 대비 전문 도메인 적중이 개선됐고, GLM 5.1의 BrowseComp·SWE-Bench Pro 상승 폭이 이 구조 변경과 맞물린다.
벤치마크 점프 폭
| 벤치마크 | GLM 4.6 | GLM 5.1 | 점프 폭 |
|---|---|---|---|
| SWE-Bench Verified | 68.0 | 77.8 | +9.8 |
| Terminal-Bench 2.0 (대비 GLM 5) | 56.2 | 63.5 | +7.3 |
| BrowseComp (대비 GLM 5) | 62.0 | 68.0 | +6.0 |
| AIME 2026 (대비 GLM 5) | 95.4 | 95.3 | -0.1 |
| Vending Bench 2 수익 ($) | 4,432 | 5,634 | +27% |
SWE-Bench Verified 기준으로 GLM 4.6 68.0 → GLM 5.1 77.8로 9.8포인트 상승했다. Terminal-Bench 2.0은 GLM 5 56.2 → GLM 5.1 63.5로 +7.3이다. 세대 교체 한 번에 오픈웨이트 SOTA 구간으로 진입했다는 표현이 과장이 아니다. 새로 세팅을 잡는 관점에서 보면, 4.6을 메인으로 고집할 이유는 예산 최저선을 극단적으로 깎아야 하는 경우로 많이 좁아졌다.
라이선스·배포 정책 변화
GLM 4.6은 MIT 기반이되 일부 상업 제한 문구가 있었지만, 5.1은 완전한 MIT로 공개되었다. 재학습·파인튜닝·재배포·상업 이용에 제약이 없다. 오픈소스 LLM 라이선스 지형 전체를 보려면 Gemma 4 완전 정리와 묶어서 보면 구글·중국·메타의 라이선스 정책 차이를 체감할 수 있다.
Z.AI Coding Plan 가격 — 월 $18부터 $160까지
GLM 5.1을 가장 싸게 쓰는 경로는 API가 아니라 Coding Plan 구독이다.
3개 티어 가격과 쿼터
| 플랜 | 월간 결제 | 분기 결제 환산(약 10% 할인) | 5시간 프롬프트 | 주당 | 월당 |
|---|---|---|---|---|---|
| Lite | $18 | 약 $16/mo | 80 | 400 | 1,600 |
| Pro | $72 | 약 $65/mo | 400 | 2,000 | 8,000 |
| Max | $160 | 약 $144/mo | 1,600 | 8,000 | 32,000 |
(출처: Z.AI Coding Plan 공식 페이지, Z.AI Devpack Overview)
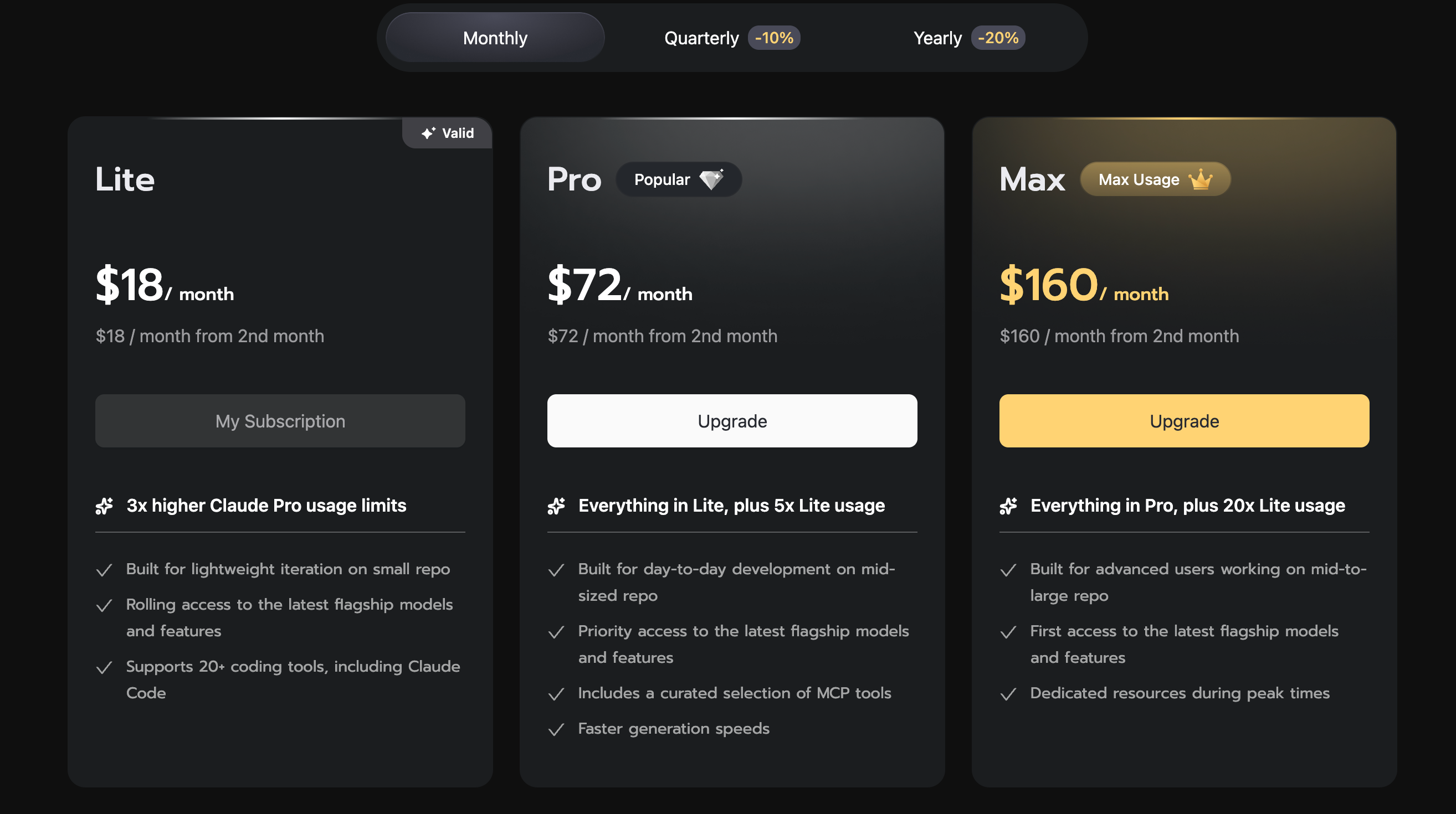
현재 공개 가격표 기준으로 Lite는 월 $18, Pro는 $72, Max는 $160이다. 분기 결제 토글 기준으로는 Lite가 월 $16 전후, Pro가 $65 전후, Max가 $144 전후까지 내려간다. 요금제와 프로모션은 자주 바뀔 수 있으니 결제 직전 공식 구독 페이지에서 최종 금액을 재확인하는 편이 안전하다. 여기서 주의할 점은 1 프롬프트의 정의다. Z.AI는 사용자가 IDE에 한 번 타이핑해서 엔터 친 단위를 1 프롬프트로 세지만, 내부적으로는 그 한 번의 요청이 15–20회 모델 호출로 확장되는 경우가 흔하다(툴 호출·사고 체인 포함). 따라서 Lite 400 프롬프트/주는 가볍게 40–50개 이슈 해결 정도이고, Pro 2,000은 하루 종일 Claude Code 수준이다.
구독과 일반 API는 공존한다 — 핵심은 Plan 쿼터와 별도 과금의 구분
공식 Quick Start와 Devpack 문서를 같이 보면, Coding Plan 구독자는 구독 후 API 키를 발급받아 Claude Code에서는 https://api.z.ai/api/anthropic, 그 외 공식 지원 툴에서는 https://api.z.ai/api/coding/paas/v4를 통해 모델을 호출할 수 있다. 이게 중요한 이유는 월정액 구독과 키 기반 설정이 동시에 성립한다는 뜻이기 때문이다. 즉 “구독형이라서 웹 UI에서만 쓴다”가 아니라, 평소 쓰던 코딩 툴의 base URL과 key에 그대로 꽂아 넣는 흐름이 가능하다(출처: Z.AI Quick Start, Z.AI Coding Plan Quick Start).
다만 2026년 5월 4일 기준 공식 문서는 이 지점에서 표현이 약간 엇갈린다. Overview, Usage Policy, FAQ는 Coding Plan의 구독 혜택과 쿼터는 공식 지원 툴 안에서만 쓴다고 강조하고, API 호출은 별도 과금이라고 적는다. 반면 TRAE 연동 문서는 Z.ai-plan과 Z.ai를 명시적으로 구분하면서, Z.ai-plan은 Plan 쿼터를 쓰고 Z.ai는 general API로 라우팅되어 balance에서 standard pricing으로 차감된다고 설명한다. 그래서 지금 시점에 더 정확한 해석은 “범용 API 호출 자체가 불가능하다”가 아니라, “일반 API 호출은 가능할 수 있지만 Coding Plan 포함 혜택으로 보는 건 부정확하고, 별도 과금 경로로 이해해야 한다”에 가깝다(출처: Z.AI Coding Plan Overview, Z.AI Usage Policy, Z.AI Coding Plan FAQ, Z.AI TRAE Guide).
피크 시간 3배 차감은 한국 오후 내내
Z.AI는 UTC+8 기준 14–18시에 GLM 5.1 쿼터를 3× 차감한다. 한국 시간으로는 15–19시가 피크 구간이라 오후 내내 평소의 1/3 용량만 쓸 수 있다. 반대로 오프피크(피크 외 시간)는 원래 2× 차감인데, 공식 문서 기준으로 2026년 6월 말까지는 한시적으로 1×만 깎는다. 한국 개발자 입장에서는 피크 시간을 피해 새벽·오전에 몰아서 쓰는 루틴이 쿼터를 3배 아끼는 길이다(출처: Z.AI Coding Plan Overview, Z.AI Coding Plan FAQ).
API 직접 호출이 유리한 경우
단발성 요청, 배치 파이프라인, 자체 앱 임베딩이라면 Coding Plan이 아니라 API가 낫다. GLM 5.1은 Z.AI 공식 API에서 입력 $1.40/1M, 캐시 입력 $0.26/1M, 출력 $4.40/1M이다. OpenRouter를 경유하면 입력 $1.05 · 출력 $3.50로 본사보다 오히려 싸다(출처: OpenRouter GLM-5.1). 다만 OpenRouter는 캐시를 걸 수 없어 반복 컨텍스트가 많은 워크로드(Claude Code 스타일)에선 캐시 히트가 가능한 Z.AI 본사 API가 결국 더 싸다.
필자 개인 테스트 기준으로는, 3주간 Pro 플랜에서 하루 5시간 안팎의 Claude Code 워크플로를 돌렸을 때 대부분의 일상 작업은 GLM 쪽에서 처리됐다. 막히는 구간은 복잡한 리팩터링이나 20분 이상 자율 실행 같은 장기 과제에 몰렸다. 정량 벤치마크라기보다 개인 워크플로 관찰치에 가깝고, 실제 체감은 레포 크기와 작업 유형에 따라 달라질 수 있다.
Claude Code에 GLM 5.1 붙이는 3가지 방법
Z.AI가 Coding Plan을 전략적으로 설계한 핵심이 Anthropic API 호환 엔드포인트다. 공식 문서 기준 최소 세팅은 ANTHROPIC_AUTH_TOKEN, ANTHROPIC_BASE_URL, API_TIMEOUT_MS 3개고, 여기에 모델 슬롯 매핑만 추가하면 Claude Code 백엔드를 GLM 5.1로 바꿀 수 있다.
방법 1: Claude Code에 GLM 5.1 붙이기 (Z.AI 공식 권장)
Z.AI Coding Plan에서 API 키를 발급받은 뒤, 아래 두 경로 중 하나로 Claude Code에 연결한다. 영구 사용이면 1-a, 하루만 써볼 실험이면 1-b가 적절하다.
1-a. ~/.claude/settings.json 영구 세팅 (권장)
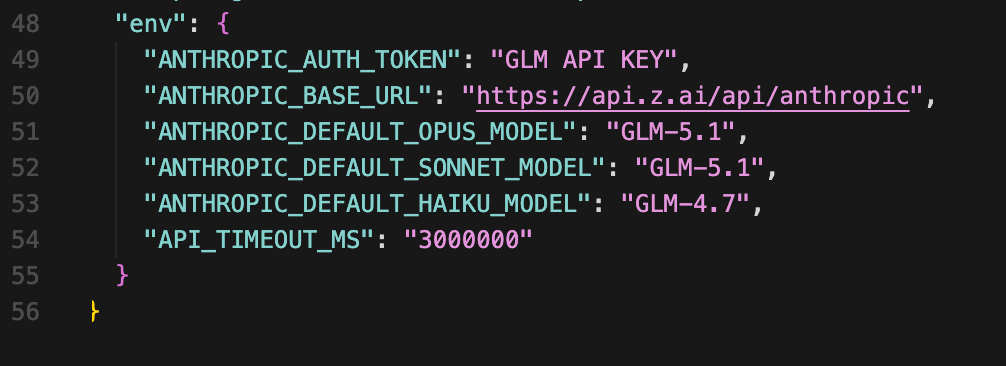
Claude Code의 공식 설정 파일에 JSON 한 덩어리를 꽂는다. 재부팅·새 터미널·Windows/macOS/Linux 어디서든 한 번 세팅하면 유지된다. Z.AI가 GLM Coding Plan Quick Start에서 안내하는 방식이다. 공식 문서의 최소 예시는 인증 토큰·base URL·timeout까지만 넣고, 아래 예시는 여기에 GLM-5.1 고정용 모델 매핑을 더한 실전형 설정이다.
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "zai-xxxxxxxxxxxxxxxx",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "GLM-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "GLM-5.1",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "GLM-4.7",
"API_TIMEOUT_MS": "3000000"
}
}
각 키가 하는 일:
ANTHROPIC_AUTH_TOKEN·ANTHROPIC_BASE_URL— Z.AI API 키와 Anthropic 호환 엔드포인트ANTHROPIC_DEFAULT_OPUS_MODEL / SONNET / HAIKU— Claude Code 내부의 3개 모델 슬롯(Opus=어려운 판단, Sonnet=일반 코딩, Haiku=빠른 요약·자동완성)에 각각 어떤 GLM 모델을 연결할지 지정. 무거운 작업은GLM-5.1, 가벼운 자동완성은 더 저렴한GLM-4.7로 분리하면 쿼터를 아낄 수 있다. CCR 없이도 기본 슬롯 라우팅은 여기서 바로 끝난다.API_TIMEOUT_MS: 3000000— 50분 타임아웃. GLM 5.1의 장시간 자율 실행 중간에 끊기지 않도록 여유를 주는 값
파일을 만든 뒤 새 터미널에서 claude를 실행하면 적용된다. 기존 settings.json이 있다면 env 객체만 병합 추가하고 통째로 덮어쓰지 않는다.
GLM을 끄고 Anthropic 공식 엔드포인트로 돌아가려면 settings.json의 env 객체를 삭제하거나 파일 자체를 비운 뒤(JSON은 주석 미지원) 새 터미널에서 claude를 재실행하면 된다. 3개 모델 슬롯 매핑도 함께 초기화된다. 여러 프로바이더를 작업별로 세밀하게 섞어 쓰려면 다음의 CCR 방식이 더 유연하다.

1-b. 환경변수로 임시 테스트
“하루만 GLM으로 써볼까” 또는 “GLM vs Claude A/B 비교” 같은 실험용이면 셸에 직접 export하는 편이 빠르다. 터미널을 닫으면 자동으로 Claude 엔드포인트로 복귀한다.
export ANTHROPIC_AUTH_TOKEN="zai-xxxxxxxxxxxxxxxx"
export ANTHROPIC_BASE_URL="https://api.z.ai/api/anthropic"
claudezsh를 쓰는 유저는 ~/.zshrc, bash는 ~/.bashrc에 영구 등록할 수도 있지만 그 경우 Claude Code 외 다른 도구에도 영향을 주므로, 영구 사용이면 위 1-a를 권장한다. Claude Code 자체의 일반 세팅은 Claude Code 완전 정복에 정리해뒀다.
방법 2: Claude Code Router(CCR)로 작업별 라우팅
Claude Code Router는 Claude Code가 내부적으로 호출하는 Haiku용 · Sonnet용 모델을 각각 다른 백엔드로 라우팅해주는 프록시다. 실전에서는 아래 조합이 가성비가 높다.
- Haiku(자동 완성·요약) → GLM 4.7 (저렴한 초경량 모델)
- Sonnet(일반 코딩) → GLM 5.1
- Opus(어려운 판단) → Claude Opus 4.7 API 직접
CCR 설정 파일은 JSON 포맷 한 덩어리다.
{
"providers": {
"z-ai": { "base_url": "https://api.z.ai/api/anthropic", "api_key": "zai-xxx" },
"anthropic": { "base_url": "https://api.anthropic.com", "api_key": "sk-ant-xxx" }
},
"routing": {
"haiku": { "provider": "z-ai", "model": "glm-4.7" },
"sonnet": { "provider": "z-ai", "model": "glm-5.1" },
"opus": { "provider": "anthropic", "model": "claude-opus-4-7" }
}
}이 구성이면 바이브코딩 90%는 GLM으로 받고, 일주일에 2–3번쯤 발생하는 아키텍처 레벨 판단만 Opus에 맡긴다. 필자는 월 Opus API 비용이 $30 아래로 떨어졌다.
방법 3: API 직접 호출 + 컨텍스트 캐싱
앱에 임베딩하거나 파이프라인을 돌리는 쪽이라면 Anthropic 호환 SDK를 그대로 쓰면 된다. 캐시 키만 잘 쪼개도 반복 시스템 프롬프트·도구 정의 비용이 1/5.4로 떨어진다.
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.z.ai/api/anthropic",
api_key="zai-xxx",
)
resp = client.messages.create(
model="glm-5.1",
max_tokens=4096,
system=[{"type": "text", "text": LONG_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}}],
messages=[{"role": "user", "content": "이 PR 요약해줘"}],
)cache_control 블록을 붙이면 동일 시스템 프롬프트 재사용 시 입력가가 $1.40 → $0.26으로 떨어진다. 200K 시스템 프롬프트를 1,000번 재사용하는 파이프라인에서 월 수십 달러 단위로 줄어든다.
⚠️ 주의: ANTHROPIC_AUTH_TOKEN을 셸에 export한 상태에서 .env 파일을 만들어 커밋하는 실수가 흔하다. .gitignore에 .env · .env.local을 반드시 추가하고, 1Password CLI 같은 secrets manager를 쓰는 편이 안전하다. Z.AI 대시보드에서 키 회전은 클릭 2번이지만 유출된 키로 쿼터가 소진되는 일이 드물지 않다.
GLM 5.1만 보면 반쪽이다 — 비전 모델과 이미지 생성 모델
공식 문서를 몇 장만 더 보면, Z.AI의 매력은 GLM 5.1 단일 모델보다 “구독형 코딩 + 별도 멀티모달 + 이미지 생성” 조합에 가깝다. 특히 스크린샷 이해, 디자인 투 코드, 다이어그램 생성까지 같이 원하는 사용자라면 이 섹션이 오히려 핵심이다.
| 용도 | 모델/기능 | 입력 | 과금/제한 | 언제 쓰나 |
|---|---|---|---|---|
| 장문 코딩·에이전트 | GLM-5.1 | 텍스트 | $1.4 / $4.4 per 1M 또는 Coding Plan 쿼터 | 리팩터링, 테스트 작성, 장기 실행 |
| 스크린샷·GUI 이해 | GLM-5V-Turbo 또는 Vision MCP(GLM-4.6V) | 이미지·영상·파일 | GLM-5V-Turbo $1.2 / $4.0 per 1M, Vision MCP는 Plan 쿼터 | UI 분석, 디자인 투 코드, 오류 화면 진단 |
| 이미지 생성 | GLM-Image | 텍스트 | $0.015 / image | 포스터, 도식, 썸네일 시안, 설명용 그래픽 |
(출처: Z.AI Overview, Z.AI Pricing, GLM-5V-Turbo, GLM-Image)
Coding Plan에는 Vision MCP가 같이 붙는다
공식 Devpack 문서 기준으로 모든 Coding Plan은 Vision Understanding, Web Search, Web Reader, Zread MCP를 지원한다. 특히 Vision MCP는 GLM-4.6V를 써서 스크린샷 텍스트 추출, 오류 화면 분석, UI-투-코드 같은 작업을 처리한다. Lite·Pro·Max에 따라 웹 검색/리더 월간 쿼터가 각각 100·1,000·4,000으로 다르고, Vision MCP는 모델의 5시간 프롬프트 풀을 함께 쓴다. 즉 “구독형인데도 에이전트에 눈을 붙여주는 옵션이 같이 온다”는 점이 생각보다 큰 장점이다(출처: Z.AI Coding Plan Overview, Z.AI Vision MCP Server).
일반 API에는 GLM-5V-Turbo가 있다
GLM-5V-Turbo는 Z.AI가 “첫 멀티모달 코딩 파운데이션 모델”이라고 소개하는 모델이다. 이미지·영상·텍스트·파일을 입력으로 받아 200K 컨텍스트, 128K 출력으로 응답하고, 비전 기반 코딩 작업에 특화되어 있다. 공식 문서가 직접 예시로 드는 용도도 디자인 목업을 코드로 재구성하기, 버그 스크린샷에서 레이아웃 문제 찾기, 아키텍처 다이어그램 읽기 같은 것들이다. 그래서 “GLM 5.1은 텍스트 전용이라 프론트엔드엔 약하다”는 말은 맞지만, “Z.AI 전체가 비전이 약하다”는 뜻은 아니다(출처: GLM-5V-Turbo).
이미지 생성은 GLM-Image로 분리돼 있다
이미지 생성은 GLM-Image가 맡는다. 공식 문서에 따르면 가격은 장당 $0.015이고, 1:1·3:4·4:3·16:9 비율을 지원한다. Z.AI가 특히 강점으로 내세우는 영역은 포스터, PPT, 과학 일러스트처럼 텍스트가 많이 들어가는 그림이다. 쉽게 말해 “코드 에이전트용 텍스트 모델”과 “비전 코딩 모델”, “이미지 생성 모델”이 각각 분리되어 있어, 필요한 능력을 용도별로 골라 쓰는 구조에 가깝다(출처: GLM-Image, Z.AI Pricing).
GLM 5.1의 한계 — 벤치마크가 말하지 않는 것
마케팅 카드에서는 잘 안 보이는 실전 약점 6가지를 정리한다.
GLM 5.1 자체는 텍스트 전용 — 제품 전체는 아니다
여기서 가장 헷갈리기 쉬운 대목이 나온다. GLM 5.1 모델 자체는 이미지 입력을 받지 못한다. 따라서 한 세션에서 스크린샷을 바로 던져 “이 버튼 왜 밀렸지?”를 묻는 플로우는 GLM 5.1 단독으로는 안 된다. 다만 Z.AI 제품 전체에는 GLM-5V-Turbo와 Vision MCP(GLM-4.6V)가 있으므로, 정확히는 “Z.AI에 비전이 없다”가 아니라 “GLM 5.1 하나로 텍스트·이미지·에이전트를 모두 끝내기엔 분리가 필요하다”가 맞다. 한 모델 일원화가 중요하다면 여전히 Opus 4.7이나 Gemini 3.1 Pro가 더 단순하다.
100–128K 토큰 근방 일관성 급락
HackerNews 유저 jauntywundrkind가 올린 관찰이 가장 정확하다. 짧은 대화에서는 안정적이지만 컨텍스트가 100K 토큰을 넘어가는 구간에서 예측 가능하게 급격히 품질이 떨어진다(출처: HackerNews 댓글). 200K 컨텍스트를 광고하지만 실전에서 안전하게 쓸 수 있는 구간은 80K 전후로 보는 게 낫다. 대형 레포 전체를 한 번에 넣기보다는 청킹이 필요하다.
로컬 실행 사실상 불가
754B 모델 FP8 추론에는 H200 8장 이상이 필요하다. 양자화 GGUF(~135GB)는 Mac Studio 256GB 환경에서도 토큰/초가 한 자릿수로 떨어져 실용적이지 않다. 오픈웨이트는 연구·파인튜닝·커스텀 배포용이지, 일반 개발자가 로컬로 돌리기 위한 선택지는 아니다.
지연시간·안정성 이슈
HN 유저 kay_o의 후기를 그대로 옮기면 단순 CSS 변경 요청 하나에 50분 이상 대기가 걸렸고 529 에러를 반복적으로 만났다는 수준이다. RickHull 역시 양자화 버전을 쓰다가 1/4–1/5 빈도로 파일 손상 또는 디렉토리 삭제가 발생했다고 기록했다(출처: HackerNews 스레드). Claude Code 수준의 에이전트 안정성이 아니라는 점을 받아들여야 한다.
피크 시간 3× 쿼터 차감
한국 기준 오후 3–7시가 통째로 3× 구간이라, 정규 근무 시간에 Lite($18)를 쓰면 주당 400 프롬프트가 실질 133개로 느껴진다. Pro 이상이 사실상 기본선이다. 상세는 앞 가격 섹션 참고.
벤치마크 오염 의혹
SWE-Bench Pro에서 Opus 4.6 · GPT-5.4를 0.7–1.1포인트로 꺾은 결과는 표준 오차 범위에 가깝다. r/LangChain에서는 훈련 데이터에 벤치마크가 일부 섞였을 가능성을 제기한다. 수치 그대로 받아들이기보다는 자기 레포·자기 언어·자기 라이브러리로 재현해보는 편이 낫다.
장점
- + MIT 라이선스 오픈웨이트로 상업 이용·재학습 제약 없음
- + SWE-Bench Pro 58.4 — 오픈웨이트 코딩 SOTA, Opus 4.6 대비 출력가 1/5.7
- + Coding Plan 구독만으로 공식 지원 툴 전용 API 키 + Vision/Web MCP를 함께 사용 가능
- + GLM-5V-Turbo와 GLM-Image까지 같은 문서 체계에서 이어져 스크린샷 이해·이미지 생성 확장이 쉽다
- + 200K 컨텍스트·128K 출력, BrowseComp 68점으로 웹 에이전트 강세
- + 8시간 1,700스텝 연속 자율 실행 지원, Vending Bench 2 오픈웨이트 1위
단점
- − GLM 5.1 자체는 텍스트 전용 — 스크린샷 분석은 GLM-5V-Turbo·Vision MCP나 다른 멀티모달 모델로 분리해야 함
- − 100–128K 토큰 근방 컨텍스트에서 일관성이 예측 가능하게 급락
- − 지연시간·안정성 이슈 — 529 에러 빈번, 파일 손상·디렉토리 삭제 리포트 존재
- − 한국 오후 3–7시 피크 쿼터 3× 차감 — Lite($18) 플랜은 정규 근무시간에 체감이 나쁨
- − 로컬 실행은 사실상 불가 — FP8 H200 8장 이상, 양자화본도 실용 속도 미달
- − SWE-Bench Pro 1위 격차가 0.7–1.1포인트로 좁아 오염 가능성 의혹 존재
Z.AI 가입 절차와 초대코드 혜택
신규 가입에 필요한 3단계
Z.AI 계정 생성
z.ai 접속 후 이메일 또는 GitHub OAuth로 가입한다. 중국 본토 휴대폰 번호 없이 이메일만으로 글로벌 계정을 만들 수 있다.
Coding Plan 구독 선택
Lite $18 · Pro $72 · Max $160 중 워크로드에 맞게 선택한다. 분기 결제 토글 기준으로는 대략 10% 안팎의 할인이 보인다. 개인 개발자는 Pro, 팀은 Max가 일반적이다.
API 키 발급 후 Claude Code에 연결
대시보드 API Keys 메뉴에서 키 생성 후 `ANTHROPIC_AUTH_TOKEN`과 `ANTHROPIC_BASE_URL`을 넣는다. Coding Plan 쿼터는 공식 지원 툴 안에서만 소모되고, 일반 앱 API 크레딧처럼 자동 전환되지는 않는다.
결제는 Stripe 기반 카드 결제·PayPal 중심이다. 실제 승인 여부는 카드사·국가·계정 상태에 따라 달라질 수 있으니 결제 직전 화면 기준으로 확인하는 편이 안전하다.
초대 링크로 얻는 5% 첫 결제 할인
Z.AI는 공식 레퍼럴 프로그램을 운영 중이다. 현재 규칙 문서 기준으로 초대 링크를 통해 가입한 신규 사용자는 72시간 내 첫 GLM Coding 구독 결제를 완료하면 5% 즉시 할인을 받을 수 있다. 갱신·업그레이드에는 적용되지 않고, 이전에 유료 구독 이력이 없는 계정에만 해당된다. 초대한 사람 쪽 보상은 별도 구조로, 유효 초대가 누적되면 첫 주문 실결제액 기준 10% 크레딧 보상이 지급된다(출처: Z.AI Credit Campaign Rules, 2026-05-04 확인).
참고로 필자의 초대코드를 적어두면 아래와 같다. 코드 없이 일반 가입을 해도 제품 기능 자체는 동일하니, 본인 상황에 맞게 선택하면 된다.
적용 조건: 신규 가입자, 유료 구독 이력 없음, 초대 링크 또는 코드로 가입, 72시간 내 첫 구독 결제. 이 할인은 현재 규칙 문서상 다른 유사 첫 주문 할인과 중복되지 않는다.
- 구독 서비스: 현재 공식 정책상 구매 후 환불 불가
- 자동 갱신 해지: 다음 결제 전에 OFF로 바꿀 수 있고, 현재 구독 기간은 만료까지 사용 가능
- API 크레딧(별도 충전형): 환불 불가
커뮤니티 반응 — 해외와 국내가 갈린다
해외 개발자 커뮤니티에서 GLM 5.1은 가성비 끝판왕으로 빠르게 자리를 잡고 있다. 국내 반응은 아직 라이트 사용자 위주라 평가가 반반이다.
- "월 $30 GLM으로 Claude Max Code의 3배 usage를 얻는다. 일상 작업 90%는 구분이 안 갈 정도다." — Elio Verhoef (Medium)
- "Open Code에서 GLM 5.1을 붙인 뒤 Cursor 구독을 해지하기로 했다. 품질이 너무 좋다." — DeathArrow (HackerNews)
- "GLM 5.1의 UI 결과물이 GPT-5.4보다 낫고, 디자인은 Claude Opus 4.6보다 낫다는 느낌을 받는다." — BridgeMind (X)
- "테니스장 예약 시스템의 SQL Injection 취약점을 자동으로 발견해 패치 PR까지 만들어줬다." — stavros (HackerNews)
- "100–128K 컨텍스트 근방에서 완전 차분에서 완전 붕괴로 예측 가능하게 망가진다." — jauntywundrkind (HackerNews)
- "양자화 버전 문제인지 1/4–1/5 빈도로 파일 손상이나 디렉토리 삭제가 발생했다." — RickHull (HackerNews)
- "간단한 CSS 변경 요청에 50분 이상 걸리고 529 에러도 잦다. 안정성이 숙제다." — kay_o (HackerNews)
- "컨텍스트는 크지만 추론·agentic 능력은 아직 OpenAI·Google 최상위에 못 미친다." — Ashish Sharda (Medium)
해외가 먼저 움직이는 이유
Open Code · Cline · Roo Code 같은 VS Code 계열 오픈소스 에이전트 IDE 생태계가 해외에서 더 활발하다. 이들 IDE는 모두 Anthropic API 호환 엔드포인트를 설정으로 바꿀 수 있어 GLM 5.1 도입 비용이 사실상 0에 가깝다. Cursor · Claude Code만 써온 국내 환경에서는 왜 굳이 바꿔야 하나라는 관성이 더 크다.
국내 라이트 사용자 기준 — 피크 쿼터가 체감 가장 큰 변수
국내 커뮤니티에서는 오후에 쓰려고 했더니 쿼터가 금방 떨어진다는 반응이 꽤 보인다. 앞서 다룬 UTC+8 14–18시 3× 차감이 한국 15–19시에 겹치는 구조 때문이다. 오전·새벽에 집중해서 쓰는 리듬이 가능한 독립 개발자라면 Pro 한 장으로도 넉넉하다. 바이브코딩 관점에서 GLM 5.1의 자리는 Opus가 맡던 많은 루틴 작업을 더 싼 가격대로 가져오는 교체재에 가깝다. 완전한 대체제가 아니라, 반복적이고 스펙이 비교적 명확한 구간을 잘라 오는 용도라고 보는 편이 정확하다.
트러블슈팅 Q&A
Q1: 환경변수를 설정했는데 Claude Code가 여전히 Anthropic에 붙는다
Claude Code는 기존 로그인 토큰을 우선 사용한다. claude logout → claude 재실행으로 새 환경변수가 반영된다. ANTHROPIC_AUTH_TOKEN 대신 ANTHROPIC_API_KEY로 잘못 쓰는 케이스도 흔하니 변수명을 정확히 맞춘다.
Q2: 529 에러가 반복적으로 뜬다
피크 시간 과부하거나 쿼터 소진 직전 상황이다. 피크(한국 15–19시) 외 시간으로 재시도하거나, CCR에서 fallback 규칙을 걸어 529 발생 시 Claude Opus로 자동 스위치하도록 설정한다. retries: 3, backoff: exponential이 기본 조합이다.
Q3: 100K 컨텍스트를 넣었더니 답변이 이상해졌다
실전 안정 구간 80K를 넘겼을 가능성이 높다. 레포 전체를 한 번에 넣지 말고 .claudeignore 또는 CCR 룰로 청킹한다. 관련 파일만 5–10개 attach 전략이 훨씬 안정적이다.
Q4: 한국어 출력 품질은 어떤가
일상 기술 문서 작성은 GPT-4.1 이상, Claude Sonnet 4.5 수준이다. 다만 아주 긴 에세이나 격식체 혼용이 필요한 문서에서는 GLM 특유의 번역체 느낌이 남는다. 최종 퇴고는 Claude나 GPT로 돌리는 편이 낫다.
Q5: Windows에서도 쓸 수 있나
가능하다. PowerShell에서는 $env:ANTHROPIC_AUTH_TOKEN = "zai-xxx" 형식으로 지정한다. WSL2를 쓰면 리눅스 환경변수 세팅이 그대로 적용된다.
결론: 누가 지금 GLM 5.1을 써야 할까
핵심 요약
GLM 5.1은 Claude Code 워크플로의 상당 부분을 더 낮은 비용으로 옮겨오는 데 강점이 있다. 다만 Z.AI의 진짜 매력은 GLM 5.1 단독이 아니라 구독형 API + Vision MCP + GLM-Image로 이어지는 스택에 있다. 코딩 루틴·웹 에이전트·장시간 자율 실행은 오픈웨이트 최상위권이지만, 멀티모달·100K+ 장문 일관성·미세한 추론 판단은 여전히 Opus 4.7이나 Gemini 3.1 Pro가 앞선다. Opus를 완전히 버리는 선택보다, Opus 호출을 줄이는 보조제로 쓰는 쪽이 더 현실적인 포지셔닝이다.
- Claude Code Max 비용 부담 1인 개발자 — Coding Plan Pro($72)로 많은 일상 작업을 처리하고, 까다로운 구간만 Opus로 넘기고 싶은 경우
- 스크린샷 이해까지 같이 필요한 코딩 사용자 — GLM 5.1 + Vision MCP 조합이면 텍스트 코딩과 화면 이해를 한 스택에서 운영 가능
- API 파이프라인 운영 팀 — 캐시 히트 기준 입력가 $0.26/1M로 RAG·평가·배치 단가 1/10 수준
- GLM 5.1 단일 모델 하나로 텍스트·이미지·스크린샷을 모두 끝내고 싶은 프론트엔드 개발자 — Z.AI 안에서도 GLM-5V-Turbo·Vision MCP로 분리 운용해야 한다
- 대형 레포 전체를 컨텍스트에 통째로 넣던 분 — 80K 이하 청킹 여력이 필수. 아니면 Opus가 안전하다
Z.AI에 가입하고 Coding Plan Pro를 구독한다
z.ai에 이메일로 가입 후 Pro($72/mo, 분기 결제 시 약 $65/mo)를 선택한다. 개인 작업이 주 400 프롬프트 이하면 Lite($18)부터 시작해도 된다.
API 키를 발급하고 Claude Code 환경변수에 등록한다
대시보드에서 키 생성 후 `ANTHROPIC_AUTH_TOKEN`, `ANTHROPIC_BASE_URL`, `API_TIMEOUT_MS`를 넣는다. GLM-5.1을 고정하려면 `ANTHROPIC_DEFAULT_OPUS_MODEL` 같은 슬롯 매핑을 추가한다.
평소 워크플로로 3일간 돌려본다
Opus와 체감 차이를 기록한다. 특히 100K 근방 컨텍스트, 이미지 입력 의존 작업, 복잡한 추론 세 지점을 의식적으로 체크한다. 스크린샷 이해가 필요하면 Vision MCP도 함께 켜본다.
필요하면 CCR로 Haiku=4.7, Sonnet=5.1, Opus=claude-opus-4-7 라우팅을 구성한다
작업별 모델 분리로 월 API 비용을 Opus 대비 1/5 이하로 맞출 수 있다. 어려운 판단만 Opus에 오프로드한다.
피크 시간 루틴을 조정한다
한국 15-19시는 3배 차감이라 오전·새벽에 무거운 작업을 몰아두고, 피크 시간에는 문서 작성·가벼운 리팩터링만 돌린다.
- Z.AI 공식 블로그 — GLM 5.1 기술 리포트
- Z.AI Overview — Models & Agents
- Z.AI Quick Start — 일반 API 시작
- Z.AI Pricing
- Z.AI Coding Plan Overview
- Z.AI Coding Plan Quick Start
- Z.AI Coding Plan FAQ
- Z.AI Vision MCP Server
- Z.AI TRAE Guide
- GLM-5V-Turbo 공식 문서
- GLM-Image 공식 문서
- Z.AI Coding Plan 구독 페이지
- Z.AI Credit Campaign Rules (레퍼럴)
- Artificial Analysis — LLM Intelligence Index
- benchlm.ai — GLM 5.1 vs Claude Opus 4.6
- HuggingFace — zai-org/GLM-5.1
- OpenRouter — GLM-5.1
- VentureBeat — 8-hour autonomous GLM 5.1
- HackerNews GLM 5.1 토론 스레드
- Claude Opus 4.7 총정리 — 벤치마크 기준선
- Kimi K2.6 완전분석 — 중국 오픈웨이트 경쟁 비교
- Claude Code 완전 정복 — 환경변수·MCP 세팅
- Gemma 4 완전 정리 — 오픈소스 LLM 라이선스 지형
GLM 5.1은 정말로 Claude Opus 4.7보다 코딩을 잘하나?
월 $18 Lite 플랜으로 Claude Code를 대체할 수 있나?
Coding Plan 구독만으로 API를 쓸 수 있나?
Z.AI에 비전 모델과 이미지 생성 모델도 있나?
GLM 5.1을 로컬에서 돌릴 수 있나?
초대코드 없이 가입하면 불이익이 있나?
텍스트 전용이라는 게 실무에서 얼마나 불편한가?
GLM 4.6을 계속 써도 되나, 아니면 5.1로 갈아타야 하나?
국내 결제·세금계산서 발급이 가능한가?
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.
주제 태그

Kimi K2.6 완전분석 — Claude Opus 4.7을 88% 싸게 대체하는 법
SWE-Bench Pro 58.6, HLE 54.0으로 GPT-5.4·Opus 4.7을 꺾은 오픈소스 Kimi K2.6. 300 에이전트 스웜·256K 컨텍스트·API 88% 절감까지 2026년 4월 공개 스펙 총정리.
읽기
클로드 코드 토큰 절약법, 60~90% 줄이는 rtk 사용법 (2026)
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.
읽기
Claude Opus 4.8 총정리 - 벤치마크·가격·ultracode 해석 (2026)
Claude Opus 4.8의 출시일, 벤치마크, 가격, fast mode, ultracode와 dynamic workflows를 2026년 5월 기준으로 정리했다.
읽기