Claude Code 토큰 71배 줄이는 법 — Graphify 실전 구축 2026
Claude Code가 쿼리마다 grep 대신 그래프를 읽게 만드는 법. Graphify로 코드·PDF·문서를 지식 그래프로 묶어 토큰을 10분의 1로 줄이는 전 과정 실전 기록.

빠른 결론
먼저 이렇게 보면 됩니다
약 38분 읽기한 줄 판단
Claude Code가 쿼리마다 grep 대신 그래프를 읽게 만드는 법. Graphify로 코드·PDF·문서를 지식 그래프로 묶어 토큰을 10분의 1로 줄이는 전 과정 실전 기록.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- Graphify · Claude Code · 지식그래프
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
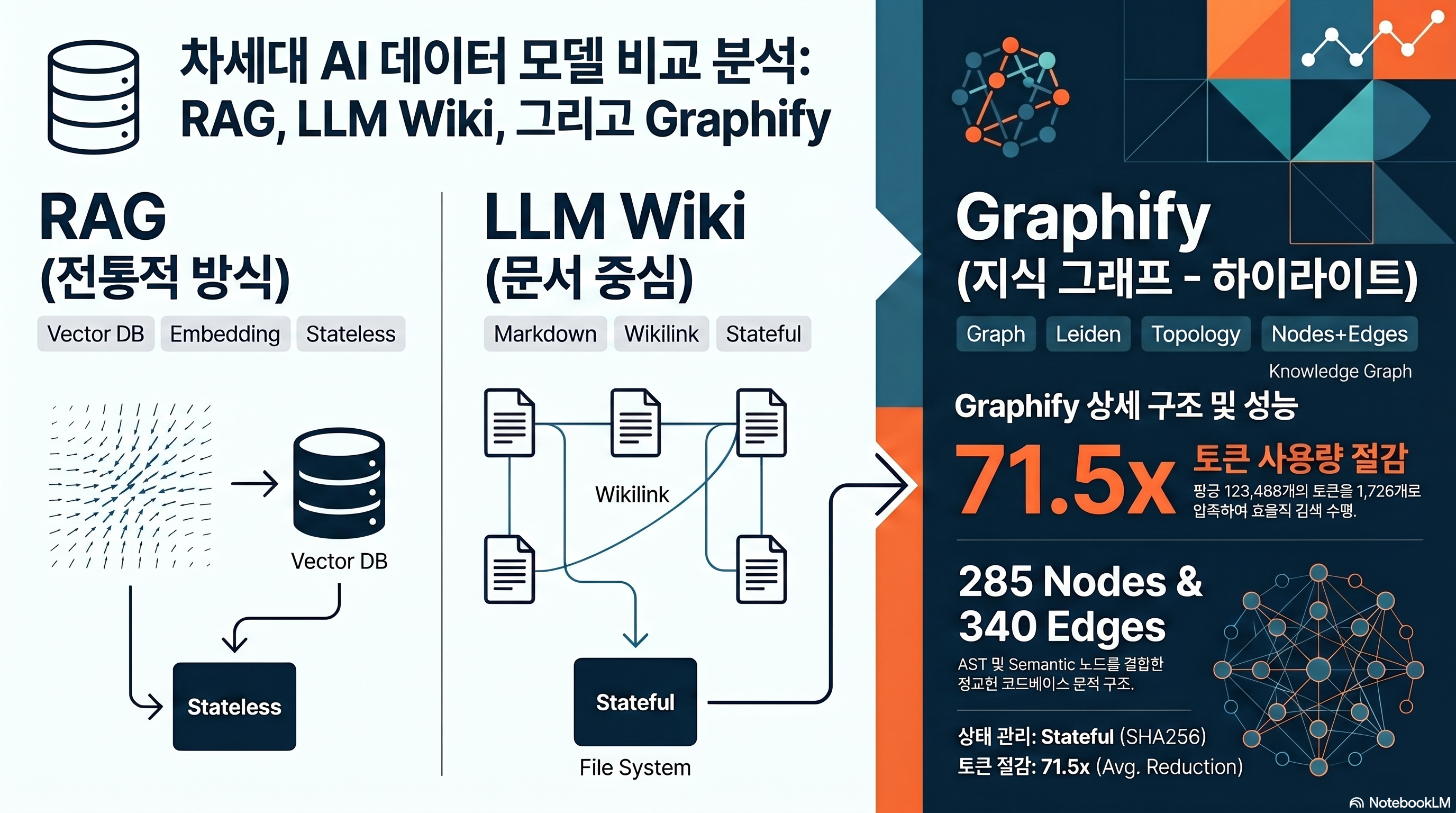
- Graphify는 코드베이스·PDF·문서를 “노드+에지 그래프”로 컴파일해 Claude Code가 쿼리마다 grep을 돌리는 대신 GRAPH_REPORT를 먼저 읽게 만든다.
- 저자 측정 기준 평균 71.5배 토큰 절감이 나오지만, 코퍼스 규모·질문 난이도에 따라 8.8배에서 126.7배까지 크게 흔들린다 (출처: Graphify worked/karpathy-repos/review.md).
- 이 글을 다 읽으면
pip install graphifyy→/graphify .→ PreToolUse 훅 연결까지 15분 안에 끝내고, 자기 레포에서 직접 재현할 수 있다.
목차
- Graphify는 RAG랑 정확히 뭐가 다를까?
- 설치에서 graphifyy라고 y를 두 개 쓰는 이유는?
- /graphify . 첫 실행에선 무엇이 생성될까?
- god node·INFERRED·Leiden 클러스터는 뭘 말하나?
- Claude Code 훅은 실제로 무엇을 주입할까?
- 한국어 HWP·PDF·뉴스는 어떻게 집어넣을까?
- 토큰 71배 절감, 내 코드에선 몇 배일까?
- Graphify vs code-review-graph vs graphiti — 지금 뭘 쓸까?
- 실전에서 가장 자주 터지는 함정 3가지는?
- 이 글을 읽고 뭐부터 시작하면 좋을까?
- 자주 묻는 질문
이 글은 Karpathy LLM 위키 시리즈의 2편 — 구축편이다. 개념과 배경(95% 절감 주장의 출처, 3계층 구조의 당위성, RAG와의 근본 차이)은 1편 — Karpathy LLM 위키 개념편에 정리해 두었다. 2편은 “그래서 어떻게 만드는가”만 다룬다. 설치 한 줄부터 첫 번째 그래프가 Claude Code 안으로 들어가는 순간까지 실제 커맨드와 실제 페이로드를 공개한다.
Graphify는 RAG랑 정확히 뭐가 다를까?
리서치하러 온 독자의 첫 번째 질문은 항상 동일하다. “이거 그냥 GraphRAG 아닌가?” 짧게 답하면 아니다. Graphify는 색인이 아니라 컴파일을 한다. 그리고 그 컴파일 결과물은 벡터가 아니라 노드+에지로 된 networkx 그래프와, Claude가 바로 읽을 수 있는 GRAPH_REPORT.md 한 장이다.
벡터 임베딩 없이, 토폴로지만으로 질문에 답한다
Microsoft GraphRAG는 문서를 청크로 쪼개고 LLM으로 엔티티·관계를 뽑아낸 뒤 커뮤니티별로 계층 요약을 생성해 parquet에 영속화한다. indexing 단계에서 LLM을 수십 번 호출해 비용이 크다. LightRAG는 커뮤니티 검출 없이 flat graph로 가고 vector + graph 이중 검색을 한다 (출처: Microsoft GraphRAG).
Graphify는 이 둘과 다른 길을 간다. 코드는 tree-sitter로 AST를 추출해 노드를 만들고, 문서는 정규식과 링크 패턴으로 semantic 노드를 만든 뒤, networkx 기반 Leiden 커뮤니티 검출로 그룹을 묶는다. LLM 호출은 ingest 단계에서 0회, 쿼리 단계에서도 기본 0회다. “그래프의 토폴로지 자체가 답을 준다”는 발상이다.
쿼리는 top-k 벡터 검색이 아니라 BFS
쿼리 시 동작을 보면 차이가 선명해진다. Graphify의 benchmark.py는 질문에서 라벨 매칭 상위 3개 노드를 고른 뒤 depth=3까지 BFS로 서브그래프를 확장한다. 그 서브그래프를 텍스트로 펼쳐 Claude에게 넘긴다 (출처: benchmark.py).
벡터 DB가 “유사한 청크 top-10”을 뽑아주는 것과 전혀 다른 동작이다. BFS는 “이 개념과 에지로 연결된 이웃”을 본다. 예를 들어 GPTConfig 노드에서 depth 3까지 가면 GPT → Block → CausalSelfAttention까지 따라간다. 의미 유사도 top-k로는 이런 구조적 이웃을 보장하지 못한다.
3계층 구조는 “폴더 설계”가 아니라 “컴파일 타겟”
1편에서 정리한 3계층 구조(raw / wiki / schema)는 Graphify에서 실제로 3개의 산출물로 찍혀 나온다. raw 원문은 worked/ 안에 들어가고, wiki 요약은 GRAPH_REPORT.md로 찍히고, schema는 graph.json과 Neo4j/GraphML export로 나온다. 폴더를 먼저 설계하는 게 아니라 컴파일러가 3층 출력을 내뱉는다는 점이 핵심이다.
설치에서 graphifyy라고 y를 두 개 쓰는 이유는?
설치는 한 줄이지만 여기서 첫 번째 함정이 나온다. PyPI 패키지 이름이 직관과 다르다.
패키지명은 graphifyy (y 두 개)
공식 README 첫 문단에 박혀 있는 경고다. “PyPI package is named graphifyy. Other packages named graphify* on PyPI are not affiliated.” 누군가 graphify라는 이름을 먼저 선점했기 때문에 저자가 y를 하나 더 붙였다 (출처: Graphify README).
이걸 모르고 pip install graphify를 치면 전혀 다른, 관리되지 않는 패키지가 설치된다. pip show로 저자명·홈페이지를 확인하는 습관이 필요하다.
# 올바른 설치
pip install graphifyy
# 옵션 extras (PDF/영상/오피스/watch 모드)
pip install "graphifyy[pdf,video,office,watch,mcp,neo4j]"Python 3.10 이상이 필요하다. 3.9 이하에선 설치부터 실패한다 (출처: pyproject.toml).
extras를 언제 붙이나
기본 설치만으론 코드 그래프 빌드는 되지만 PDF도, 영상도, Obsidian export도 안 된다. 각 extras의 실체는 다음과 같다.
| extras | 추가 의존성 | 쓰는 경우 |
|---|---|---|
| `pdf` | pypdf, html2text | 논문·백서를 코드와 함께 묶을 때 |
| `video` | faster-whisper, yt-dlp | 컨퍼런스 영상·YouTube URL ingest |
| `office` | python-docx, openpyxl | DOCX/XLSX 문서 ingest (⚠️ HWP 미지원) |
| `watch` | watchdog | 파일 변경 시 그래프 자동 재생성 |
| `mcp` | mcp | MCP 서버 모드로 Claude Code에 노출 |
| `neo4j` | neo4j | Neo4j Aura/로컬 인스턴스에 push |
| `leiden` | graspologic (Python 3.13 미지원) | Leiden 클러스터링 (미설치 시 Louvain 폴백) |
플랫폼 설치 — graphify install [--platform]
패키지 설치 다음은 AI 툴과 연결이다. Graphify는 단일 CLI로 14개 에이전트 플랫폼에 훅을 박는다.
graphify install --platform claude # Claude Code
graphify install --platform codex # Codex
graphify install --platform gemini # Gemini CLI
graphify install --platform opencode # OpenCode
graphify install --platform cursor # Cursor
# 그 외 copilot, aider, claw, droid, trae, trae-cn, hermes, kiro, vscode, antigravitygraphify install만 입력하면 현재 디렉토리에서 감지된 플랫폼 전체를 찾아 일괄 설치한다 (출처: main.py).
/graphify . 첫 실행에선 무엇이 생성될까?
설치가 끝났으면 레포 루트에서 단일 명령으로 그래프를 만든다. 여기서 나오는 산출물이 1편에서 정리한 3계층 구조의 실제 물리적 구현이다.
기본 출력: graphify-out/ 한 폴더
graphify . 또는 graphify /path/to/repo를 실행하면 작업 디렉토리에 graphify-out/이 생성된다. 기본 산출물은 다음과 같다.
graphify-out/
├── graph.json # 노드+에지 + 메타데이터 (schema 계층)
├── GRAPH_REPORT.md # LLM 소비용 요약 마크다운 (wiki 계층)
├── graph.html # pyvis 인터랙티브 시각화
├── graph.graphml # Gephi/Cytoscape import용
└── clusters.json # Leiden 커뮤니티 할당--wiki, --svg, --obsidian, --neo4j-push <url> 같은 플래그로 출력 형식을 추가할 수 있다. Obsidian Vault로 바로 떨굴 때는 graphify . --obsidian ~/Documents/MyVault 형태로 경로를 지정한다 (출처: main.py).
코드는 tree-sitter, 문서는 regex 파이프라인
22개 언어는 tree-sitter grammar로 AST를 뽑는다. 파이썬, 자바스크립트, 타입스크립트, Go, Rust, Java, C/C++, Ruby, C#, Kotlin, Scala, PHP, Swift, Lua, Zig, PowerShell, Elixir, Objective-C, Julia, Verilog까지. README는 “25 languages”를 주장하는데 실제로는 22개 tree-sitter + Vue/Svelte/Dart 3개 regex 기반 = 25가 정확한 표현이다 (출처: pyproject.toml).
문서 확장자는 v0.4.16–0.4.23에서 계속 늘어나는 중
최근 2주 사이 .mdx 인식(Issue #428), .html DOC_EXTENSIONS 편입(Issue #260), Go import ID 충돌 수정(Issue #431), 5,000개 이상 노드에서 to_html() 크래시 수정(Issue #432) 같은 PR이 연달아 머지됐다. 2026-04-16부터 04-18까지 사흘 동안만 v0.4.16에서 v0.4.23까지 8개 릴리스가 나왔다 (출처: Graphify releases).
이 속도는 양날의 검이다. 버그가 빨리 잡히지만, 3일만 업데이트를 미뤄도 “다른 버전”을 쓰게 된다. 프로덕션 도입 시점에선 버전 고정이 필수다.
god node·INFERRED·Leiden 클러스터는 뭘 말하나?
생성된 graph.html을 브라우저로 열면 구체가 잔뜩 연결된 낯선 그림을 보게 된다. 이 그림을 해석하지 못하면 Graphify를 쓸 이유의 절반이 사라진다. 용어 3개부터 익히자.
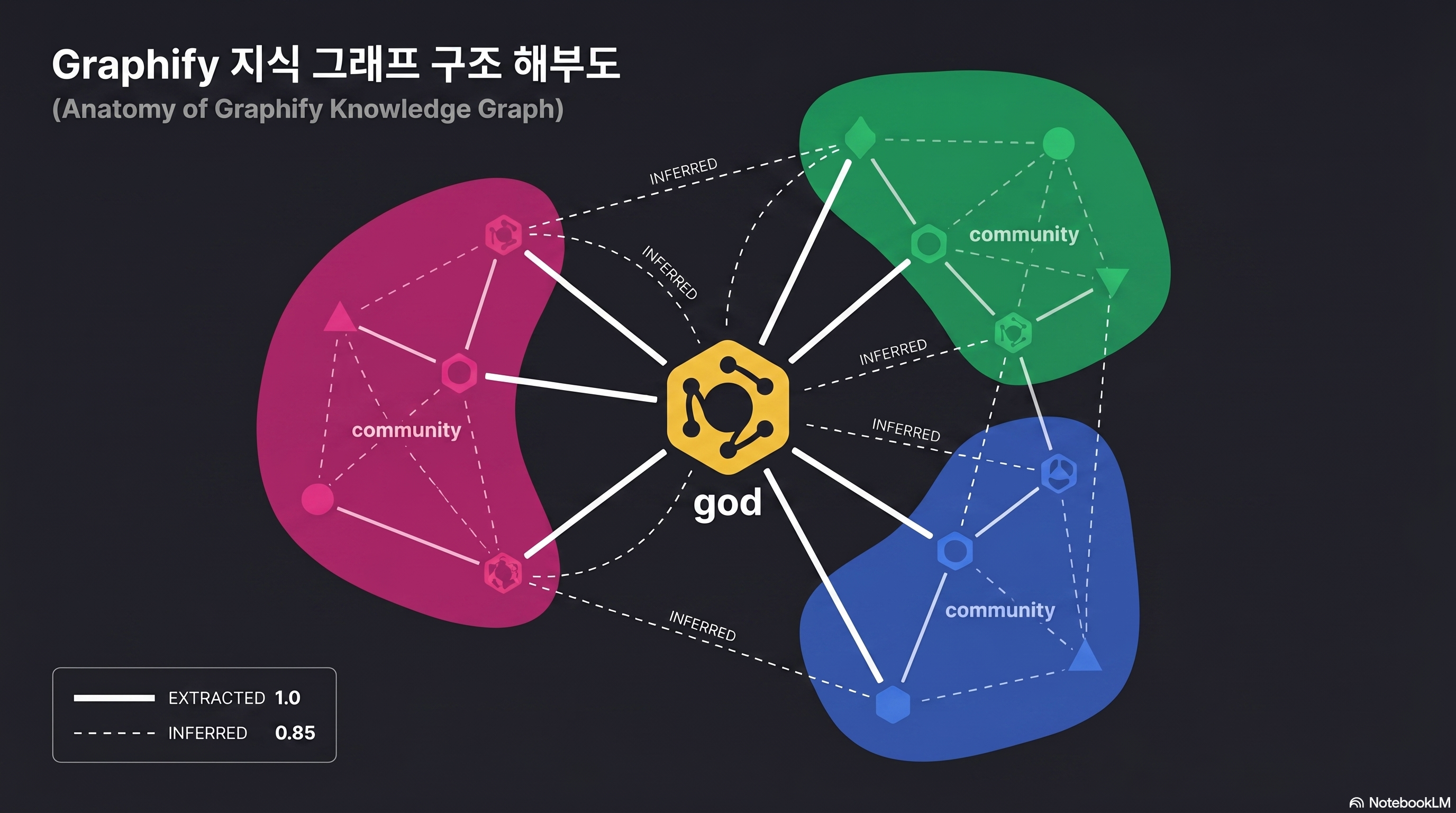
god node — 아키텍처의 중심축
analyze.py는 degree 기반 top 10 노드를 뽑되 단순 hub가 아닌 노드만 남긴다. 구체적으로 _is_file_node()로 파일명과 일치하거나 .method() 형태면 제외하고, _is_concept_node()로 확장자 없는 의미 노드는 별도 처리한다 (출처: analyze.py).
결과적으로 “모든 파일이 import하는 util.py” 같은 단순 파일 hub가 아니라 GPTConfig, Block, CausalSelfAttention처럼 아키텍처의 중심이 되는 추상 개념만 god node로 남는다. scale-free 네트워크의 hub 탐지와 표면적으로 비슷하지만 필터링 규칙이 더 엄격하다.
INFERRED 에지 — 코드에서 선언 안 된 추론 관계
정상적인 에지는 AST에서 직접 추출된다. class GPT(nn.Module):이 있으면 GPT --extends--> nn.Module 에지가 박힌다. 그런데 Graphify는 라벨 유사도, 위치 근접성, 문서 내 언급 패턴으로 INFERRED 에지를 추가한다. “같은 파일에 등장하는 두 함수”, “같은 문서 섹션에서 언급된 개념”처럼 선언되지 않은 관계를 추론한다.
이게 힘이자 위험이다. 힘은 문서와 코드를 브릿지해 Claude가 “FlashAttention 섹션은 CausalSelfAttention 구현과 연결된다”를 이해하게 만든다. 위험은 잘못된 INFERRED가 환각 소스가 될 수 있다는 점이다.
각 에지에는 신뢰도 점수가 함께 박힌다. EXTRACTED는 항상 1.0, INFERRED는 모델 확신도에 따라 0.4–0.9 (예: 교차 파일 호출 추론은 0.8 고정), AMBIGUOUS는 0.1–0.3으로 사람이 검토해야 할 후보다 (출처: validate.py). 0.3 미만 에지는 GRAPH_REPORT.md 리뷰 섹션에 자동 플래그가 붙으므로, 한 번 훑어보고 오추론을 솎아내는 루틴이 환각을 미리 차단한다.
Hyperedges — 3개 이상 노드를 한 번에 묶는 그룹 관계
일반 그래프 라이브러리는 두 노드를 잇는 pairwise 에지만 다룬다. 하지만 “공통 프로토콜을 구현하는 모든 클래스”, “auth flow에 참여하는 모든 함수”, “한 논문 섹션에서 한 개념을 함께 형성하는 노드 그룹”처럼 3개 이상 노드가 한 덩어리로 의미를 가지는 상황이 적지 않다. Graphify는 이걸 graph.json의 top-level hyperedges 배열에 별도로 저장한다 (출처: CHANGELOG v0.3.0).
god node가 “단일 허브”를 보여준다면 hyperedge는 허브 없이도 함께 움직이는 클러스터를 잡아낸다. Leiden 커뮤니티 탐지 결과와 별개 트랙으로 가는 정보라, GRAPH_REPORT.md를 읽을 때 두 정보를 교차참조하면 아키텍처 그림이 한층 단단해진다.
Leiden 커뮤니티 — 아키텍처의 자연스러운 덩어리
Leiden 알고리즘은 2019년 Traag·Waltman·van Eck이 Louvain의 “badly-connected community” 문제를 고치며 제안했다. Louvain은 최대 25% badly-connected, 최대 16% disconnected 커뮤니티를 만들 수 있는데, Leiden은 refinement phase로 연결성을 보장한다 (출처: arXiv:1810.08473).
Graphify는 graspologic(Microsoft Research + Johns Hopkins NeuroData 합작) 라이브러리의 leiden()을 try-import하고, 실패하면 networkx의 louvain_communities로 폴백한다 (출처: cluster.py).
graspologic는 python_version < '3.13' 조건이 붙은 의존성이다. Python 3.13+ 환경에선 자동으로 Louvain 폴백이 걸리므로, README의 “Leiden 보장” 설명과 실제 동작이 달라진다. 릴리스 노트에서 클러스터링 품질을 비교할 때 이 차이를 인지해야 한다.

Claude Code 훅은 실제로 무엇을 주입할까?
여기가 많은 리뷰어가 오해하는 지점이다. Graphify는 Claude Code의 응답을 가로채지 않는다. tool 호출을 차단하지도 않는다. 단 하나, GRAPH_REPORT.md를 먼저 읽으라는 1줄 reminder를 주입할 뿐이다.
PreToolUse 훅의 실제 페이로드
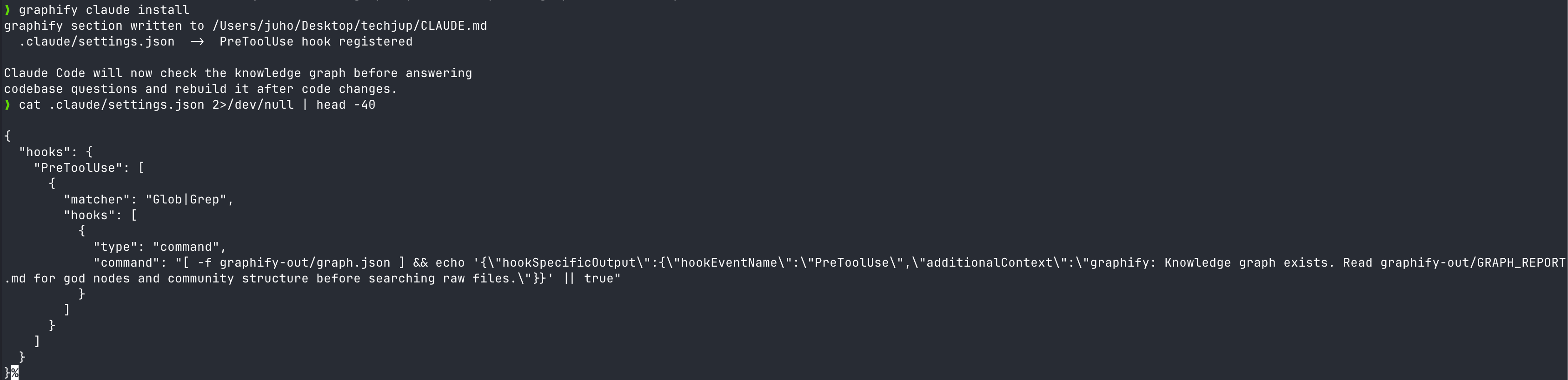
graphify claude install을 실행하면 .claude/hooks.json에 다음과 같은 훅이 등록된다 (출처: main.py).
{
"matcher": "Glob|Grep",
"hooks": [{
"type": "command",
"command": "[ -f graphify-out/graph.json ] && echo '{\"hookSpecificOutput\":{\"hookEventName\":\"PreToolUse\",\"additionalContext\":\"graphify: Knowledge graph exists. Read graphify-out/GRAPH_REPORT.md for god nodes and community structure before searching raw files.\"}}' || true"
}]
}이게 전부다. Glob 또는 Grep tool이 호출되기 직전 additionalContext 필드로 10,000자 한도 안에서 한 문장을 끼워 넣는다 (출처: Claude Code hooks 공식 문서). additionalContext는 Claude Code v2.1.9 이상에서 지원된다.
”grep 돌지 말고 그래프부터 봐라”라는 nudge
메시지 본문을 보면 명령이 아니라 권유 형태다. “Knowledge graph exists. Read … before searching raw files.” Claude는 이 힌트를 읽고 Read graphify-out/GRAPH_REPORT.md를 먼저 호출하게 된다. 그래프에서 답이 나오면 원본 grep을 생략하고, 안 나오면 원본을 찾아가는 2단 구조다.
Claude Code의 CLAUDE.md 시스템과 합쳐지면 더 강력해진다. CLAUDE.md 상단에 “먼저 GRAPH_REPORT를 본다”를 박아 두면 hook과 이중 방어가 된다.
# CLAUDE.md 상단에 추가
## 검색 우선순위
1. graphify-out/GRAPH_REPORT.md — 아키텍처 개요와 god node
2. graphify-out/graph.json — 특정 노드의 이웃 관계
3. Grep / Glob — 위에서 못 찾은 경우에만플랫폼별 훅 등가물
Claude가 아닌 다른 에이전트에도 동일한 로직이 이식되어 있다.
| 플랫폼 | 훅 파일 | matcher | 메커니즘 |
|---|---|---|---|
| Claude Code | .claude/hooks.json | Glob|Grep | PreToolUse + additionalContext |
| Codex | .codex/hooks.json | tool_use | Bash 커맨드 (JSON stdout) |
| Gemini CLI | settings.json | read_file|list_directory | BeforeTool hook |
| OpenCode | opencode.config | tool.execute.before | JS 플러그인 |
민감한 문서가 많은 내부 코드베이스라면 훅 주입 전에 Gemma 4 로컬 설치 가이드를 참고해 로컬 LLM + Graphify 하이브리드로 가는 경로도 고려할 수 있다.
한국어 HWP·PDF·뉴스는 어떻게 집어넣을까?
영어권 가이드는 대개 nanoGPT 같은 GitHub 레포로 끝난다. 한국어 환경은 HWP와 PDF, 그리고 국내 뉴스 사이트 크롤링이 훨씬 많다. 여기서 가장 현실적인 파이프라인을 짠다.
HWP는 Graphify가 읽지 못한다 — 사전 변환 필수
Graphify의 DOC_EXTENSIONS 리스트에 .hwp나 .hwpx는 없다. office extras를 설치해도 마찬가지다. pyhwp·python-docx가 타겟이기 때문이다 (출처: pyproject.toml).
해결은 사전 변환이다. 선택지 3가지를 비교하면 다음과 같다.
| 도구 | 변환 포맷 | 한국어 품질 | 자동화 |
|---|---|---|---|
| kordoc (chrisryugj/kordoc) | HWP/HWPX → Markdown | 표/목차 보존 우수 | CLI + MCP 서버 |
| pyhwp + olefile | HWP → TXT | 서식 손실, 본문만 | Python 스크립트 |
| 한글2020 COM (Windows only) | HWP → DOCX → Graphify | 서식 완전 보존 | pywin32 필요 |
| RHWP 크롬 확장 | HWP 웹 프리뷰 | 읽기용, 변환 X | 사람이 복사 |
개인 문서 수준이라면 RHWP 크롬 확장으로 열어보고 핵심만 Markdown으로 옮기는 게 빠르다. 문서 수십 개 이상 배치로 변환할 땐 kordoc가 가장 안전하다.
PDF는 pypdf + html2text 조합이 자동으로 들어간다
pip install "graphifyy[pdf]"만 해두면 pypdf와 html2text가 의존성으로 들어온다. 이후 graphify . 실행 시 .pdf 파일을 자동 인식해 텍스트를 뽑아 semantic 노드로 박는다. 단, 스캔 PDF(이미지 기반)는 OCR이 안 돼 무시된다.
한국어 라벨 자체는 이제 안전하다. v0.4.x 초기엔 Windows에서 한글·이모지가 들어간 노드 라벨이 UnicodeEncodeError로 크래시했지만, v0.4.2에서 모든 파일 IO에 encoding="utf-8"이 강제되고 v0.4.10에선 Unicode NFKD 정규화를 거친 norm_label 필드까지 도입돼 한글 식별자·검색 매칭이 깨지지 않는다 (출처: CHANGELOG v0.4.2/v0.4.10).
FlashAttention·GPT-1 같은 논문을 nanoGPT와 함께 넣으면 코드의 CausalSelfAttention과 논문의 “multi-head attention” 섹션이 INFERRED 에지로 브릿지된다. 저자 실험에선 이 브릿지 덕분에 “FlashAttention을 어디에 적용해야 하는가” 질문이 100.8배 토큰 절감을 기록했다 (출처: review.md).
뉴스·블로그·YouTube — graphify add <url>
URL 단위 ingest도 지원한다.
graphify add https://example.com/article
graphify add https://youtube.com/watch?v=xxx # video extras 필요YouTube는 yt-dlp로 자막/오디오를 가져와 faster-whisper로 transcribe한다. 기본 --whisper-model medium을 쓰는데, 이 크기에선 한국어 CER(글자 오류율)이 11.13%로 영어 3.91%에 비해 3배 가까이 높다 (출처: Whisper KsponSpeech 벤치마크 비교).
기술 용어 많은 한국어 컨퍼런스 영상은 --whisper-model large-v3로 올리거나, 더 가볍고 한국어 CER이 낮은 ENERZAi EZWhisper(13MB)를 별도로 돌려 자막을 만든 뒤 graphify add <txt_path>로 넣는 편이 안전하다.
토큰 71배 절감, 내 코드에선 몇 배일까?
“71.5배”라는 수치는 눈길을 끌지만 그 자체론 복제가 안 된다. 측정 조건과 재현 방법을 정확히 공개해야 믿을 수 있다.
원출처: worked/karpathy-repos/review.md
측정은 Graphify 레포 내부 worked/karpathy-repos/review.md에 기록돼 있다 (출처: review.md).
| 측정 항목 | 값 |
|---|---|
| Corpus | nanoGPT + minGPT + micrograd + 5 PDF + 4 이미지 = 52 파일 |
| 총 단어 | 약 92,616단어 |
| Naive tokens | 약 123,488토큰 |
| 그래프 규모 | 285 노드(163 AST + 112 semantic), 340 에지, 53 커뮤니티 |
| 평균 subgraph token | 1,726 tokens/query |
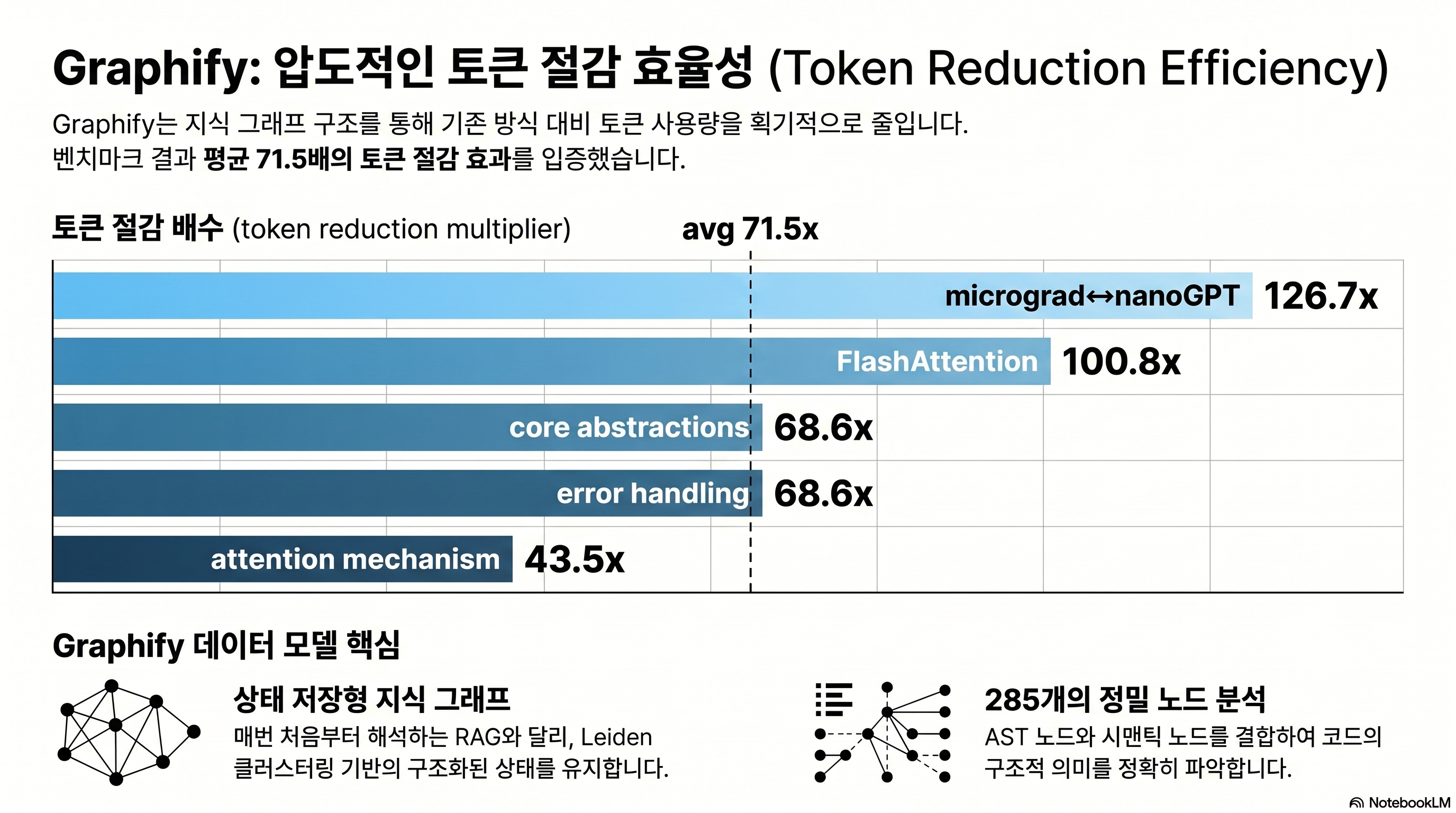
| 결과 | 평균 71.5배 (123,488 ÷ 1,726) |
코퍼스 크기에 따라 5.4배에서 71.5배로 흔들린다
같은 측정을 코퍼스 크기를 달리해 돌리면 71.5배는 천장에 가깝다. 저자가 함께 공개한 다른 worked 예시 두 개를 비교하면 차이가 분명하다.
| 코퍼스 | 파일 수 | 절감 배율 | 재현 폴더 |
|---|---|---|---|
| Karpathy 3 레포 + 5 논문 + 4 이미지 | 52 | 71.5× | worked/karpathy-repos/ |
| Graphify source + Transformer paper | 4 | 5.4× | worked/mixed-corpus/ |
| httpx (synthetic Python lib) | 6 | ~1× | worked/httpx/ |
저자 본인도 README에 “토큰 절감은 코퍼스 크기에 비례한다. 6개 파일은 어차피 컨텍스트에 다 들어가니 그래프의 가치는 토큰 압축이 아니라 구조적 명료성에 있다”고 명시했다 (출처: README.md). 따라서 자기 레포 규모를 먼저 가늠하고 기대치를 조정하는 게 첫 단계다. 50파일 미만이면 Graphify의 가치는 “토큰 절감”이 아니라 “god node·커뮤니티로 본 구조 이해”로 무게중심을 옮긴다.
질문별 편차: 43.5배에서 126.7배까지
단일 평균이 아니라 질문 난이도에 따라 5개 벤치마크 각각의 결과가 다르다.
| 질문 | 토큰 절감 배율 |
|---|---|
| micrograd ↔ nanoGPT 비교 설명 | 126.7× |
| FlashAttention 적용 지점 | 100.8× |
| core abstractions 나열 | 68.6× |
| error handling 흐름 | 68.6× |
| attention mechanism 개요 | 43.5× |
비교 질문이 가장 큰 절감을 낸다. 왜냐면 비교는 여러 코드베이스를 동시에 훑어야 해 naive 방식에서 가장 비싸기 때문이다. 반대로 “attention mechanism 개요”는 한 섹션에 답이 모여 있어 naive도 상대적으로 적게 쓰는 편이다.
재현 방법 3단계
# 1) 저자와 동일한 코퍼스 준비
git clone https://github.com/karpathy/nanoGPT
git clone https://github.com/karpathy/minGPT
git clone https://github.com/karpathy/micrograd
# 2) 그래프 빌드
graphify . --pdf
# 3) benchmark.py로 측정
python -m graphify.benchmark --queries queries.json --depth 3재현 평가: 3가지 caveat
장점
- + 측정 코드가 레포에 공개되어 있어 동일 corpus로 바로 재현 가능
- + 질문별 편차까지 세밀하게 보고되어 평균값의 맥락을 파악할 수 있음
- + 코드만 쓸 때(29 파일) 8.8배로 떨어지는 하한도 함께 공개
단점
- − 토큰 추정이 단순 len(text)//4 — tiktoken/Anthropic 토크나이저로 재측정 시 수치 변동 가능
- − Naive baseline이 word_count*100//75 공식화된 추정치 — 실제 Claude 프롬프트 토큰과 오차
- − BFS depth=3 고정 — depth·쿼리 다양성에 따라 결과가 크게 변동
실효 비용은 Sonnet/Opus 분업으로 더 줄어든다
71배 절감을 그대로 달러로 환산하려면 Claude Opus 4.7의 토큰 1.35배 이슈도 함께 봐야 한다. Opus 4.7은 동일 질문 처리에 Sonnet 4.5 대비 평균 1.35배 토큰을 더 쓰는데, Graphify로 컨텍스트를 미리 좁혀 두면 이 배율이 그대로 금액 차이로 돌아온다.
실무에선 Sonnet으로 GRAPH_REPORT를 먼저 요약하게 한 뒤, Opus에는 필요한 서브그래프만 넣어주는 2단 파이프라인이 비용-품질 최적점에 가깝다.
Graphify vs code-review-graph vs graphiti — 지금 뭘 쓸까?
Graphify만 있는 게 아니다. 2026년 기준으로 “코드베이스를 LLM용 그래프로 바꾸자”는 도구가 최소 4종 이상 경쟁한다. 정보 설계 목적에 따라 고르는 기준이 달라진다.
4개 도구 포지셔닝
| 도구 | 메인 타겟 | 클러스터링 | LLM 호출 (ingest) | 특징 |
|---|---|---|---|---|
| Graphify v0.4.23 | 코드+문서 혼합 | Leiden (3.13부터 Louvain 폴백) | 0회 | Claude Code 훅 원스톱, 14개 에이전트 지원 |
| Microsoft GraphRAG | 긴 문서/RAG 전용 | Leiden + 계층 요약 | 수십~수백 회 | 계층별 LLM 요약 미리 저장, indexing 비용 큼 |
| LightRAG | 범용 RAG 대안 | 없음 (flat graph) | 엔티티 추출용 | vector + graph 이중 검색, 저비용 |
| nano-graphrag | 학습/실험용 | 있음 | top-k 커뮤니티만 | 1,100 LoC 경량, Faiss/Neo4j/Ollama 조립 |
Microsoft GraphRAG는 긴 문서 요약·검색이 본업인 팀에 맞다. Graphify는 “내 코드베이스를 Claude가 빨리 이해하게 해줘”에 특화되어 있다. 두 도구의 목표가 다르다 (출처: Microsoft GraphRAG).
llm-wiki-mcp — 그래프가 아닌 마크다운 Wiki 대안
Lucas Astorian의 lucasastorian/llmwiki는 방향이 다르다. Postgres + Supabase + S3 + 임베딩 + 키워드 하이브리드로 쓰고, MCP 툴로 guide/search/read/write/delete를 노출한다. Claude가 직접 wiki를 편집하며 자기 기억을 축적하는 구조다 (출처: llmwiki).
그래프 없이 “에이전트가 노트를 쓰며 성장”하는 접근이 필요하면 llm-wiki-mcp, “이미 있는 코드를 빨리 이해”가 목적이면 Graphify다.
의사결정 플로우차트
- “Claude Code가 우리 레포를 빨리 읽게 해달라” → Graphify
- “수백 페이지 연구 문서를 Q&A하고 싶다” → Microsoft GraphRAG
- “오픈소스·비용 최소, 품질 70%면 충분” → LightRAG
- “에이전트가 스스로 위키를 쓰며 학습” → llm-wiki-mcp
- “직접 1,100줄 뜯어보며 배우고 싶다” → nano-graphrag
실전에서 가장 자주 터지는 함정 3가지는?
2주간 v0.4.16부터 v0.4.23 릴리스에서 잡힌 버그 외에도, GitHub 이슈 트래커와 커뮤니티 리뷰에서 반복되는 함정 3가지가 있다.
함정 1. AST와 semantic 레이어가 서로 안 만난다 (Issue #198)
가장 날카로운 학술적 비판이다. AST 노드는 SentenceTransformer(코드 정체명)로 만들어지고, semantic 노드는 문서에서 “sentence transformer”(공백 포함)로 추출되면 ID가 달라 exact match가 안 된다. 결과적으로 코드와 문서 사이 브릿지가 기대만큼 생기지 않는다는 지적이다 (출처: Issue #198).
저자는 v5 설계 문서(2026-04-16 커밋)에서 canonical labels, post-merge entity resolution, explicit code-to-concept linking으로 대응하겠다고 적어뒀다. 지금 v0.4.23을 쓰면 이 갭을 감안하고 GRAPH_REPORT.md를 한 번 눈으로 훑어 누락된 연결을 수동으로 CLAUDE.md에 보강하는 편이 안전하다.
함정 2. Python 3.13 + Leiden 기대 = Louvain 현실
앞서 언급한 graspologic 의존성 문제가 가장 자주 보고된다. Python 3.13으로 신규 세팅하면 graphifyy[leiden]을 설치해도 조용히 실패하고 Louvain으로 폴백된다. 에러 메시지 없이 동작해서 “왜 커뮤니티가 저자 리뷰와 다르지”라는 혼란을 낳는다.
# 3.13 쓰면서 Leiden 원한다면 3.12 별도 venv 권장
pyenv install 3.12.7
pyenv virtualenv 3.12.7 graphify-312
pyenv activate graphify-312
pip install "graphifyy[leiden]"함정 3. Windows PowerShell 5.1 버퍼 깨짐
Issue #19에 기록된 오래된 버그다. PowerShell 5.1은 ANSI 이스케이프 코드를 해석 못 해 graphify 진행 로그가 터미널 버퍼를 깨뜨린다. Graphify는 _suppress_output 회피 코드를 내장해 최신 버전에선 완화됐지만, PowerShell 7+로 올리는 게 근본 해결이다 (출처: cluster.py).
WSL2 우분투에서 돌리는 쪽이 가장 안전하다. macOS/리눅스 사용자는 이 문제를 만날 일이 없다.
- "Claude Code가 탐색 도중 길을 잃는 횟수가 체감상 반으로 줄었다. 특히 여러 레포를 오가는 비교 작업에서 확실히 차이가 난다." — Kevin Kinnett 리뷰
- "/compact가 매번 토큰을 잡아먹는 게 답답해서 Ollama로 로컬 압축 데몬을 만들어 Graphify에 0달러로 데이터를 쏘게 했다 — 이제 토큰 비용이 거의 없다." — r/ClaudeAI · Agreeable_Ad_1731
- "Full-Stack 멀티모달 프로젝트(React + PDF + 이미지)엔 Graphify가 압도적이다. 단, 순수 Python/ML 백엔드 blast radius 추적엔 code-review-graph가 더 낫다 — 둘을 분리해 쓰는 게 정답." — r/ClaudeAI · ganesh_agrahari
- "한국어 기술 문서 152만 단어를 넣고 돌렸는데, god node로 뽑힌 개념 목록만 봐도 정리가 된다." — Gpters 커뮤니티 후기
- "그래프 빌드까지는 잘 한다. 문제는 시간이 지나면서 중복 노드·끊어진 관계·낡은 가정이 누적되는 'knowledge drift'다. 자동 lint와 주기적 health check 없이는 결국 무너진다." — r/ClaudeAI · FragmentsKeeper
- "AST 노드와 semantic 노드의 ID가 정확히 일치해야 연결되는데, `SentenceTransformer`(코드)와 `sentence transformer`(문서)가 서로 매칭이 안 돼 코드↔문서 브릿지가 기대만큼 안 생긴다." — GitHub Issue #198
- "50개 이상 혼합 파일이 아니면 토큰 절감 체감이 거의 없다. 중소형 코드베이스는 Claude 기본 grep으로 충분하다는 인상." — Kevin Kinnett 리뷰 + r/ClaudeAI ganesh_agrahari
이 글을 읽고 뭐부터 시작하면 좋을까?
핵심 요약
Graphify는 Claude Code 앞에 “컴파일된 코드 지도”를 끼워 넣는 도구다. 설치는 pip install graphifyy 한 줄이지만, 실질적 가치는 graphify install --platform claude로 PreToolUse 훅이 박히는 순간 나온다. 71.5배 토큰 절감은 특정 코퍼스(Karpathy 52 파일) 기준 평균값이며, 작은 레포에선 8.8배까지 떨어진다는 하한도 함께 기억해야 한다. 핵심 행동은 “내 레포에서 직접 측정해보는 것” 하나다.
- 대형 모노레포를 가진 팀: 50+ 파일, 문서·코드 혼합. grep 기반 탐색이 한계에 도달한 시점에 효용 극대화.
- Karpathy 스타일 LLM 위키 실험 중인 개인: 1편 개념편을 읽고 “그래서 어떻게”에 막혔던 독자.
- Sonnet + Opus 분업으로 비용 최적화 중인 엔지니어: Graphify가 좁혀 준 서브그래프에 Opus를 쓰면 1.35배 페널티를 상쇄한다.
- 한국어 HWP/PDF 기반 사내 문서를 AI로 만들고 싶은 개발자: kordoc 또는 RHWP 크롬 확장으로 전처리 파이프라인을 먼저 짜는 시나리오.
Python 3.12 가상환경 준비
3.13은 Leiden 폴백 문제가 있으므로 pyenv로 3.12.7을 별도 venv에 깐다.
pip install graphifyy 실행
오타 주의. y가 두 개다. PDF/영상 다룰 예정이면 extras도 함께.
작은 레포에서 graphify . 첫 실행
본 코드 아닌 샌드박스 레포로 시작. graphify-out 산출물 구조를 눈에 익히기.
graphify install --platform claude로 훅 연결
실제 Claude Code에서 Glob/Grep 직전 additionalContext가 들어가는지 확인.
benchmark.py로 내 레포 토큰 절감 직접 측정
저자 71.5배가 아닌 내 코드베이스 실제 배율을 숫자로 뽑아본다.
CLAUDE.md에 검색 우선순위 추가
훅과 이중 방어. 1순위 GRAPH_REPORT, 2순위 graph.json, 3순위 Grep.
- Graphify v4 공식 README
- ARCHITECTURE.md — 설계 배경과 3계층 컴파일
- worked/karpathy-repos/review.md — 71.5배 측정 원문
- Issue #198 — AST-semantic 분리 비판
- Claude Code hooks 공식 문서
- Traag et al. 2019 — From Louvain to Leiden
- Microsoft GraphRAG
- llm-wiki-mcp (lucasastorian/llmwiki)
- kordoc — HWP/HWPX Markdown 변환기
- Kevin Kinnett Graphify 리뷰
- PyTorch Korea Graphify 디스커션
다음 편 예고 — 6개월 운영편
이 글은 설치와 첫 빌드까지다. 실제로 6개월간 운영하면 40만 단어 임계치, 환각 오염, 린트 누락, 모노레포 partial rebuild 같은 새 문제가 튀어나온다. 3편에선 Graphify를 CI에 박고 weekly rebuild 파이프라인을 짜는 방법과, GRAPH_REPORT drift 방지 전략을 다룰 예정이다. 1편 개념편과 이 글을 함께 묶어 읽으면 Karpathy LLM 위키를 실제 코드로 구현하는 데 필요한 기반이 완성된다.
자주 묻는 질문
graphify와 graphifyy 중 어느 쪽을 설치해야 하나요?
Python 3.13을 쓰는데 Leiden 클러스터링이 안 되는 것 같습니다.
71.5배 토큰 절감이 제 레포에서도 나올까요?
한국어 HWP 문서를 그래프에 넣으려면 어떻게 하나요?
PreToolUse 훅이 실제로 Claude의 도구 호출을 막을 수 있나요?
Microsoft GraphRAG와 Graphify 중 어느 쪽을 써야 하나요?
사내 민감 코드를 Graphify로 처리해도 되나요?
25개 언어를 지원한다는데 실제로는 몇 개인가요?

카파시가 경고한 AI 코딩의 악습 4가지, 10만 스타 CLAUDE.md의 정체
카파시가 짚은 AI 코딩 악습 4가지를 중심으로, 10만 스타 CLAUDE.md repo의 4원칙과 실제 효과, 한계를 해부했다.
읽기
GLM 5.1 후기 2026: Claude Code 비용 1/5로 줄이는 법
GLM 5.1을 Claude Code에 붙여 Opus 대비 1/5 비용으로 쓰는 법부터, Z.AI 구독형 API·Vision MCP·GLM-Image 라인업까지 공식 문서 기준으로 정리.
읽기
클로드 코드 완전 정복: 설치, 가격, 활용법 총정리 (2026)
AI 코딩 도구 클로드 코드를 처음 접하는 사람을 위한 솔직한 리뷰. 설치법, 요금제, Cursor 비교, 장단점까지 한 글에 담았다.
읽기