Claude Opus 4.7 Review: Benchmarks, Pricing, GPT-5 Comparison
Claude Opus 4.7 benchmarks, pricing, GPT-5.4 and Gemini 3.1 Pro comparison, xhigh mode, and the real 1.35x tokenizer cost issue explained.

Quick take
Start with this judgment
19 min readBottom line
Claude Opus 4.7 benchmarks, pricing, GPT-5.4 and Gemini 3.1 Pro comparison, xhigh mode, and the real 1.35x tokenizer cost issue explained.
- Best for
- Readers comparing cost, capability, and real limits before choosing a tool
- What to check
- Claude · Claude Opus 4.7 · Anthropic
- Watch out
- Pricing and features can change, so confirm with the official source too.
3 key points
- Claude Opus 4.7 is Anthropic’s top model released on April 16, 2026. It posts SWE-bench Pro 64.3% and OSWorld 78%, putting it at the front of autonomous coding-agent benchmarks.
- The public price is still $5 input and $25 output per 1M tokens, but the new tokenizer can split the same text into up to 1.35x more tokens. A $300 monthly bill can become roughly $405.
- Teams focused on coding and agent workflows should test Opus 4.7 with xhigh mode and Task Budgets. Teams focused on web research or creative writing should compare GPT-5.4 and Gemini 3.1 Pro first.
목차
- What exactly changed from Claude Opus 4.6 to 4.7?
- How strong is Opus 4.7 in benchmarks?
- Why can the bill rise 1.35x if the listed price did not change?
- Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro - which one should you use?
- How should you use xhigh mode and Task Budgets?
- What do 3.75MP vision and filesystem memory change?
- Where did Opus 4.7 regress?
- What is the community saying?
- Who should use Claude Opus 4.7?
- Conclusion
What exactly changed from Claude Opus 4.6 to 4.7?
Anthropic released Opus 4.7 roughly five months after Opus 4.6. The version number looks like a minor 0.1 update, but the benchmark profile and API changes make it feel closer to a generation shift for coding agents. The tradeoff is that long-context retrieval and creative-writing quality have visible regressions. This post puts the release notes, benchmarks, pricing, competing models, and limitations into one practical decision guide.
Official release on April 16, 2026
Anthropic announced Opus 4.7 on Thursday, April 16, 2026 (source: Anthropic News). Claude.ai and the API opened the same day, with AWS Bedrock, Vertex AI, Microsoft Foundry, and Snowflake Cortex following within about 48 hours (source: Help Net Security). The internal code name is widely reported as Neptune v2, and the visible improvements seem driven more by post-training than raw training-token scale. The model keeps an ASL-3 safety posture with additional mitigations for bio, chemical, and cyber risks.
GitHub Copilot also enabled Opus 4.7 for Pro+, Business, and Enterprise users at launch. That means Cursor, Windsurf, Zed, and other third-party editors can usually adopt it through a model dropdown. Pairing this with the workflow covered in Claude Code Review gives teams a cleaner adoption path.
Model IDs and supported platforms
The official API model ID is claude-opus-4-7 (source: Claude Platform Docs). Vertex AI uses claude-opus-4-7@20260416, while Bedrock uses anthropic.claude-opus-4-7-20260416-v1:0. The knowledge cutoff is listed as late January 2026, and the default max_tokens is 8192.
The most important API change: temperature, top_p, and top_k now behave as read-only defaults. If you send non-default values, the API can return a 400 error. Old Opus 4.6 wrappers need a quick cleanup before production rollout.
One-sentence summary
Opus 4.7 is stronger for coding agents, computer use, and MCP tool calling. The list price stayed flat, but the tokenizer change raises real cost. Long-context retrieval and creative use cases need extra caution.
| Item | Opus 4.7 | Opus 4.6 |
|---|---|---|
| Release date | 2026-04-16 | 2025-11-24 |
| Model ID | claude-opus-4-7 | claude-opus-4-6 |
| Input context | 1,000,000 tokens | 1,000,000 tokens |
| Max output | 128,000 tokens | 64,000 tokens |
| Knowledge cutoff | January 2026 | July 2025 |
| Effort levels | low / medium / high / xhigh / max | low / medium / high / max |
| Extended thinking | Adaptive only, off by default | budget parameter available |
| Vision resolution | 2576 x 2576px / 3.75MP | 1568 x 1568px / 1.15MP |
| Platforms | Claude.ai / API / Bedrock / Vertex / MS Foundry / Snowflake / Copilot | Claude.ai / API / Bedrock / Vertex |
| Safety rating | ASL-3 reinforced | ASL-3 |

How strong is Opus 4.7 in benchmarks?
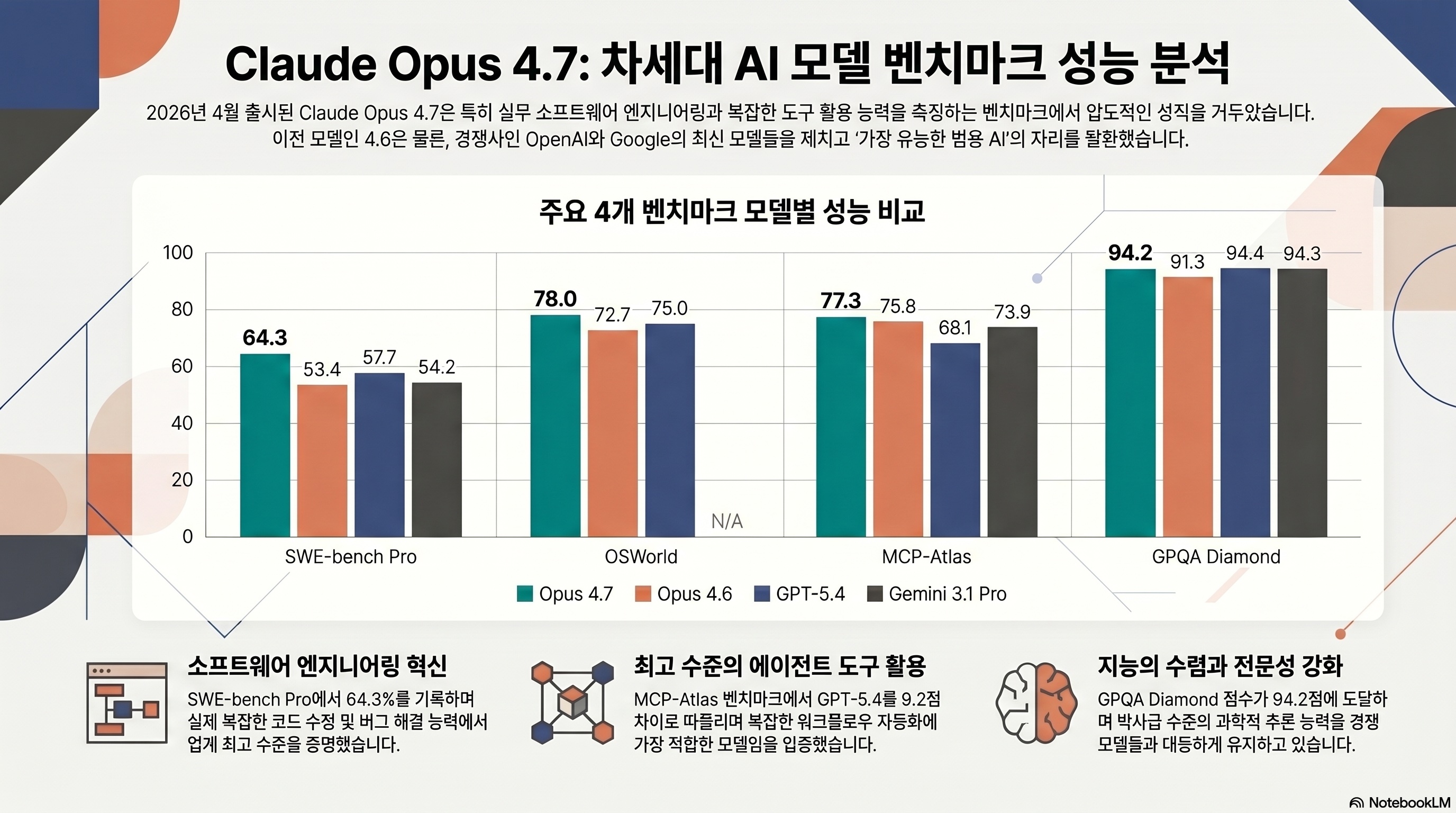
The headline number is SWE-bench Pro 64.3%. In the same benchmark, GPT-5.4 is reported at 57.7% and Gemini 3.1 Pro at 54.2%, putting Opus 4.7 6-10 points ahead of the strongest frontier alternatives for this specific software-engineering task (source: Vellum AI).
SWE-bench Verified 87.6%, Pro 64.3%
On SWE-bench Verified, Opus 4.7 reaches 87.6%, up from 80.8% for 4.6 (source: The Next Web). SWE-bench Pro matters more for real-world signal because it uses paid repositories and is considered less contaminated than the public Verified split. Opus 4.7’s 64.3% Pro score is the public high-water mark at the time of writing (source: Anthropic).
Anthropic also reports CursorBench at 70%, up from 58% on 4.6. Rakuten’s internal test says the model ran autonomously for more than 24 hours, split a task into 23 parts, and wrote unit tests. Replit reported a 12-point improvement in code-generation accuracy after switching its agent stack to Opus 4.7.
OSWorld 78% and tool-calling gains
OSWorld-Verified measures whether an agent can complete tasks in a real OS with mouse and keyboard actions. Opus 4.7 scores 78.0%, above Opus 4.6 at 72.7% and GPT-5.4 at 75.0% (source: The Next Web). This is meaningful because computer-use agents must read screenshots, choose click targets, and maintain state across long sessions.
MCP-Atlas is also strong at 77.3%, about 9 points above GPT-5.4’s 68.1%. If your agent relies on many Model Context Protocol tools, Opus 4.7 becomes the default model to test first.
Benchmark table
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% | n/a | 80.6% |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Terminal-Bench 2.0 | 69.4% | 65.4% | 75.1% | 68.5% |
| OSWorld-Verified | 78.0% | 72.7% | 75.0% | n/a |
| MCP-Atlas | 77.3% | 75.8% | 68.1% | 73.9% |
| GPQA Diamond | 94.2% | 91.3% | 94.4% | 94.3% |
| BrowseComp | 79.3% | 84.0% | 89.3% | n/a |
| CharXiv Reasoning (tools) | 91.0% | 77.4% | n/a | n/a |
| OfficeQA Pro | 80.6% | 57.1% | n/a | n/a |
| MRCR regression | 32.2% | 78.3% | n/a | n/a |
| AA Intelligence Index | 57 (1st / 133) | 55 | 56 | 54 |
Artificial Analysis ranks Opus 4.7 at 57 on its aggregate index, first among 133 evaluated models (source: Artificial Analysis). Still, aggregate scores can hide sharp domain differences. The MRCR regression below is the reason I would not route every workload to 4.7 automatically.
Why can the bill rise 1.35x if the listed price did not change?
Within a day of launch, developers started calling Opus 4.7 a hidden price increase. The price table did not move. The tokenizer did.
Listed price is the same as Opus 4.6
The official API price is $5 input and $25 output per 1M tokens, identical to Opus 4.6 (source: Anthropic News). Prompt cache write is $6.25 for 5 minutes, $10 for 1 hour, cache read is $0.50, and Batch API still gets a 50% discount. On the surface, this looks like price parity.
The new tokenizer can increase token count
Opus 4.7 uses a new tokenizer. Finout’s analysis says the same English text can become 1.0-1.15x tokens, while Korean, Japanese, and code-heavy mixed inputs can land around 1.25-1.35x (source: Finout). Anthropic frames this as more accurate segmentation, but billing is token-based, so the same prompt can cost more.
If you take an Opus 4.6 prompt and only swap the model ID to 4.7, input and output token counts can rise by 10-35%. A team spending $300/month can move into the $330-$405 range. Measure 500-1,000 real production samples before switching every route.
Practical cost scenarios
Assume 80% input tokens and 20% output tokens.
- Scenario A: $300/month, mostly English, 1.12x token expansion -> about $336
- Scenario B: $300/month, Korean plus code, 1.28x token expansion -> about $384
- Scenario C: $300/month, long context plus CJK text, 1.35x token expansion -> about $405
Finout reports that one large customer saw a 28% bill increase during the first week of rollout. The practical mitigations are aggressive prompt caching and Batch API for non-interactive workloads.
| Item | Opus 4.7 | Opus 4.6 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| Input | $5.00 | $5.00 | $3.00 | $0.80 |
| Output | $25.00 | $25.00 | $15.00 | $4.00 |
| Cache write (5 min) | $6.25 | $6.25 | $3.75 | $1.00 |
| Cache write (1 hour) | $10.00 | $10.00 | $6.00 | $1.60 |
| Cache read | $0.50 | $0.50 | $0.30 | $0.08 |
| Batch API | 50% discount | 50% discount | 50% discount | 50% discount |
| Tokenizer | v2 new | v1 | v1 | v1 |
| Same-text token change | 1.0-1.35x | baseline | baseline | baseline |
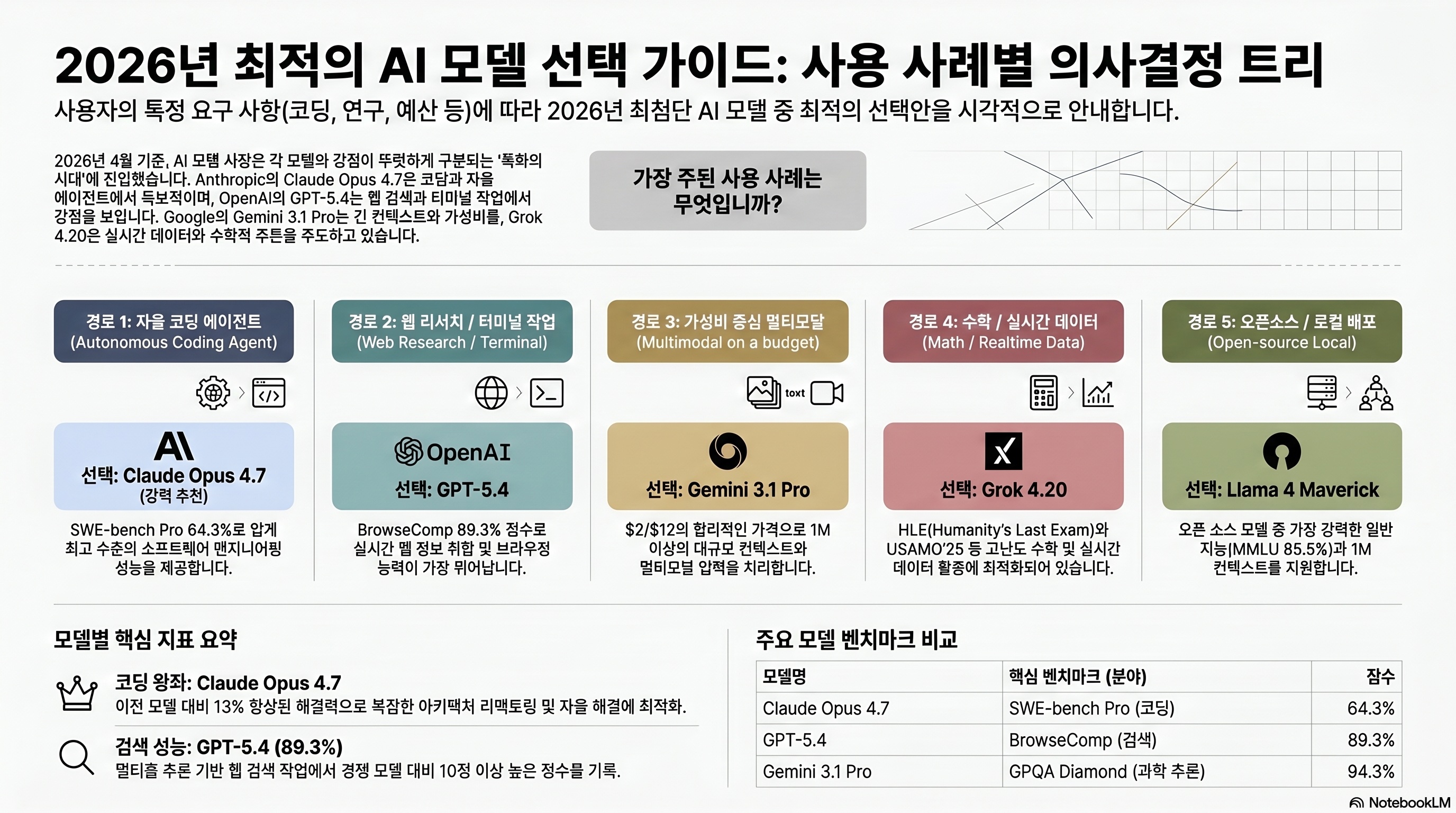
Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro - which one should you use?
Once the benchmark and cost picture is clear, the real question is routing. Opus 4.7, GPT-5.4, Gemini 3.1 Pro, and Grok 4.20 now each have a distinct lane.
Coding agents: Opus 4.7 first
Opus 4.7 leads on SWE-bench Pro, OSWorld, and MCP-Atlas. Cursor’s model docs explicitly position it for autonomous long-session coding and multi-file refactors (source: Cursor Docs). The caveat is Terminal-Bench 2.0, where GPT-5.4 at 75.1% beats Opus 4.7 at 69.4%. For shell-heavy workloads, test GPT-5.4 too.
Web research and terminal work: GPT-5.4 remains strong
BrowseComp is GPT-5.4’s territory: 89.3% vs Opus 4.7’s 79.3%. Opus 4.7 even falls below Opus 4.6 on this benchmark. If your workflow is deep web research in a single browser session, GPT-5.4 is the safer default. GPQA Diamond is effectively tied, with GPT-5.4 at 94.4% and Opus 4.7 at 94.2%.
Multimodal value: Gemini 3.1 Pro
Gemini 3.1 Pro is cheaper at $2 input and $12 output per 1M tokens. It is the better fit for document, slide, image, and video analysis, especially when cost matters. Its SWE-bench Pro score, however, is weaker than Opus 4.7. If your team needs local open-source deployment, the Gemma 4 review is the better place to start.
| Item | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro | Grok 4.20 |
|---|---|---|---|---|
| Price input / output | $5 / $25 | $2.50 / $15 | $2 / $12 | $3 / $15 |
| Context | 1M input, 128K output | 1.05M, 2x price over 272K | 1M | 260K |
| Strength | SWE-bench Pro, OSWorld, MCP-Atlas | Terminal-Bench, BrowseComp, GPQA | MMMLU, multimodal value | Realtime data, math |
| Weakness | BrowseComp, MRCR regression | MCP-Atlas weaker | Lower SWE-bench Pro | Narrow benchmark coverage |
| Best use | Autonomous coding agents, large refactors | Web research, terminal, science QA | Documents, video, slide analysis | Math and realtime search |
| Release | 2026-04-16 | 2026-01 update | 2026-03 | 2026-03 |
How should you use xhigh mode and Task Budgets?
The most practical new knobs in Opus 4.7 are effort control and task-level token budgeting. Both can break old 4.6 code if you pass deprecated parameters.
When to enable xhigh effort
The effort levels are now low / medium / high / xhigh / max. Use them like this:
high: default for most coding and refactor tasksxhigh: autonomous agents, large PR review, SWE-bench Pro-style tasksmax: math proofs or research problems without tight time limits
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=8000,
thinking={"type": "enabled", "effort": "xhigh"},
messages=[
{
"role": "user",
"content": "Refactor this legacy module into a functional style and write unit tests for failure cases.",
}
],
)
print(message.content)thinking now accepts enabled or disabled. The old budget_tokens field is removed for Opus 4.7. The model decides the reasoning length adaptively.
Task Budgets beta for cost control
Autonomous agents need a hard ceiling. Task Budgets lets you set a token budget for one task, not just one response (source: Claude Platform Docs).
curl https://api.anthropic.com/v1/messages \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: task-budgets-2026-03-13" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-7",
"max_tokens": 20000,
"metadata": {"task_budget": {"max_tokens": 50000}},
"messages": [
{"role": "user", "content": "Scan this repo and write a TypeScript migration plan."}
]
}'When the task budget is exhausted, the agent stops early and returns partial progress. This is the safety rail that prevents one runaway agent loop from burning hundreds of dollars.
Migration checklist
Before replacing 4.6 in production, check these three points:
- Remove
temperature,top_p, andtop_koverrides. - Remove
thinking.budget_tokens. - Update any parser that expected raw thinking output; the default is summarized thinking.
What do 3.75MP vision and filesystem memory change?
Opus 4.7 is not only a better model; it is a bigger agent substrate.
2576px vision
Opus 4.6 accepted images up to about 1568px, roughly 1.15MP. Opus 4.7 raises that to 2576 x 2576px, around 3.75MP (source: Claude Platform Docs). That matters for dashboard screenshots, PCB photos, CAD drawings, and other images where details get lost after resizing. It also helps explain the CharXiv Reasoning and OfficeQA Pro jumps.
Filesystem-based memory
Anthropic introduced a filesystem-memory pattern where an agent saves and loads state across sessions. A refactor agent can write progress into a .claude/state/session-xyz.json file on Monday and continue from that state on Wednesday. Simon Willison analyzed how Opus 4.7 treats /memories/ as a filesystem-like pattern in its system prompt (source: Simon Willison).
Claude in PowerPoint and Claude Design with Canva
Anthropic also announced Claude in PowerPoint and a Claude Design partnership with Canva around the same launch window (source: The Next Web). The broader message is clear: Opus is moving out of the chat UI and into office, design, and development workflows.
Opus 4.7 more often runs a quiet sanity check after tool calls and before returning the answer. In practice, it catches JSON schema violations, wrong function signatures, and obvious post-tool mistakes more reliably than 4.6.
Where did Opus 4.7 regress?
After the launch excitement, a more complicated story emerged. Opus 4.7 is not a straight upgrade for every task.
MRCR 78.3% -> 32.2%
MRCR, or Multi-needle Retrieval Context Recall, asks a model to find multiple specific facts inside a long context. Opus 4.7 scores 32.2%, down from 78.3% for Opus 4.6 (source: RoboRhythms). If your workflow is “put 1M tokens of documents into the prompt and find the exact quote,” Opus 4.6 may still be the better model.
NYT Connections also reportedly drops from 94.7% to 41%, which suggests weaker everyday language pattern matching in some contexts.
Do not immediately delete your 4.6 route. A realistic setup is Opus 4.7 for coding agents, Opus 4.6 or GPT-5.4 for pinpoint document retrieval, and Gemini for high-volume multimodal analysis.
Creative writing and emotional support feel flatter
Reddit users report that Opus 4.7 can feel more clinical in emotional-support conversations and less imaginative in fiction or copywriting. A likely explanation is stronger factuality and safety tuning. For counseling-like conversation, fiction, and brand copy, Opus 4.6 or GPT-5.4 may still feel more natural.
Latency is slower than GPT-5.4
Artificial Analysis measures first-token latency around 3.8 seconds for Opus 4.7, roughly twice GPT-5.4’s 1.9 seconds (source: Artificial Analysis). Generation speed is around 52 tokens/sec, about half of Sonnet 4.6. For realtime chat UX, that delay is visible.
What is the community saying?
The reaction split into two narratives: “coding-agent breakthrough” and “hidden cost increase.”
- "Opus 4.7 split a monolithic module into 23 parts on its own and kept the unit tests consistent." — r/OpenAI
- "For UI mockups, Opus 4.7 is way better. The attention to detail is different." — r/ArtificialIntelligence
- "It holds up around 275K tokens. 4.6 already felt shaky near 200K." — Hacker News thread
- "Best suited for autonomous, long-session coding and multi-file refactors." — Cursor model docs
- "The tokenizer change is a hidden price increase. The same 4.6 prompt produced a 28% higher bill." — r/ClaudeCode
- "My session quota went from hours to minutes after switching to 4.7." — r/ClaudeAI
- "It feels like a front-desk therapist for emotional support. The warmth from 4.6 is gone." — r/OpenAI
- "It regressed on complex engineering tasks in our internal evals." — public comment from an AMD senior director
Simon Willison highlighted the new /memories/ filesystem pattern as an interesting agent-implementation signal (source: Simon Willison). Cursor made Opus 4.7 a recommended coding model. Hacker News sent the launch thread to the front page with hundreds of comments (source: Hacker News).
Who should use Claude Opus 4.7?
Pros
- + Top-tier autonomous coding-agent scores, including SWE-bench Pro 64.3%
- + Strong computer-use and tool-calling benchmarks: OSWorld 78%, MCP-Atlas 77.3%
- + xhigh mode and Task Budgets give better control over reasoning depth and cost
- + 2576px vision, 1M input, and 128K output fit large workloads
- + ASL-3 safety posture and enterprise cloud availability
Cons
- − Tokenizer change can raise effective cost by 1.0-1.35x
- − MRCR and NYT Connections regressions make long-context retrieval risky
- − BrowseComp is weaker than GPT-5.4 and even Opus 4.6
- − First-token latency and generation speed are not ideal for realtime chat UX
- − Creative writing and emotional-support tone may feel flatter than 4.6
Recommended for
- Full-codebase refactors, type migrations, and test generation
- Autonomous CI agents that review PRs and patch code
- Computer-use automation and RPA-like workflows
- MCP tool chains with many internal tools connected
- High-resolution screenshot, dashboard, CAD, and document-image analysis
Not recommended as the default for
- Deep web research: GPT-5.4 is stronger on BrowseComp.
- Exact quote retrieval from huge documents: keep Opus 4.6.
- Fiction, copywriting, and emotional-support chat: test 4.6 or GPT-5.4.
- Cost-sensitive chatbots: Sonnet 4.6 or Haiku 4.5 is far cheaper.
Pro/Max subscription vs API
For individuals, Claude Pro or Max can still be cheaper than direct API usage, but Opus 4.7 burns quota faster. For teams, direct API usage with prompt caching, Batch API, and budget alerts is easier to control. Larger organizations may prefer Bedrock or Vertex AI for procurement and compliance reasons.
Conclusion
Key takeaway
Claude Opus 4.7 is the strongest public model right now for coding agents, computer use, and MCP-heavy workflows. It is not a universal upgrade. The tokenizer can raise cost, long-context retrieval regressed, and creative writing feels flatter to some users. Treat it as a coding-agent specialist, not as one model to replace every route.
Use Opus 4.7 if you are refactoring large codebases with autonomous agents, connecting many MCP tools, analyzing high-resolution technical images, or choosing the best available model inside Claude Code, Cursor, or Copilot. Keep GPT-5.4, Gemini 3.1 Pro, and Opus 4.6 in the router for research, multimodal volume, and exact long-document retrieval.
Remove deprecated API parameters
Delete temperature, top_p, top_k, and thinking.budget_tokens from Opus 4.7 calls. Otherwise production requests can fail with 400 errors.
Measure token expansion on 500 real samples
Run existing 4.6 prompts against the 4.7 model ID and compare token counts. If the increase is above 1.25x, enable prompt caching and raise budget alerts before rollout.
Split coding and research routes
Route coding agents to Opus 4.7 with high or xhigh effort. Route long-document retrieval to Opus 4.6 or GPT-5.4. Publish the routing rule internally so teams do not mix them up.
- Anthropic official announcement
- Claude Platform Docs - What’s new in Claude 4.7
- The Next Web - Anthropic Claude Opus 4.7 benchmarks
- Vellum AI - Claude Opus 4.7 benchmarks explained
- Finout - the real cost story
- Artificial Analysis - Claude Opus 4.7 profile
- Help Net Security - Claude Opus 4.7 released
- RoboRhythms - Opus 4.7 regression backlash
- Simon Willison - Opus 4.7 system prompt analysis
- Cursor Docs - claude-opus-4-7 model
- Hacker News launch thread
What is the Claude Opus 4.7 model ID?
Can I reuse Opus 4.6 prompts unchanged?
Is Opus 4.7's 1M context better than GPT-5.4's context?
When should I use xhigh mode?
How do I use Opus 4.7 inside Claude Code?
How can I reduce the 1.35x tokenizer cost issue?
Was this helpful?
One tap shapes what gets written next.
Topic tags

GPT-5.5 Review: Benchmarks, Pricing, Codex Impact, and Early Reactions (2026)
What changed in GPT-5.5, where it leads on agent benchmarks, why pricing looks 2x higher, and how Codex users should think about upgrading as of April 2026.
Read
GLM 5.1 Review: Run Claude Code at 1/5 the Price with Open-Weight SOTA
How to run GLM 5.1 in Claude Code at one-fifth the cost, plus what Z.AI's official docs reveal about subscription-backed API access, Vision MCP, and GLM-Image.
Read
Kimi K2.6 Deep Dive: 88% Cheaper Claude Opus 4.7 Alternative?
Kimi K2.6 is an open-weight MoE model with SWE-Bench Pro 58.6, HLE 54.0, 300-agent swarms, 256K context, and API pricing about 88% below Claude Opus 4.7.
Read