클로드 코드 토큰 절약법, 60~90% 줄이는 rtk 사용법 (2026)
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.

빠른 결론
먼저 이렇게 보면 됩니다
약 47분 읽기한 줄 판단
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- 클로드 코드 · 토큰 절약 · AI 코딩 비용
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- 결론부터: RTK(Rust Token Killer)는 CLI 명령 출력을 LLM에 닿기 전에 압축해 토큰을 줄이는 도구다. 테스트·빌드·대형 diff를 자주 돌린다면 설치 가치가 높지만, “설치만 하면 무조건 60–90% 절약”은 사실이 아니다.
- 절감률은 명령마다 갈린다.
cargo test·pytest는 90%대까지 줄지만,git status·git log처럼 짧은 출력은 0%이거나 오히려 토큰이 늘 수 있다(역효과). 혼합 워크로드 실사용 추정치는 10–30%가 정직하다. - 무료 오픈소스이고 한 줄로 설치된다. 먼저
rtk init으로 훅을 켜고rtk gain으로 본인 프로젝트 실측을 확인한 뒤 도입 여부를 판단하는 편을 권장한다.
목차
- 결론부터: RTK, 설치할 가치가 있을까?
- 클로드 코드 토큰, 왜 이렇게 빨리 닳을까?
- RTK는 토큰을 어떻게 줄일까?
- RTK 설치와 설정, 한 줄로 끝낼 수 있을까?
- 실제로 토큰이 얼마나 줄어들까?
- 모든 명령에서 똑같이 절약될까, 한계는 없을까?
- 압축 때문에 정보가 누락되거나 위험하진 않을까?
- RTK 말고 다른 토큰 절약 방법은?
- 개발자들은 RTK를 실제로 어떻게 평가할까?
- 결론
- 자주 묻는 질문
결론부터: RTK, 설치할 가치가 있을까?
먼저 판정부터 내린다. RTK는 “정액제 한도가 자주 터지고, 테스트·빌드·대형 git diff를 LLM에 자주 물리는” 사용자에게는 설치 가치가 높다. 반대로 짧은 명령 위주로 가볍게 쓰는 사용자라면 체감 절감은 작다. 이건 도구가 나빠서가 아니라, RTK가 줄이는 대상이 “출력이 큰 명령”에 집중돼 있기 때문이다.
RTK가 정확히 무엇인가
RTK는 “Rust Token Killer”의 약자로, git status·cat·cargo test 같은 CLI 명령의 출력을 LLM 컨텍스트에 들어가기 전에 필터·압축하는 단일 Rust 바이너리다. 제로 의존성으로 빌드되고, 공식 README는 60–90% 토큰 절감과 100개 이상 지원 명령, 10ms 미만 오버헤드를 표방한다 (출처: rtk-ai/rtk GitHub). 2026년 1월 출시 이후 별 수가 4월 말 39.5k에서 5월 56.7k로 한 달 새 약 17k 늘었고, 최신 버전은 v0.42.0(2026-05-24)이다 (출처: rtk v0.42.0 릴리스).
페르소나별 한 줄 판정
도입 가치는 사용 패턴에 따라 정반대로 갈린다. 자신이 어느 쪽인지부터 확인하는 편이 빠르다.
- 설치 권장 그룹: Rust·Go·Python 프로젝트에서
cargo test·go test·pytest를 LLM에게 자주 시키는 사용자. 테스트 러너 출력은 RTK가 가장 잘 줄이는 영역이라 90%대 절감이 나온다 (출처: rtk-ai.app). - 조건부 권장 그룹: 대형 모노레포에서
git diff·git log를 LLM에게 자주 읽히는 사용자. 큰 diff는 잘 줄지만, 짧은 diff·log는 거의 안 줄어든다. - 체감 적은 그룹: 주로 짧은
git status나 단순 파일 읽기 위주로 쓰는 사용자. 이 경우 절감이 0%에 가깝거나 일부 명령에선 토큰이 더 늘 수도 있다.
설치 전 알아둘 한계
설치 가치를 판단할 때 광고 수치만 보면 실망하기 쉽다. RTK의 자동 재작성 훅은 Bash 도구 호출에만 적용되는데, 정작 Claude Code는 파일 읽기·검색의 상당 부분을 Bash 없이 내장 툴(Read/Grep/Glob)로 처리한다. 그래서 토큰을 가장 많이 먹는 작업 일부가 훅을 그냥 지나친다 (출처: RTK Issue #538). 이 구조적 한계는 6번 섹션에서 자세히 다룬다. 일단은 “RTK는 만능 절약기가 아니라 특정 명령군에 강한 도구”라는 점만 기억하면 된다.
장점
- + 테스트·빌드·대형 diff 출력에서 80–99% 토큰 절감 (큰 출력일수록 효과적)
- + 무료 오픈소스, 한 줄 설치 + rtk init 한 번이면 자동 적용
- + 에러·스택트레이스·diff는 보존하도록 설계, 추론 품질 저하 위험 낮음
- + rtk gain·rtk session으로 본인 프로젝트 실측치를 직접 확인 가능
단점
- − 자동 훅이 Bash 호출에만 적용 → 내장 툴(Read/Grep/Glob) 작업은 우회(#538)
- − 짧은 명령(git status/log)은 절감 0%이거나 역효과 가능
- − 압축 입력이 모델 출력을 늘려 오히려 비용이 18% 증가한 사례(#582)
- − Windows 네이티브는 자동 재작성 불가, WSL 또는 CLAUDE.md 폴백 필요
클로드 코드 토큰, 왜 이렇게 빨리 닳을까?
RTK를 이해하려면 먼저 “왜 토큰이 이렇게 빨리 사라지는가”를 알아야 한다. 답은 단순하다. 코딩 에이전트는 코드를 쓰는 데보다 문맥을 읽는 데 압도적으로 많은 토큰을 쓴다.
토큰의 99.4%는 코드 작성이 아니라 “읽기”에 쓰인다
한 사용자가 r/ClaudeAI에서 자신의 Claude Code 사용량을 추적한 결과가 이 구조를 적나라하게 보여준다. 1,289개 요청에 걸쳐 총 100.9M 토큰이 소모됐는데, 그중 입력이 100.3M(99.4%)이고 출력은 단 616K(0.6%)였다. 작성자의 표현을 빌리면 “Claude Code는 토큰 예산의 99.4%를 문맥 읽기에 쓰고, 0.6%만 코드 작성에 썼다” (출처: r/ClaudeAI).
다만 여기엔 중요한 단서가 붙는다. 그 입력 토큰의 약 84%는 캐시(cached)된 토큰이라, “입력 100M = 전부 풀가격 청구”는 아니다. 캐시 히트는 단가가 크게 낮다. 즉 “99.4%가 읽기”라는 수치가 곧 “비용의 99.4%“를 뜻하지는 않는다. 이 뉘앙스는 뒤에서 다룰 비용 역설과도 연결된다. 그래도 방향성은 분명하다. 컨텍스트에 들어가는 명령 출력이 토큰 소모의 핵심 동인이라는 점이다.
명령 출력의 70%가 “노이즈”라는 주장
RTK 측이 제시하는 공식 수치는 더 공격적이다. 홈페이지에 따르면 정액제 사용자는 rate limit에 40% 더 빨리 도달하고, 종량제 사용자는 청구액의 70%가 불필요한 노이즈에서 나오며, 10인 팀 기준 월 약 $1,750가 노이즈 토큰으로 낭비된다고 본다 (출처: rtk-ai.app). 이 수치들은 벤더 자체 추정이라는 점을 감안해서 읽어야 한다. 다만 “터미널 출력에 LLM이 굳이 읽을 필요 없는 줄이 많다”는 문제 인식 자체는 독립 사용자들도 대체로 공감하는 부분이다.
2시간 세션이면 노이즈만 21만 토큰
체감하기 쉽게 시나리오로 풀어보자. 2시간짜리 코딩 세션에서 에이전트가 약 60개의 CLI 명령을 실행한다고 하면, 명령당 평균 약 3,500토큰으로 잡아 대략 210K 토큰이 컨텍스트에 쌓인다. RTK를 적용하면 이게 약 23K로 줄어 89% 감소한다는 게 벤더의 계산이다 (출처: rtk-ai.app). 물론 이건 “출력이 큰 명령이 많은 세션”을 가정한 best-case에 가깝다. 짧은 명령 위주 세션이라면 이 시나리오만큼 줄지 않는다. 토큰 한도와 가격 구조 자체가 궁금하다면 클로드 코드 가격·한도 정리 글을 함께 참고하면 비용 압박의 배경이 더 선명해진다.
RTK는 토큰을 어떻게 줄일까?
RTK의 작동 방식은 “LLM과 시스템 도구 사이에 끼는 필터 계층”이라는 한 문장으로 요약된다. 공식이 내세우는 60–90% 절감의 정체도 결국 이 필터링이다. 명령을 직접 실행하되, 그 출력을 LLM에 넘기기 전에 4가지 전략으로 다듬는다.
4대 압축 전략
RTK가 출력을 줄이는 방식은 README의 “How It Works”에 4가지로 정의돼 있다 (출처: rtk-ai/rtk GitHub).
- Smart Filtering(스마트 필터링): 주석·공백·보일러플레이트 같은 노이즈를 제거한다.
cat·파일 읽기, 테스트 러너 출력에 주로 적용된다. - Grouping(그룹화): 유사 항목을 집계한다. 파일은 디렉터리별로, 에러는 유형별로 묶는다.
ls·tree·find의 긴 목록이 대상이다. - Truncation(잘라내기): 핵심 문맥은 유지하면서 중복 구간을 잘라낸다. 방대한
git diff·git log에 쓰인다. - Deduplication(중복 제거): 반복되는 로그 줄을 “1줄 + count” 형태로 접는다.
npm install로그나docker ps의 반복 출력에 효과적이다.
이 4개를 조합해 “2,900개 이상의 실제 명령 평균 89% 노이즈 제거”를 달성했다는 게 RTK 측 집계다 (출처: rtk-ai.app). 단, 이 평균은 출력이 큰 명령이 섞인 표본이라는 점을 염두에 둘 필요가 있다.
명령이 거치는 파이프라인
내부적으로 명령은 다섯 단계를 거친다. DeepWiki의 아키텍처 정리에 따르면, RTK는 명령을 Parse(Clap으로 파싱) → Route(src/cmds/로 라우팅) → Execute(std::process::Command로 실제 실행) → Filter(None/Minimal/Aggressive 레벨로 필터링) → Track(로컬 SQLite에 절감 기록) 순서로 처리한다 (출처: DeepWiki rtk-ai/rtk). 핵심은 RTK가 출력을 가짜로 만들어내는 게 아니라, 실제 명령을 그대로 실행한 뒤 그 결과를 압축한다는 점이다.
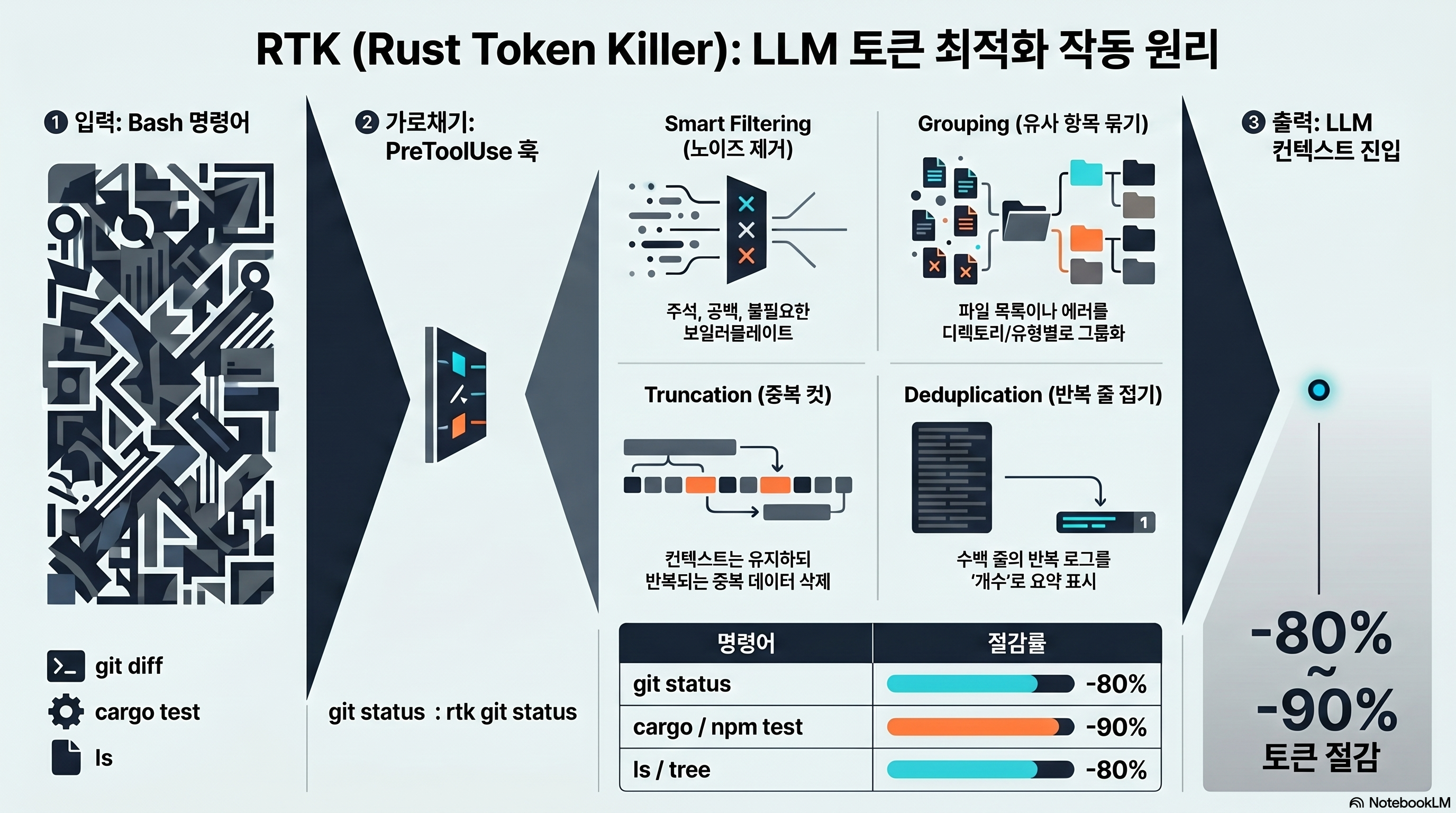
PreToolUse 훅: 토큰 오버헤드 0의 자동화
사용자가 매번 rtk를 직접 칠 필요는 없다. RTK는 Claude Code의 PreToolUse 훅에 등록돼, 에이전트가 git status를 호출하면 훅이 이를 투명하게 rtk git status로 재작성한다. 이 재작성은 모든 대화와 서브에이전트에 100% 적용되고, 훅 자체의 토큰 오버헤드는 0이다.
여기서 가장 중요한 단서가 나온다. 이 훅은 Bash 도구 호출에만 작동한다. 즉 에이전트가 Bash를 거치지 않고 처리하는 작업은 RTK를 그냥 지나친다. 이 한 줄이 RTK 체감 절감의 운명을 가르는데, 그 이유는 다음 섹션에서 설치를 끝낸 뒤 본격적으로 다룬다.
RTK 설치와 설정, 한 줄로 끝낼 수 있을까?
설치 자체는 정말 한 줄이다. 다만 설치 경로에 따라 “설치는 됐는데 훅이 조용히 작동 안 하는” 함정이 있어서, 그 부분을 짚어가며 진행한다.
설치 3가지 방법
가장 간단한 방법은 공식 설치 스크립트다. Linux·macOS에서 아래 한 줄이면 ~/.local/bin에 바이너리가 설치된다.
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | shHomebrew를 쓴다면 brew install rtk로도 설치되고, 업데이트는 brew upgrade rtk로 한다. 다만 Homebrew 경로(/opt/homebrew/bin)가 Claude Code의 제한된 PATH에 안 잡혀서 훅이 무음으로 실패하는 사례가 보고됐으니 주의해야 한다 (출처: RTK Issue #685).
Rust 사용자는 Cargo로 설치할 수 있는데, 여기엔 반드시 지켜야 할 함정이 하나 있다.
cargo install --git https://github.com/rtk-ai/rtk⚠️ 주의: cargo install rtk라고만 치면 crates.io에 있는 동명의 다른 패키지(“Rust Type Kit”)가 설치된다. RTK(Rust Token Killer)를 설치하려면 반드시 --git 플래그로 저장소를 직접 지정해야 한다.
훅 활성화와 재시작
설치 후에는 Claude Code에 훅을 등록해야 자동 재작성이 작동한다.
rtk init --claude-code이 명령은 Claude Code의 settings.json에 PreToolUse 훅을 설치한다(전역 적용은 rtk init -g). 등록 후에는 Claude Code를 재시작해야 훅이 활성화된다. 재시작을 빼먹으면 “설치는 했는데 아무것도 안 줄어든다”는 첫 번째 오해가 여기서 생긴다. RTK는 공식적으로 Claude Code, GitHub Copilot, Cursor, Gemini CLI, Codex, Windsurf, Cline/Roo, OpenCode, Kilo Code, Google Antigravity 등 14개 도구를 지원한다(Mistral Vibe는 예정) (출처: rtk-ai/rtk GitHub). 참고로 Claude Code 자체의 설치와 CLAUDE.md 설정 기본기는 클로드 코드 설치·CLAUDE.md 설정 글에 정리돼 있다.
바이너리 설치
Linux/macOS는 install.sh 한 줄, Homebrew는 brew install rtk, Rust는 cargo install --git 으로 설치한다.
설치 검증
rtk --version 으로 버전이 출력되는지 확인한다. gain 명령이 없다고 나오면 잘못된 rtk가 설치된 것이다.
훅 등록
rtk init --claude-code 를 실행해 settings.json에 PreToolUse 훅을 설치한다. 전역 적용은 rtk init -g 를 쓴다.
Claude Code 재시작
훅은 재시작 후 활성화된다. 재시작하지 않으면 자동 재작성이 작동하지 않는다.
실측 확인
며칠 사용한 뒤 rtk gain 으로 본인 프로젝트의 누적 절감률을 확인한다.
설치가 꼬였을 때: 이름 충돌 진단
설치 후 가장 흔한 사고가 앞서 말한 이름 충돌이다. 증상은 명확하다. rtk gain을 실행했을 때 “‘gain’ is not a rtk command” 같은 에러가 뜨면, 십중팔구 crates.io의 “Rust Type Kit”이 설치된 상태다.
rtk --version⚠️ 주의: 버전 확인 후 엉뚱한 도구로 판명되면 cargo uninstall rtk로 제거한 뒤 공식 install.sh로 다시 설치한다. 검증을 건너뛰면 며칠 동안 “왜 절약이 안 되지?”를 헤매게 된다.
실제로 토큰이 얼마나 줄어들까?
여기가 이 글의 핵심이다. RTK를 둘러싼 가장 큰 오해는 “60–90%“라는 숫자를 하나의 단일 평균값으로 받아들이는 것이다. 실제로는 명령마다 절감률이 0%부터 99%까지 극단적으로 갈린다.
표 A — 30분 세션 누적 시뮬레이션
먼저 RTK README가 제시하는 “30분 Claude Code 세션” 누적 추정이다. 명령별 빈도를 가정해 표준 출력 대비 RTK 출력 토큰을 비교한 값이다.
| 명령 | 빈도 | 표준 토큰 | RTK 토큰 | 절감률 |
|---|---|---|---|---|
| git add/commit/push | 8x | 1,600 | 120 | -92% |
| cargo test | 5x | 25,000 | 2,500 | -90% |
| pytest | 4x | 8,000 | 800 | -90% |
| go test | 3x | 6,000 | 600 | -90% |
| ls | 10x | 2,000 | 400 | -80% |
| grep | 8x | 16,000 | 3,200 | -80% |
| git status | 10x | 3,000 | 600 | -80% |
| git log | 5x | 2,500 | 500 | -80% |
| docker ps | 3x | 900 | 180 | -80% |
| git diff | 5x | 10,000 | 2,500 | -75% |
| cat | 20x | 40,000 | 12,000 | -70% |
| 합계 | — | 약 118,000 | 약 23,900 | -80% |
(출처: rtk-ai/rtk GitHub README) 단, README도 단서를 명시한다. “중간 규모 TypeScript/Rust 프로젝트 기준 추정이며, 실제 절감은 프로젝트 크기에 따라 달라진다.” 즉 이 표는 가정된 빈도에 기반한 시뮬레이션이지 보장치가 아니다.
표 B — 단일 명령 직접 비교에서 드러나는 편차
훨씬 더 솔직한 그림은 RTK 홈페이지의 “See the difference” 단일 명령 비교에서 나온다. 같은 명령이라도 출력 크기에 따라 절감률이 -99%에서 -46%까지 출렁인다.
| 명령 | 표준 토큰 | RTK 토큰 | 절감률 |
|---|---|---|---|
| cargo test | 4,823 | 11 | -99% |
| pytest -v | 756 | 24 | -96% |
| cat src/main.rs (rtk read -l aggressive) | 10,176 | 504 | -95% |
| git diff HEAD~1 | 21,500 | 1,259 | -94% |
| ls -la | 3,200 | 640 | -80% |
| git status | 120 | 30 | -75% |
| go test ./... -v | 592 | 246 | -58% |
| grep -rn | 2,108 | 940 | -55% |
| find . -name | 276 | 149 | -46% |
(출처: rtk-ai.app) 표 B가 표 A보다 중요한 이유는, 같은 명령군 안에서도 출력이 작으면 절감이 급격히 떨어진다는 점을 보여주기 때문이다. cargo test가 출력 4,823토큰일 땐 99% 줄지만, find처럼 애초에 짧은 출력은 46%에 그친다. “절감은 명령마다, 그리고 같은 명령이라도 출력 크기마다 다르다” — 이게 핵심 메시지다.
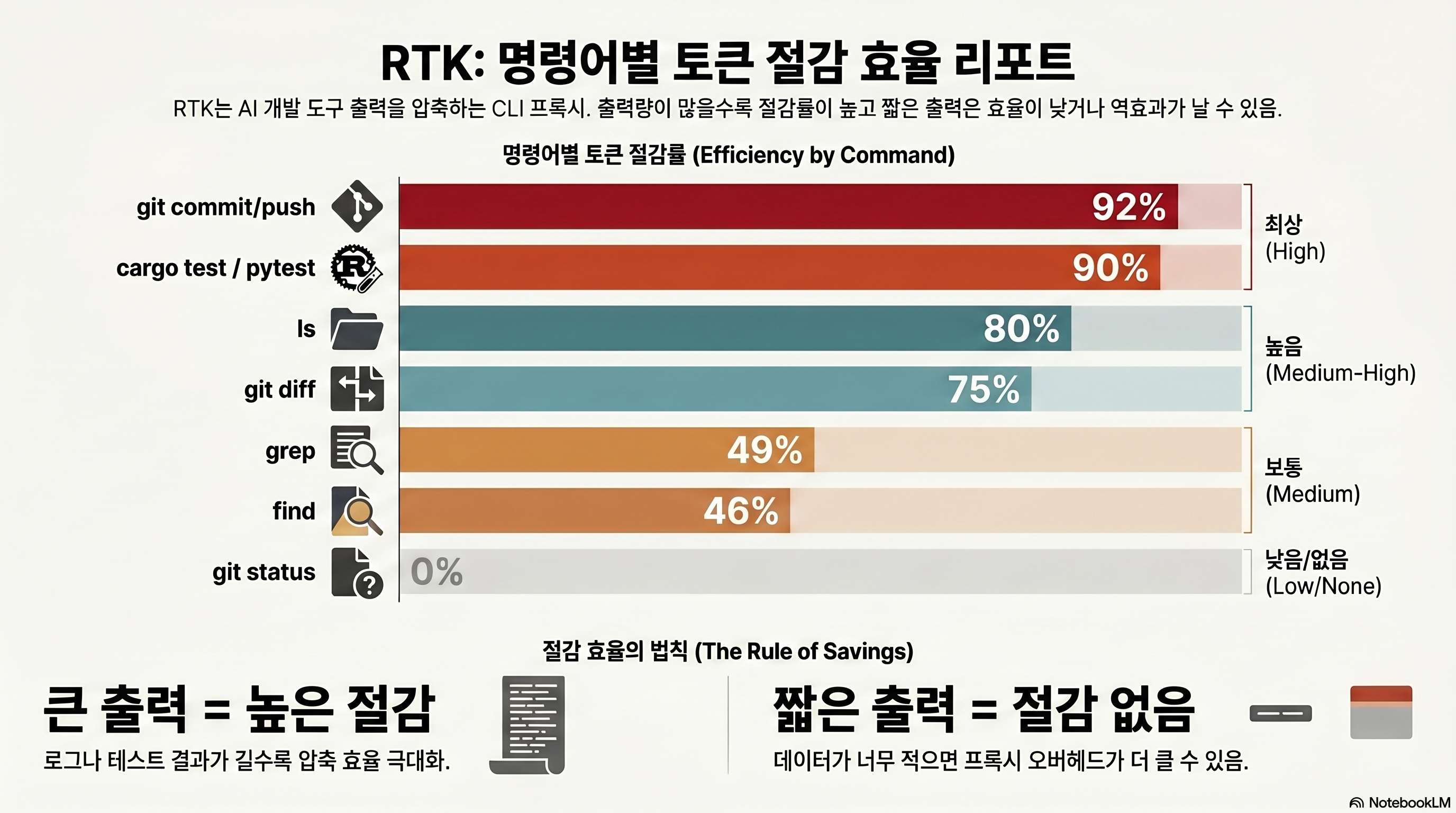
벤치마크 그래프
명령별 토큰 절감률 — 같은 도구, 다른 결과
RTK README/홈페이지 수치 기준, 큰 출력일수록 절감 폭이 크다
(출처: rtk-ai.app, rtk-ai/rtk README)
rtk gain — 본인 프로젝트의 진짜 숫자를 보는 법
남의 벤치마크보다 중요한 건 자기 프로젝트의 실측이다. RTK는 누적 절감을 보여주는 메타 명령을 내장한다.
rtk gain홈페이지에 공개된 데모 출력을 보면 전체 그림과 명령별 편차가 한눈에 들어온다. 총 2,927개 명령, 입력 11.6M 토큰 중 10.3M(89.2%)를 절감한 사례인데, 명령별로 뜯어보면 rtk cargo test는 91.8%인 반면 rtk grep은 49.5%로 절반에도 못 미친다 (출처: rtk-ai.app).
📊 RTK Token Savings
Total commands: 2,927 | Input 11.6M | Tokens saved: 10.3M (89.2%)
rtk find 324 78.3%
rtk git status 215 80.8%
rtk grep 227 49.5%
rtk cargo test 16 91.8%이 밖에도 v0.42.0에는 rtk discover(놓친 절감 탐색), rtk session(세션별 채택률), rtk cc-economics(ccusage 지출과 RTK 절감 비교), rtk learn(에러 이력 기반 CLI 교정 학습) 같은 메타 명령이 들어 있다. 다만 discover·cc-economics·learn은 공식 문서 설명이 빈약해 정확한 동작을 단정하기 어렵다. 특히 rtk discover는 세션 히스토리의 원본 명령 텍스트와 매칭하는 방식이라, 이미 재작성된 명령까지 “놓친 기회”로 과다 집계하는 문제가 보고됐다 (출처: RTK Issue #789). ⚠️ 주의: discover가 보여주는 숫자를 곧바로 “추가로 아낄 수 있는 잠재량”으로 읽으면 과대평가하게 된다.
모든 명령에서 똑같이 절약될까, 한계는 없을까?
여기서부터가 광고와 현실이 갈리는 지점이다. RTK의 한계는 결함이라기보다 구조적 제약에 가깝고, 이걸 모르면 “설치했는데 왜 안 줄지?”라는 좌절로 직결된다.
가장 결정적인 한계: 내장 툴 우회
RTK의 자동 훅은 Bash 도구 호출에만 작동한다. README도 이를 직접 인정한다. “훅은 Bash 도구 호출에서만 실행된다. Read, Grep, Glob는 Bash 훅을 거치지 않는다” (출처: RTK Issue #538). 문제는 Claude Code가 파일 읽기·검색 작업의 대부분을 Bash 없이 내장 툴로 처리한다는 데 있다. Claude Code의 시스템 프롬프트가 “전용 도구가 있으면 Bash를 쓰지 말라”고 지시하기 때문이다.
그 결과 토큰을 가장 많이 먹는 작업의 상당 부분이 RTK를 그냥 통과한다. Issue #538은 이 비율을 약 60%로 추정한다. 이게 사용자가 광고만큼 체감하지 못하는 1순위 이유다. 우회를 줄이려면 에이전트가 내장 툴 대신 cat·rg·find 같은 명시적 셸 명령을 쓰게 하거나, rtk read·rtk grep·rtk find를 직접 호출하도록 유도해야 한다.
대부분의 원인은 내장 툴 우회다. Claude Code가 파일을 Read 툴로 열고 Grep 툴로 검색하면, 그 토큰은 RTK 훅을 거치지 않는다. 자동 훅에만 의존하지 말고, 코드 탐색은 명시적 셸 명령이나 rtk 직접 호출로 돌려야 효과가 커진다. Homebrew 설치라면 PATH 문제(#685)도 함께 의심하자.
명령별 편차와 숨은 실패 2종
독립 측정자의 실측은 편차를 더 적나라하게 드러낸다. 개발자 jangwook의 측정에서 git status는 “None(오히려 역효과)”, git log --oneline은 0% 절감으로 나왔다. 반면 grep 49.5%, find 46%, go test 58%였고, 90%대는 테스트·find·cargo 같은 큰 출력에서만 나왔다 (출처: jangwook.net).
숨은 실패도 두 종류다. 하나는 위에서 본 내장 툴 우회(#538)이고, 다른 하나는 더 교묘하다. RTK 출력에 permissionDecision: "allow"가 떠버리면 Claude Code가 재작성을 폐기하고 원본 명령을 실행하는데, 이때 “에러는 없지만 압축 안 된 풀 토큰이 그대로 컨텍스트에 꽂힌다” (출처: Andrew Patterson). 사용자는 실패를 알아채지도 못한 채 절감만 사라진다.
Windows 제약과 비용 역설
⚠️ 주의: Windows 네이티브 환경에서는 자동 재작성 훅이 작동하지 않는다. 훅이 Unix 셸을 필요로 하기 때문이다. 대안으로 CLAUDE.md에 지침을 주입하는 폴백이 있지만 “70–80% best effort” 수준이라 신뢰도가 떨어진다 (출처: RTK Discussion #671). Windows 사용자라면 WSL을 권장한다.
가장 의외의 한계는 비용 역설이다. Issue #582는 “RTK의 PreToolUse 훅이 비용을 18% 증가시킨다”고 보고한다. 메커니즘은 이렇다. 압축된 입력을 받은 Claude가 빈틈을 메우려고 더 많이 출력하고, 출력 토큰이 늘면서 전체 비용이 오른다는 것이다. 엔트로피가 낮은(low-entropy) 파일에서는 오히려 +11.2%였다 (출처: RTK Issue #582). 입력 토큰을 줄이는 게 항상 총비용 절감으로 이어지지는 않는다는 반례다. 앞서 본 “입력의 84%는 캐시”라는 사실과 합치면, 입력 절감의 실질 효과는 광고 수치보다 보수적으로 잡는 편이 안전하다.
압축 때문에 정보가 누락되거나 위험하진 않을까?
토큰을 줄인다는 건 곧 정보를 버린다는 뜻이다. 그렇다면 “에이전트가 중요한 에러를 못 보고 엉뚱한 코드를 짜진 않을까?”라는 걱정이 자연스럽다. RTK는 이 지점을 설계로 방어하지만, 반례도 분명히 존재한다.
무엇을 버리고 무엇을 지키는가
RTK는 압축 강도를 None·Minimal·Aggressive 3단계로 조절한다. -l 플래그로 명령마다 지정할 수 있다(예: rtk read src/main.rs -l aggressive). 공식 FAQ의 핵심 약속은 명확하다. “보일러플레이트와 반복 노이즈만 제거하고, 테스트 실패·에러 메시지·diff·스택트레이스는 전부 보존(preserved in full)한다. 오히려 노이즈가 줄어 추론 품질이 향상되는 경우가 많다” (출처: rtk-ai.app FAQ).
다만 이 약속이 항상 지켜지는 건 아니다. jangwook은 “실패한 테스트의 스택트레이스가 일부 잘린” 사례를 보고했고, Hacker News에서도 “디버깅하려는데 필요한 출력이 억제될 때 곤란했다”는 반응이 있었다 (출처: jangwook.net). 즉 보존 약속은 일반적으로는 지켜지지만, 디버깅처럼 출력 전체가 중요한 상황에서는 압축 레벨을 낮추거나 끄는 판단이 필요하다.
실패 시 원본을 지키는 tee 모드
이런 정보 손실을 막기 위한 안전장치가 tee 모드다. 명령이 실패하면 RTK가 원본 출력 전체를 ~/.local/share/rtk/tee/에 보존한다. 모드는 failures(기본)·always·never로 설정할 수 있고, 압축을 완전히 우회하고 싶을 땐 메타 명령 proxy로 원본 명령을 그대로 실행할 수 있다 (출처: DeepWiki rtk-ai/rtk). ⚠️ 주의: 다만 “exit code 보존”이나 --raw 플래그 같은 세부 동작은 소스 근거가 부족해 단정하기 어렵다. 중요한 자동화 파이프라인에 넣기 전에는 직접 검증을 권장한다.
프라이버시: 텔레메트리는 기본 꺼짐
데이터 수집을 걱정하는 사용자라면 안심해도 된다. RTK의 텔레메트리는 opt-in이라 기본 비활성 상태이고, rtk init 중 명시적으로 동의하거나 rtk telemetry enable을 실행해야만 켜진다(GDPR 6·7조 근거). 수집하지 않는 항목도 명시돼 있다. 소스코드·파일경로·명령 인자·시크릿·환경변수·저장소 내용은 전송되지 않는다. 식별자는 솔트가 적용된 SHA-256 디바이스 해시이고, 실행·절감 데이터는 로컬 SQLite(rusqlite)에 저장된다 (출처: DeepWiki rtk-ai/rtk). 이 점은 사내 코드를 다루는 환경에서 특히 중요한 기준이 된다.
RTK 말고 다른 토큰 절약 방법은?
RTK 하나로 토큰 문제가 끝나지 않는다. 토큰 절감은 사실 여러 레이어에서 동시에 일어날 수 있고, RTK는 그중 한 레이어만 담당한다. 어느 레이어를 줄이는지를 기준으로 보면 도구 선택이 훨씬 명확해진다.
토큰 절감은 5개 레이어에서 일어난다
토큰이 소모되는 지점을 레이어로 나누면, 각 도구가 정확히 어디를 줄이는지 보인다. 아래 표는 시드 도구(RTK)를 1순위로 두지 않고, “독자가 어느 병목을 겪는가”를 기준으로 배치했다.
| 레이어 | 줄이는 대상 | 대표 도구 | 성격 |
|---|---|---|---|
| 인덱싱 | 코드 탐색(Read/Grep/Glob) 경로 | CodeGraph / context-mode (MCP) | RTK 사각지대를 보완 |
| 입력/API 프록시 | CLI 너머 비-CLI 출력(DB JSON·RAG·중첩 API) | Headroom | RTK를 번들 내장하는 상위 래퍼 |
| 출력(CLI) | 터미널 명령 출력 | RTK | Bash 훅으로 자동 재작성 |
| 응답(생성) | 모델이 뱉는 출력의 군더더기 | Caveman | 프롬프트로 출력 압축 |
| 단가($) | 토큰당 가격 | 모델 교체 (예: GLM 5.1) | 절대량이 아니라 단가를 낮춤 |
각 레이어를 풀어보면 이렇다. 먼저 인덱싱 레이어가 RTK가 손대지 못하는 Read/Grep/Glob를 가로채 압축한다. 예컨대 단일 Read 315KB를 5.4KB로 줄여 98% 절감한 측정이 있다. RTK가 CLI 출력을 압축한다면, 코드 탐색 단계의 토큰을 줄이는 CodeGraph는 코드 탐색 경로 자체를 줄여 RTK의 빈틈을 메운다. 비슷한 발상으로 코드·문서를 지식 그래프로 묶는 Graphify 방식도 탐색 토큰을 줄이는 인덱싱 접근에 속한다.
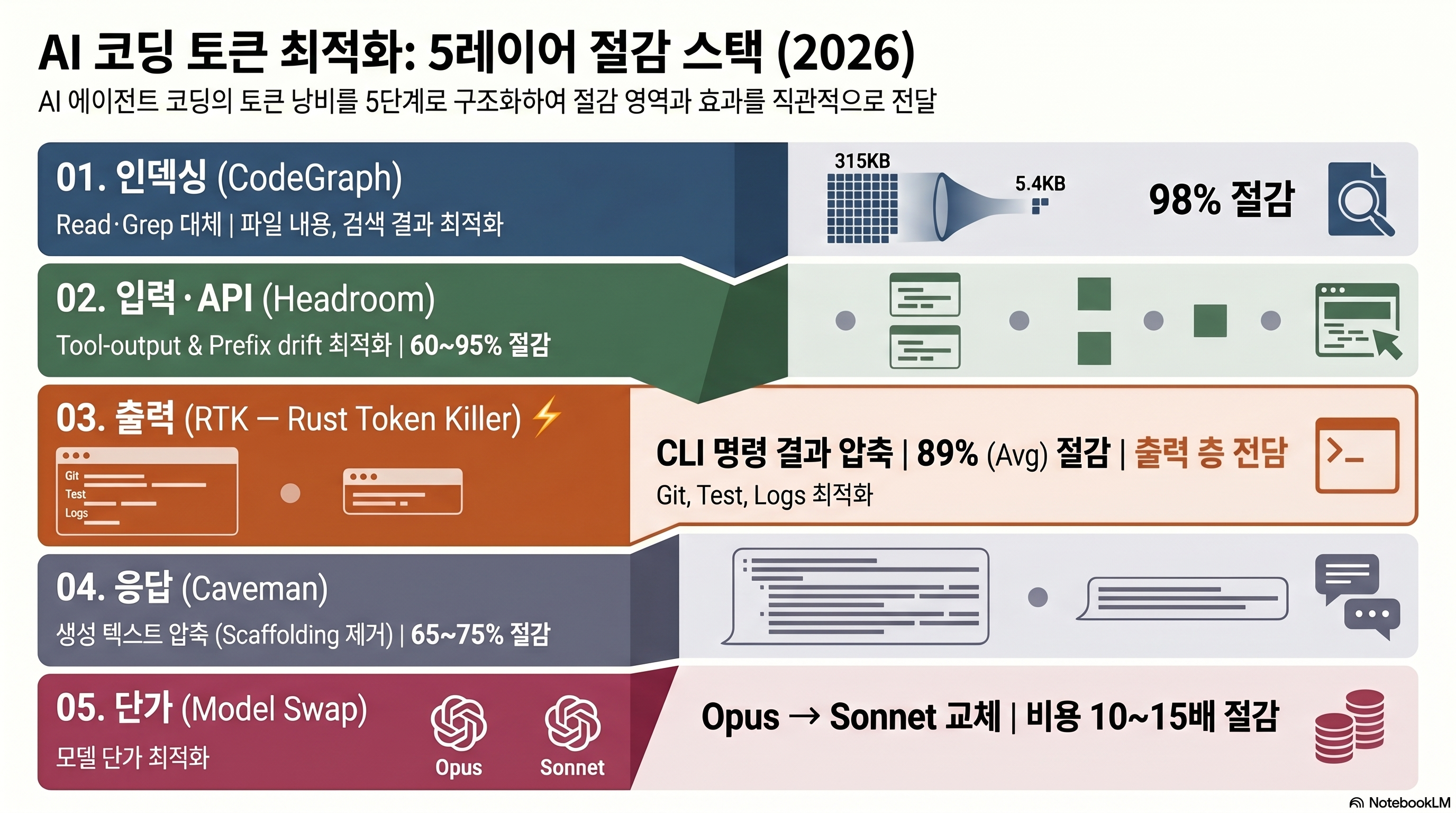
Headroom·Caveman·모델 교체
Headroom(github.com/chopratejas/headroom, 약 2.4k stars)은 입력/API 프록시 레이어에서 작동한다. CLI를 넘어 DB JSON·RAG 청크·중첩 API 같은 비-CLI 출력까지 압축하며, 자체 측정으로 코드 검색 92%, 중첩 JSON 85%, 약 50% 비용 절감을 표방한다. 결정적으로 Headroom은 RTK를 경쟁 상대가 아니라 보완재로 본다. 공식 설명에서 “훌륭한 RTK 바이너리를 함께 번들한다(ships with the excellent RTK binary)“고 밝히며 RTK 위에 얹히는 상위 래퍼로 자리매김한다 (출처: Headroom GitHub).
Caveman(JuliusBrussee/caveman, MIT)은 응답 레이어를 노린다. Claude가 “원시인 말투”로 답하게 만들어 filler와 hedging을 걷어내 출력을 50–75% 줄인다고 주장한다(자체 벤치 65%, 범위 22–87%). ⚠️ 주의: 다만 독립 측정에서는 30–40% 수준이었고, 효과의 상당 부분은 단순히 “be brief” 프롬프트에서 온다는 지적이 있다 (출처: Caveman GitHub).
마지막으로 모델 교체 방식은 토큰 절대량이 아니라 단가를 낮추는 접근이다. Opus는 Sonnet보다 10–15배 비싸므로, 작업에 따라 더 싼 모델로 갈아타 비용을 낮추는 GLM 5.1 방식처럼 모델을 바꾸면 토큰을 한 개도 안 줄이고도 비용이 떨어진다.
결합이 답이다 — 레이어가 다르면 효과는 더해진다
가장 설득력 있는 데이터는 Andrew Patterson의 한 달치 프로덕션 로그(26,779개 명령)다. RTK 단독으로 13.3억 토큰, Headroom 단독으로 1.89억 토큰을 절감했고, 둘을 결합하자 15.2억 토큰으로 두 효과가 거의 그대로 더해졌다(additive). 그의 결론은 “RTK와 Headroom은 서로 다른 레이어에서 작동하며 독립적이다” (출처: Andrew Patterson). 핵심 교훈은 분명하다. 어느 한 도구도 혼자선 토큰 문제를 끝내지 못한다. RTK가 터미널 노이즈를 60–90% 줄이고, 인덱싱이 탐색 토큰을 줄이며, 모델 선택이 단가를 10–15배 낮추는 식으로 레이어를 조합할 때 실질 효과가 가장 커진다.
개발자들은 RTK를 실제로 어떻게 평가할까?
마지막으로 실사용자들의 평가를 균형 있게 본다. RTK는 호불호가 꽤 갈리는 도구다. “그냥 잘 된다”는 호평과 “체감 차이 없다”는 회의가 동시에 존재하는데, 두 반응 모두 앞서 본 명령별 편차로 설명된다.
긍정: “그냥 잘 된다”
호평의 핵심은 설치 후 손이 안 간다는 점과 큰 출력에서의 확실한 절감이다. r/ClaudeAI에는 “그냥 잘 된다(it just works)”, “Game changer”라는 반응이 올라왔고, lmmartinb.com은 자신의 대시보드에서 136개 명령 기준 91.9% 절감을 보고했다 (출처: lmmartinb.com). Kilo Code 디스커션에서는 2주간 10M 토큰을 89% 절감했고 cargo test가 155줄에서 3줄로(98%), git status가 76% 줄었다는 측정도 나왔다. Hacker News의 총평도 “전반적으로 탄탄하다(pretty solid)“는 쪽이었다.
회의: “솔직히 체감 차이는 없다”
반대편 목소리도 그만큼 무겁다. 박재홍의 실리콘밸리 블로그는 제목부터 “토큰 비용 80% 줄이겠다는 야심찬 시도, 현실은 어떨까”로 회의적이다. 그는 “토큰은 줄었는데 오히려 더 쓰게 됐다는 역설 경험담이 쏟아진다”며 전체 일괄 도입보다 효과가 확실한 명령군부터 선별 도입할 것을 권한다 (출처: 박재홍의 실리콘밸리). jangwook은 더 구체적으로 “혼합 워크로드에서는 10–30%가 정직한 추정이며(광고 60–90% 대비), 실제 비용은 RTK가 안 건드리는 Read·Grep·코드 생성이 지배한다”고 짚었다 (출처: jangwook.net). 한국 커뮤니티 gpters에서는 커밋 1회에서 57.2%를 절감했지만 “솔직히 Claude Code 쓰는 입장에서 체감 차이는 없다”는 후기가 올라왔다 (출처: gpters.org).
- "그냥 잘 된다(it just works). 설치하고 신경 쓸 게 없다." — r/ClaudeAI
- "대시보드 기준 136개 명령에서 91.9% 절감했다." — lmmartinb.com
- "2주간 10M 토큰을 89% 절감, cargo test는 155줄에서 3줄(98%)로 줄었다." — Kilo Code Discussion
- "전반적으로 탄탄하다(pretty solid)." — Hacker News
- "혼합 워크로드에선 10–30%가 정직한 추정이다. 실제 비용은 Read·Grep·코드 생성이 지배한다." — jangwook.net
- "토큰은 줄었는데 오히려 더 쓰게 됐다는 역설 경험담이 쏟아진다." — 박재홍의 실리콘밸리
- "커밋 1회 57.2% 절감했지만, 솔직히 체감 차이는 없다." — gpters.org
- "$HOME에서 ls는 332토큰인데 rtk ls는 199% 손해였다." — Reddit
두 평가를 어떻게 읽을까
상반된 후기는 사실 모순이 아니다. 큰 출력을 자주 다루는 사용자(테스트·빌드 중심)는 호평을, 짧은 명령 위주이거나 내장 툴 의존도가 높은 사용자는 회의를 남긴다. 심지어 Reddit에는 “$HOME에서 ls는 332토큰인데 rtk ls는 오히려 199% 손해였다”는 극단적 역효과 사례까지 있다. 결국 평가의 갈림길은 도구 품질이 아니라 본인의 사용 패턴이다. 그래서 남의 후기보다 rtk gain으로 직접 측정한 자기 숫자가 가장 믿을 만한 판단 근거가 된다.
결론
핵심 요약
RTK는 CLI 명령 출력을 LLM에 닿기 전에 압축해 토큰을 줄이는 무료 오픈소스 도구다. 테스트·빌드·대형 diff 같은 큰 출력에서는 80–99%까지 줄지만, 짧은 명령에서는 0%이거나 역효과가 날 수 있어 “60–90%“를 단일 평균으로 받아들이면 안 된다. 자동 훅이 Bash 호출에만 적용돼 내장 툴 작업을 우회하는 구조적 한계(#538)와 압축이 출력을 늘려 비용이 오르는 역설(#582)까지 알고 도입해야 실망이 없다.
- Rust·Go·Python 개발자: cargo test·go test·pytest를 LLM에게 자주 시킨다면, 테스트 출력 압축만으로도 체감 절감이 크다.
- 정액제 한도가 자주 터지는 사용자: 대형 diff·로그를 자주 읽힌다면 rate limit 도달 속도를 늦출 수 있다.
- 여러 레이어로 비용을 최적화하려는 팀: RTK(출력) + 인덱싱(탐색) + 모델 교체(단가)를 결합하면 효과가 더해진다.
- 추천하지 않는 경우: 주로 짧은 명령·내장 툴 위주로 가볍게 쓴다면 체감이 작으니, rtk gain으로 먼저 측정한 뒤 결정하자.
한 줄로 설치
install.sh 한 줄 또는 brew install rtk 로 바이너리를 설치하고 rtk --version 으로 검증한다.
훅 켜고 재시작
rtk init --claude-code 로 훅을 등록한 뒤 Claude Code를 재시작한다.
며칠 써본 뒤 실측
rtk gain 으로 본인 프로젝트의 명령별 절감률을 확인한다. 평균이 아니라 명령별 편차를 본다.
우회 보완
절감이 작으면 코드 탐색을 명시적 셸 명령이나 rtk 직접 호출로 돌리고, 인덱싱 도구를 함께 쓴다.
레이어 조합
출력 절감(RTK)에 더해 모델 교체로 단가를 낮추는 등 여러 레이어를 결합해 총비용을 관리한다.
자주 묻는 질문
RTK가 AI 추론 정확도나 코드 품질을 떨어뜨리나?
RTK는 무료인가, 한도가 있나?
토큰이 정말 60–90% 줄어드나?
Windows에서도 되나?
설치했는데 절약이 안 느껴진다, 왜 그런가?
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.
주제 태그

클로드 코드 토큰 절약하는 법, 코드 인덱싱 MCP 'CodeGraph' 총정리 (2026)
클로드 코드가 grep과 파일 읽기로 토큰을 낭비한다면? 코드베이스를 미리 그래프로 인덱싱하는 CodeGraph로 토큰·도구 호출을 줄이는 원리와 설치·사용법, 한계까지 정리했다.
읽기
클로드 코드 완전 정복: 설치, 가격, 활용법 총정리 (2026)
AI 코딩 도구 클로드 코드를 처음 접하는 사람을 위한 솔직한 리뷰. 설치법, 요금제, Cursor 비교, 장단점까지 한 글에 담았다.
읽기
클로드 코드 가격·한도 총정리: Pro·Max·Codex 비교
클로드 코드 가격과 한도를 2026년 5월 기준 공식 문서로 정리했다. Pro, Max, Codex 차이와 주의점을 중립적으로 비교한다.
읽기