클로드 코드 토큰 절약하는 법, 코드 인덱싱 MCP 'CodeGraph' 총정리 (2026)
클로드 코드가 grep과 파일 읽기로 토큰을 낭비한다면? 코드베이스를 미리 그래프로 인덱싱하는 CodeGraph로 토큰·도구 호출을 줄이는 원리와 설치·사용법, 한계까지 정리했다.

빠른 결론
먼저 이렇게 보면 됩니다
약 44분 읽기한 줄 판단
클로드 코드가 grep과 파일 읽기로 토큰을 낭비한다면? 코드베이스를 미리 그래프로 인덱싱하는 CodeGraph로 토큰·도구 호출을 줄이는 원리와 설치·사용법, 한계까지 정리했다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- 클로드 코드 · 토큰 절약 · 코드 인덱싱
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- 클로드 코드가 코드를 찾을 때 grep·glob·파일 읽기로 컨텍스트를 채우면서 토큰을 태운다면, CodeGraph는 코드베이스를 미리 그래프로 인덱싱해 한 번의 쿼리로 답을 돌려주는 로컬 MCP 서버다 — 여러 접근 중 하나일 뿐 정답은 아니다.
- 개발자 자체 보고 벤치마크 기준 7개 repo 평균 토큰 약 57%·도구 호출 약 62% 감소지만, 공개 하니스가 없어 제3자 재현은 불가능하고 소형 repo에서는 절감이 13%까지 떨어진다(출처: CodeGraph README).
- 대형·멀티언어 코드베이스에서 토큰 비용이 부담되고 100% 로컬·결정론적 구조 질의를 원한다면 시험해볼 만하다. 다만 아직 v0.9.x 버전이라는 점은 감안하자.
목차
- 클로드 코드는 왜 코드 탐색에서 토큰을 그렇게 많이 쓸까?
- CodeGraph는 grep과 뭐가 다른가? — 사전 인덱싱 코드 지식 그래프란?
- CodeGraph는 어떻게 작동하나? — Tree-sitter·SQLite·MCP 3계층
- 정말 토큰·도구 호출이 줄어드나? — 벤치마크와 그 한계
- 어떻게 설치하고 클로드 코드·커서에 연결하나?
- MCP 도구로 에이전트는 실제로 무엇을 호출하나?
- Serena·커서 인덱싱·graphify와 비교하면 언제 CodeGraph를 쓰나?
- 어떤 프로젝트에 효과가 크고, 언제는 굳이 필요 없나?
- FAQ: CodeGraph에 대해 자주 묻는 질문
- 결론: 지금 기억할 한 줄
1. 클로드 코드는 왜 코드 탐색에서 토큰을 그렇게 많이 쓸까?
클로드 코드(Claude Code)로 어느 정도 규모가 있는 프로젝트를 다뤄봤다면, “왜 질문 하나에 토큰이 이렇게 빨리 닳지?” 하는 순간을 겪었을 것이다. 그 비용의 상당 부분은 모델이 답을 쓰는 단계가 아니라 코드를 찾는 단계에서 발생한다. 이 섹션은 그 구조적 원인을 먼저 짚는다.
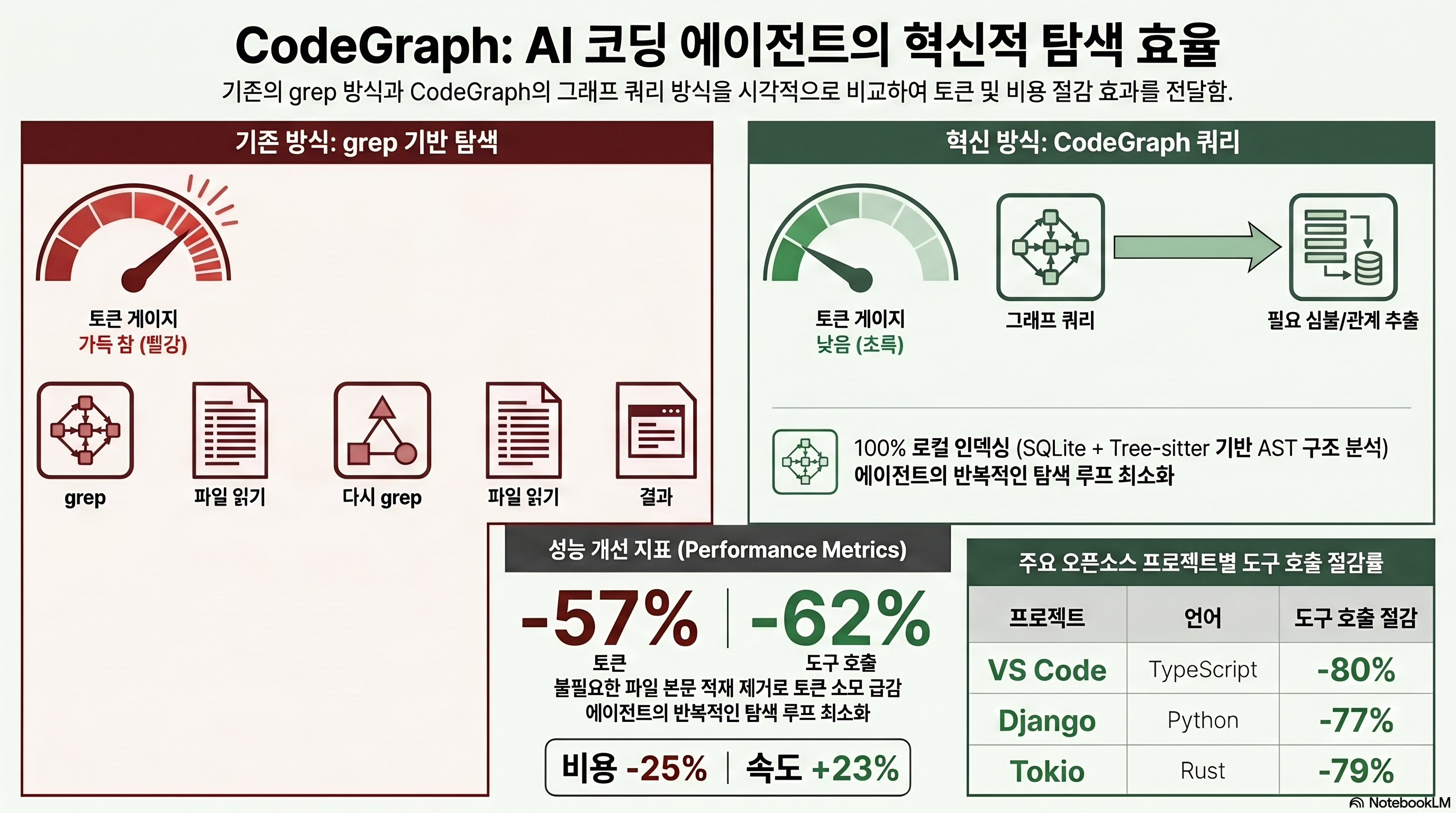
grep → 파일 읽기 → 다시 grep, 도구 호출의 왕복
에이전트형 코딩 도구의 기본 탐색 루프는 단순하다. 사용자가 “이 인증 미들웨어가 어디서 호출되지?”라고 물으면, 에이전트는 grep으로 후보 파일을 찾고, 그중 몇 개를 통째로 읽고, 거기서 발견한 다른 심볼을 다시 grep하는 식으로 코드베이스를 더듬는다. 이 과정에서 읽은 파일의 본문 전체가 컨텍스트 창에 들어간다. 함수 하나를 확인하려고 800줄짜리 파일을 통째로 읽으면, 실제로 필요한 20줄을 위해 나머지 780줄의 토큰까지 지불하는 셈이다.
문제는 이 루프가 한 번에 끝나지 않는다는 점이다. 콜그래프(call graph) 추적처럼 “A를 호출하는 곳 → 그 호출부를 포함한 파일 → 그 파일이 import하는 다른 모듈”로 이어지는 질문은 grep·읽기 왕복이 누적되며 도구 호출 횟수와 토큰을 동시에 끌어올린다.
컨텍스트 창은 유한하고, 토큰은 곧 비용이다
컨텍스트 창이 아무리 커져도 무한하지 않고, 입력 토큰은 그대로 청구액으로 환산된다. 대형 코드베이스를 탐색하다 보면 관련 없는 파일 내용이 컨텍스트를 잠식해 정작 중요한 맥락이 밀려나거나, 긴 세션에서 컨텍스트 한도에 부딪혀 대화를 새로 시작해야 하는 일도 생긴다. 토큰을 아끼는 일이 곧 비용 절감이자 답변 품질 유지로 직결되는 이유다. 만약 Claude Code·Codex의 사용 한도가 빠듯하다면, 탐색 단계에서 새는 토큰을 막는 것은 한도를 늘리는 것만큼이나 현실적인 대응이다.
”검색을 매번 다시 하는” 비효율, 어디서 줄일 수 있나
핵심 통찰은 이것이다. 코드베이스의 구조 — 어떤 함수가 어떤 함수를 부르고, 어떤 클래스가 무엇을 상속하며, 어떤 파일이 무엇을 import하는지 — 는 질문할 때마다 달라지지 않는다. 그런데 기본 탐색 방식은 매 질문마다 이 구조를 텍스트 매칭으로 처음부터 재발견한다. “한 번 분석해 두고 재사용하면 되지 않나?”라는 발상이 바로 코드 인덱싱이고, CodeGraph는 그 발상을 코딩 에이전트에 붙인 도구다.
이 블로그는 자체 작업에 graphify 기반 지식 그래프를 쓴다. 그래서 CodeGraph를 “코드 탐색의 정답”이 아니라 같은 문제를 푸는 여러 접근 중 하나로 다룬다. 벤치마크 수치는 모두 출처와 측정 조건, 그리고 한계를 함께 표기한다.
2. CodeGraph는 grep과 뭐가 다른가? — 사전 인덱싱 코드 지식 그래프란?
CodeGraph(GitHub: colbymchenry/codegraph)는 클로드 코드, 커서(Cursor), Codex CLI, opencode, Gemini CLI, Kiro 같은 AI 코딩 에이전트용으로 만들어진 “사전 인덱싱 코드 지식 그래프(pre-indexed code knowledge graph)” MCP 서버다. 이 섹션은 grep과의 근본적 차이를 정의한다.
텍스트 패턴 매칭 vs 구조 그래프 쿼리
grep은 텍스트 패턴을 찾는다. getUser라는 문자열이 들어간 줄을 전부 돌려주지만, 그게 함수 정의인지 호출인지 주석인지 변수명인지 구분하지 못한다. 반면 CodeGraph는 코드를 심볼(함수·클래스·메서드)을 노드로, 관계(호출·임포트·상속)를 엣지로 갖는 그래프, 즉 구조 그래프로 미리 변환해 둔다. 그래서 “getUser를 호출하는 모든 곳”이나 “이 클래스가 상속하는 부모”처럼 구조를 직접 물을 수 있다. 텍스트 일치가 아니라 코드의 의미적 관계를 쿼리하는 것이다.
핵심 차별점은 결정론(determinism)이다. CodeGraph 공식 문서는 이렇게 못 박는다.
Extraction is deterministic — derived from the AST, never LLM-summarized.
즉 그래프에 들어가는 정보는 추상 구문 트리(AST, Abstract Syntax Tree)에서 기계적으로 추출되며, LLM이 요약하거나 추측한 내용이 아니다. 같은 코드를 넣으면 같은 그래프가 나오고, 환각(hallucination)이 끼어들 여지가 구조적으로 적다.
”미리 인덱싱한다”는 발상 — 사전 컴파일된 지식
CodeGraph의 발상은 검색 시점에 매번 계산하지 말고 미리 한 번 계산해 두고 쿼리만 하자는 것이다. 이는 클로드 코드 같은 도구에만 국한된 흐름이 아니다. 검색 시점 임베딩 대신 사전 구조화된 지식을 모델에 주입하려는 시도는 여러 곳에서 나타난다. 예컨대 RAG 이후 패턴을 정리한 Karpathy의 LLM 위키 흐름도 “검색을 그때그때 하지 말고 지식을 미리 컴파일해 두자”는 같은 줄기에 있다. CodeGraph는 이 발상을 코드라는 도메인에 특화한 구현이다.
100% 로컬, MIT 라이선스 — 스택과 정체성
CodeGraph는 TypeScript로 작성됐고(언어 비중 약 91.7%), Node.js로 번들된다. 인덱스는 외부로 전송되지 않고 100% 로컬에서 처리된다. API 키도, 클라우드 업로드도 없다(출처: CodeGraph README). 라이선스는 MIT다. 코드가 외부 서버로 나가는 것을 꺼리는 보안 민감 환경에서, 데이터 전송이 없다는 점은 도구 선택의 결정적 기준이 되기도 한다.
3. CodeGraph는 어떻게 작동하나? — Tree-sitter·SQLite·MCP 3계층
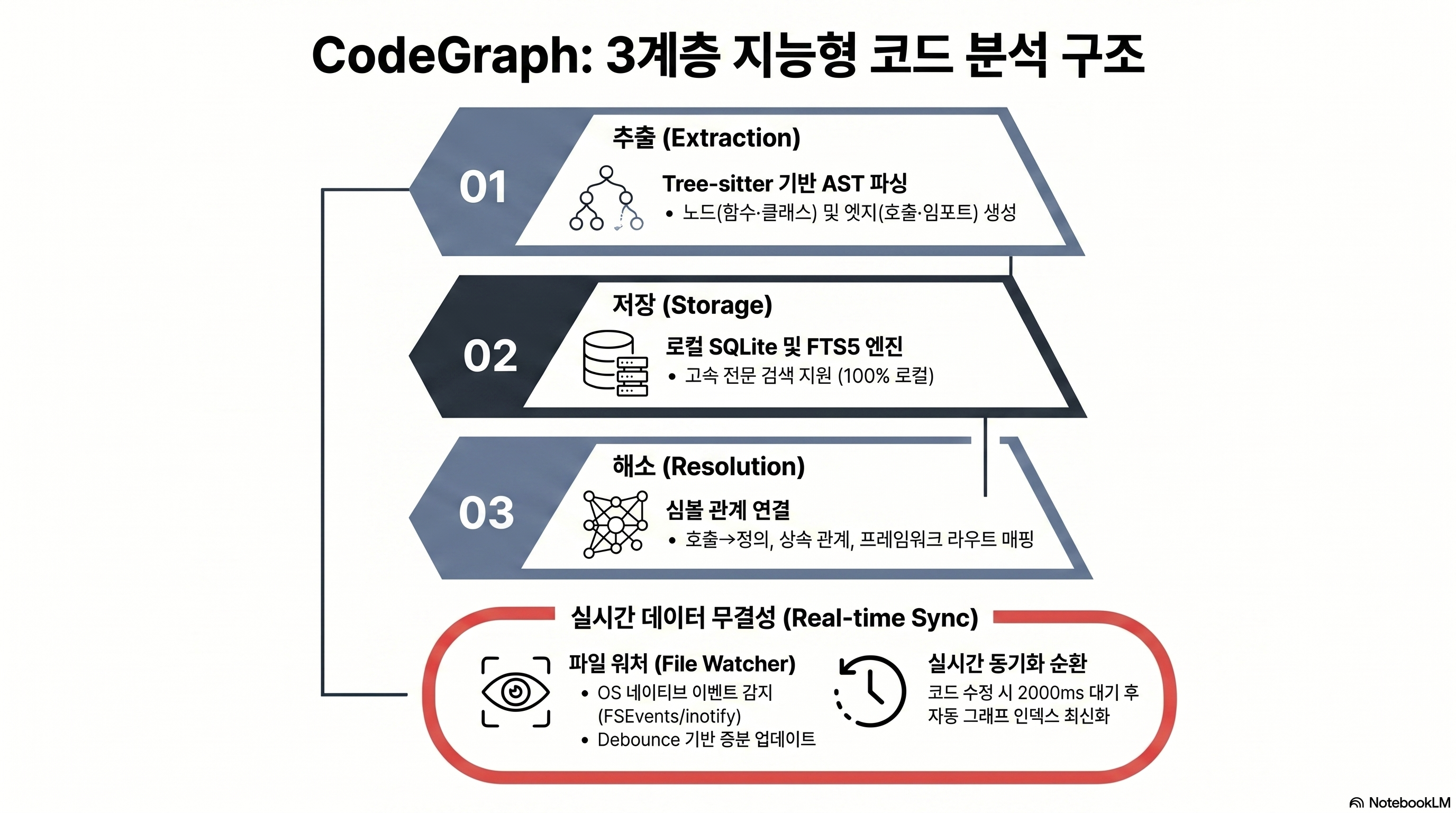
CodeGraph의 동작은 추출, 저장, 해소의 3계층에 자동 동기화가 더해진 구조로 이해하면 깔끔하다. 이 섹션은 각 계층이 무슨 일을 하는지 분해한다. 같은 “벡터 없이 미리 구조화한다”는 발상을 문서 쪽에서 시도한 사례로는 같은 벡터리스 접근을 문서 쪽에서 시도한 PageIndex가 있어, 코드가 아닌 텍스트 도메인의 대조군으로 참고할 만하다.
1계층 — 추출: Tree-sitter가 코드를 AST로 읽는다
CodeGraph는 Tree-sitter로 소스 코드를 파싱해 AST로 만들고, 언어별 쿼리를 적용해 노드(함수·클래스·메서드)와 엣지(호출·임포트·상속)를 뽑아낸다. Tree-sitter는 공식 표 기준 약 23개 언어를 지원한다 — TypeScript, JavaScript, Python, Go, Rust, Java, C#, PHP, Ruby, C, C++, Objective-C, Swift, Kotlin, Dart, Lua, Luau, Svelte, Liquid, Scala, Vue, Pascal 등이다(출처: CodeGraph README). 이 추출 단계가 앞서 강조한 “결정론적”의 실체로, AST에서 기계적으로 도출되므로 LLM 요약이 끼어들지 않는다.
2계층 — 저장: 로컬 SQLite + FTS5
추출된 그래프는 프로젝트 안의 로컬 SQLite 데이터베이스(.codegraph/codegraph.db)에 저장된다. 여기에 FTS5(Full Text Search 5, SQLite의 전문 검색 확장)가 결합돼 심볼과 코드 텍스트를 빠르게 검색한다. 별도 DB 서버나 벡터 스토어를 띄울 필요 없이, 파일 하나로 인덱스가 관리되는 셈이다. 클라우드 의존이 없다는 점도 이 저장 방식에서 나온다.
3계층 — 해소: 호출을 정의에 연결한다
추출만으로는 “이 줄에서 save()를 부른다”까지만 알 수 있다. 해소(resolution) 단계는 그 호출을 실제 정의로, import를 실제 파일로, 자식 클래스를 부모 클래스로 연결한다. 또한 CodeGraph는 프레임워크 라우트를 인식한다 — Django, Flask, FastAPI, Express, NestJS, Laravel, Rails, Spring, Gin, Axum, ASP.NET 등이다. 크로스언어 브리징도 처리해, Swift와 Objective-C, React Native TurboModules, Expo가 얽힌 코드의 경계를 이어준다(출처: CodeGraph README). 예를 들어 FastAPI 프로젝트에서 “/users 엔드포인트가 어떤 함수에 연결되나”를 라우트 인식 덕에 바로 답할 수 있다.
자동 동기화 — 파일을 고치면 그래프도 따라온다
인덱스가 한 번 만들고 끝이면 코드가 바뀔 때마다 낡은 그래프를 보게 된다. CodeGraph는 네이티브 OS 파일 이벤트(macOS FSEvents, Linux inotify, Windows ReadDirectoryChangesW)로 변경을 감지해, debounce된 증분 동기화로 바뀐 부분만 다시 인덱싱한다. v0.9.5부터는 여러 에이전트가 백그라운드 데몬 하나를 공유하도록 바뀌어, 같은 프로젝트를 여러 도구로 열어도 데몬이 중복으로 뜨지 않는다(출처: CodeGraph GitHub).
4. 정말 토큰·도구 호출이 줄어드나? — 벤치마크와 그 한계
여기가 가장 중요하면서도 가장 조심해야 할 섹션이다. CodeGraph가 내세우는 수치는 인상적이지만, 어디까지나 개발자가 직접 측정해 공개한 자체 보고치이며 한계가 분명하다. 수치와 한계를 한 화면에서 같이 본다.
측정 방법과 공식 평균치
README에 기재된 측정법은 다음과 같다. 7개 오픈소스 코드베이스(7개 언어)에서 claude -p(Claude Opus 4.8) headless 모드로 아키텍처 질문 1개를 던지되, CodeGraph를 켠 경우와 끈 경우를 비교한다. 각 조건당 4회 실행해 중앙값(median)을 취했고, 2026년 5월 29일 재검증됐다. 공식 평균은 약 25% 저렴, 토큰 약 57% 감소, 도구 호출 약 62% 감소, 약 23% 빠름 수준이다(출처: CodeGraph README).
| 지표 | CodeGraph 사용 시 평균 효과 | 성격 |
|---|---|---|
| 비용 | 약 25% 저렴 | 7개 repo median |
| 토큰 사용량 | 약 57% 감소 | 7개 repo median |
| 도구 호출 횟수 | 약 62% 감소 | 7개 repo median |
| 응답 속도 | 약 23% 빠름 | 7개 repo median |
repo별 편차 — 그래프로 보는 도구 호출 절감
평균만 보면 오해하기 쉽다. 절감 폭은 코드베이스 규모에 따라 크게 갈린다. 아래는 repo별 도구 호출 절감률이다. 대형 repo(VS Code, Django, Tokio)에서는 70–80%대지만, 100파일대 소형 repo로 가면 급격히 떨어진다.
벤치마크 그래프
repo별 도구 호출 절감률 (CodeGraph 사용 시)
개발자 자체 보고치 · 7개 오픈소스 repo · claude -p (Opus 4.8) median · 공개 하니스 없음
(출처: CodeGraph README, github.com/colbymchenry/codegraph · 자체 보고치, 제3자 재현 불가)
한계 — 자체 보고치이고, 공개 하니스가 없다
수치 옆에 반드시 둬야 할 사실이 셋이다.
첫째, 소형 repo에서 효과가 미미하다. CodeGraph 공식 문서도 이를 인정한다.
The cost margin is narrowest on the smallest repos, where a modern model’s native search is already cheap.
즉 작은 코드베이스에서는 최신 모델의 기본 검색만으로도 이미 충분히 싸기 때문에 절감 여지가 적다. 실제로 Alamofire(Swift, 약 110파일)의 도구 호출 절감은 13%에 그친다.
둘째, 공개 벤치마크 하니스와 raw 데이터가 공개돼 있지 않다. 측정법은 설명돼 있지만 제3자가 같은 조건으로 돌려 재현할 수 있는 스크립트·로그는 제공되지 않는다. 따라서 위 수치는 검증된 독립 벤치마크가 아니라 개발자 자체 보고치로 받아들여야 한다.
셋째, 외부 후기와도 편차가 있다. 한 실무자의 Medium 후기는 4개 repo 자체 측정으로 도구 호출 70% 감소, 토큰 59% 감소, 49% 빠름을 주장하며 “Zero Read calls. One query to a local graph.”라고 표현했다(출처: Medium 실무자 후기). 공식치와 방향은 같지만 수치는 다르고, 이 역시 통제된 실험이 아닌 개인 블로그 측정이다. 측정 조건에 따라 결과가 흔들린다는 근거로만 읽는 것이 안전하다.
“토큰 57% 절감”은 모든 프로젝트에서 보장되는 수치가 아니다. 7개 repo median이며, 소형 repo에서는 13%까지 떨어진다. 공개 하니스가 없어 제3자 재현이 불가능하므로, 자기 코드베이스에서 직접 켜고 끈 차이를 측정해 판단하는 것이 가장 정확하다.
5. 어떻게 설치하고 클로드 코드·커서에 연결하나?
설치는 한 줄짜리 스크립트나 npm으로 끝나고, 인덱싱 후 MCP 서버를 띄워 에이전트에 물리는 흐름이다. 이 섹션의 명령은 그대로 복붙해 쓰는 실제 명령이다.
설치 — 스크립트 또는 npm
macOS/Linux는 설치 스크립트 한 줄이면 된다.
curl -fsSL https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.sh | shWindows는 PowerShell에서 다음을 실행한다.
irm https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.ps1 | iexnpm 환경이 익숙하다면 글로벌 설치나 npx 실행도 가능하다.
npm install -g @colbymchenry/codegraph
# 또는 설치 없이 일회성 실행
npx @colbymchenry/codegraph참고로 npm 월 다운로드는 약 104,000회(@colbymchenry/codegraph) 수준으로, 스타뿐 아니라 실사용도 늘고 있다(출처: npm).
초기화와 인덱싱
프로젝트 루트에서 초기화 후 전체 인덱싱을 한 번 돌린다. init -i는 대화형 초기화이고, index가 코드베이스 전체를 그래프로 만든다.
codegraph init -i # 대화형 초기화
codegraph index # 전체 인덱싱 (최초 1회)
codegraph status # 인덱스 통계 확인이후 코드가 바뀌면 파일워처가 증분 동기화를 자동 수행하지만, 수동으로 맞추고 싶을 때는 codegraph sync로 증분 동기화를 강제할 수 있다.
MCP 서버 연결 — 클로드 코드·커서
에이전트에 물리려면 MCP 서버 모드로 띄운다.
codegraph serve --mcp그다음 에이전트의 MCP 설정에 CodeGraph 서버를 등록한다. 클로드 코드·커서 등 대부분의 클라이언트가 따르는 표준 MCP 설정 형식은 아래와 같다.
{
"mcpServers": {
"codegraph": {
"command": "codegraph",
"args": ["serve", "--mcp"]
}
}
}클로드 코드를 처음 다뤄본다면 클로드 코드 입문 정리에서 기본 사용법을 먼저 익힌 뒤 MCP 연결로 넘어오는 편이 수월하다.
설치
macOS/Linux는 install.sh 스크립트, Windows는 install.ps1, 또는 npm i -g @colbymchenry/codegraph로 설치한다.
초기화·인덱싱
프로젝트 루트에서 codegraph init -i 후 codegraph index로 전체 그래프를 만들고, codegraph status로 통계를 확인한다.
MCP 서버 실행
codegraph serve --mcp로 MCP 서버 모드를 띄운다.
에이전트 연결
클로드 코드·커서의 MCP 설정에 codegraph 서버를 등록하면 에이전트가 그래프를 쿼리하기 시작한다.
자동 동기화 확인
코드를 수정하면 파일워처가 증분 sync를 수행한다. 필요 시 codegraph sync로 수동 동기화한다.
대규모 인덱싱 중 Node 22/24에서 메모리 부족(OOM)이 보고된 적이 있다(이슈 #293, v0.9.3에서 해결). 또 Windows에서는 파일워처 데몬이 저장할 때마다 콘솔창을 깜빡이게 해 편집을 방해하는 문제가 있었다(이슈 #510/#485, v0.9.7에서 수정). 대형 프로젝트나 Windows 환경이라면 최신 버전(v0.9.7 이상)을 설치하자.
6. MCP 도구로 에이전트는 실제로 무엇을 호출하나?
CLI 명령과 별개로, 에이전트가 자동으로 부르는 것은 CodeGraph가 노출하는 MCP 도구들이다. 이 도구들이 grep 왕복을 한 번의 그래프 쿼리로 대체하는 실체다. 이 섹션은 에이전트가 무엇을 호출하는지 구체적으로 본다.
한 번의 호출로 컨텍스트를 받는다 — codegraph_context
가장 핵심적인 도구는 codegraph_context다. 진입점 심볼을 주면 관련 심볼들과 코드 스니펫을 한 번에 묶어 돌려준다. 앞서 본 “grep → 읽기 → 다시 grep”의 다단계 왕복이 단일 호출로 압축되는 지점이다. 예를 들어 “이 결제 핸들러의 맥락을 보여줘”라는 요청에서, 에이전트는 파일 여러 개를 통째로 읽는 대신 codegraph_context 한 번으로 필요한 함수 정의와 호출 관계만 받아온다.
검색·추적·관계 도구
나머지 도구는 구조 질의를 세분화한다.
| MCP 도구 | 하는 일 | 대체하는 기존 동작 |
|---|---|---|
| codegraph_search | FTS 기반 심볼·코드 검색 | 여러 번의 grep |
| codegraph_context | 진입점 + 관련 심볼 + 스니펫을 한 번에 | grep 후 파일 다중 읽기 |
| codegraph_callers / codegraph_callees | 특정 심볼의 호출부·피호출부 | 콜그래프 수동 추적 |
| codegraph_trace | 심볼 간 호출 경로 추적 | 파일 넘나드는 반복 읽기 |
| codegraph_impact | 변경 시 영향받는 범위 분석 | 전체 grep 후 추정 |
| codegraph_node / codegraph_explore / codegraph_files / codegraph_status | 노드 상세·탐색·파일 목록·인덱스 상태 | 디렉터리 나열 + 읽기 |
실사용 시나리오 — 리팩터링 영향 분석
codegraph_impact는 리팩터링 전에 특히 유용하다. 예를 들어 공용 유틸 함수의 시그니처를 바꾸려 할 때, “이 함수를 바꾸면 어디가 깨지나?”를 grep으로 일일이 찾는 대신 codegraph_impact로 영향받는 호출부를 그래프에서 한 번에 받는다. CLI에도 대응 명령이 있어, 사람이 직접 codegraph callers <symbol>이나 codegraph impact <symbol>을 터미널에서 실행해 확인할 수도 있다.
기존 방식은 답을 찾기 위해 파일 본문을 컨텍스트에 잔뜩 적재한다. CodeGraph는 그래프에서 필요한 심볼·관계·스니펫만 추려 돌려주므로, 컨텍스트에 들어가는 불필요한 코드 본문이 줄고 그만큼 입력 토큰이 절약된다. 단, 그 절감 폭은 4번 섹션에서 봤듯 코드베이스 규모에 따라 다르다.
7. Serena·커서 인덱싱·graphify와 비교하면 언제 CodeGraph를 쓰나?
CodeGraph는 코드 이해를 돕는 유일한 도구가 아니다. 접근 방식이 다른 대안들과 나란히 놓고 봐야 어떤 상황에 무엇을 쓸지가 보인다. 이 섹션은 1차 소스 기준으로 중립 비교한다.
Serena — LSP 기반, 편집까지 한다
Serena MCP(oraios/serena, GitHub 스타 약 24,800개)는 언어 서버 프로토콜(LSP, Language Server Protocol)을 기반으로 심볼 단위 의미 검색을 하고, 검색을 넘어 코드 편집·리팩터링까지 수행한다. 40개 이상 언어를 지원한다. 다만 언어별 언어 서버를 구동해야 하므로 셋업이 무겁고, “읽기 전용으로 가볍게 구조만 질의”하려는 목적과는 결이 다르다(출처: Serena GitHub).
커서 코드베이스 인덱싱 — 임베딩, 단 클라우드
커서의 코드베이스 인덱싱은 파일을 청크로 쪼개 임베딩 벡터로 만든 뒤 클라우드 벡터 DB(Turbopuffer)에 저장하고, Merkle 트리로 증분 갱신한다. 의미적으로 유사한 코드를 찾는 데 강하다. 하지만 코드 데이터가 외부로 전송되며 커서 생태계에 종속된다(출처: Cursor 보안 문서). 데이터가 로컬을 떠나면 안 되는 환경에서는 이 점이 곧 탈락 사유가 된다.
graphify·ctags·grep — 범용과 최소
코드·문서를 지식 그래프로 묶는 Graphify는 코드에 한정되지 않고 문서·논문·이미지까지 포함해 범용 지식 그래프를 만든다. 반면 CodeGraph는 코딩 에이전트를 위한 코드 전용 사전 인덱싱에 특화돼 있다. 둘은 경쟁이라기보다 “범용 그래프 대 코딩 에이전트 전용 그래프”라는 다른 층위의 도구로 보는 편이 맞다. 더 단순한 쪽으로는 ctags(심볼 인덱스만 제공)와 grep(텍스트 패턴 매칭, 구조 인식 없음)이 있다.
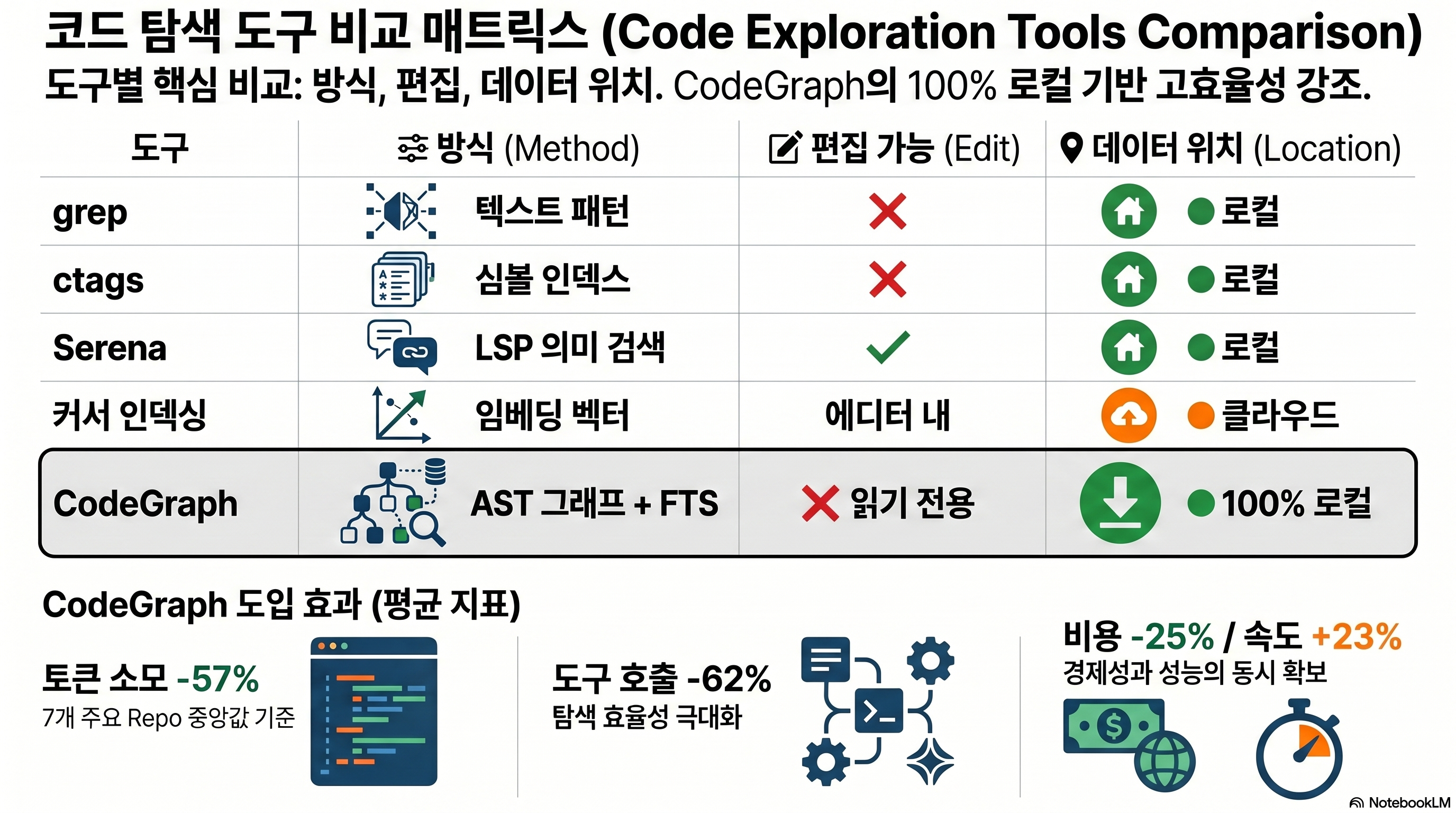
| 도구 | 방식 | 편집 기능 | 데이터 위치 | 강점 / 적합 상황 |
|---|---|---|---|---|
| grep | 텍스트 패턴 매칭 | 없음 | 로컬 | 즉시 사용·구조 무관 단순 검색 |
| ctags | 심볼 인덱스 | 없음 | 로컬 | 가벼운 심볼 점프 |
| Serena | LSP 의미 검색 | 있음 (리팩터링) | 로컬(언어서버 구동) | 편집까지 필요할 때·40+ 언어 |
| 커서 인덱싱 | 임베딩 벡터 검색 | 에디터 내 | 클라우드(Turbopuffer) | 의미적 유사 검색·커서 사용자 |
| CodeGraph | AST 구조 그래프 + FTS | 없음 (읽기/질의) | 로컬 | 결정론적 구조 질의·토큰 절감·대형 repo |
정리 — 상황별 선택 기준
의미적으로 모호한 검색이나 코드 편집까지 필요하면 Serena나 커서가 낫다. 코드 데이터를 외부로 보내지 않으면서 결정론적 구조 질의로 토큰을 줄이는 것이 목표라면 CodeGraph가 맞는다. 그리고 대형·멀티언어 repo일수록 CodeGraph 효과가 크고, 소형 repo에서는 굳이 도입할 실익이 작다.
8. 어떤 프로젝트에 효과가 크고, 언제는 굳이 필요 없나?
도구를 도입할지 말지는 “좋은가”가 아니라 “내 상황에 맞는가”로 판단해야 한다. 이 섹션은 효과가 큰 경우와 그렇지 않은 경우를 가른다.
효과가 큰 경우 — 대형·멀티언어·토큰 비용 부담
수만 파일급 코드베이스, 여러 언어가 섞인 모노레포, 그리고 클로드 코드 헤비 유저로서 토큰 비용이 실제로 부담되는 상황이라면 CodeGraph의 절감 효과가 크게 나타날 가능성이 높다. 4번의 벤치마크에서 VS Code(약 10k 파일)와 Django(약 3k 파일)의 도구 호출 절감이 77–80%였던 것이 이 경우다. 코드를 외부로 보낼 수 없는 보안 환경에서 100% 로컬·결정론적 질의가 필요한 팀에도 부합한다.
굳이 필요 없는 경우 — 소형 repo·이미 충분한 환경
100파일 안팎의 작은 프로젝트라면 최신 모델의 기본 검색만으로도 비용이 이미 낮아, 인덱싱·데몬을 유지하는 부담 대비 절감이 미미하다(Alamofire 기준 도구 호출 절감 13%). 의미적으로 모호한 자연어 검색이 주 용도이거나 코드 편집·리팩터링 자동화가 핵심이라면, 구조 질의 중심의 CodeGraph보다 Serena나 커서가 더 맞는다.
이런 분에게 추천한다
장점
- + 대형·멀티언어 코드베이스에서 토큰·도구 호출 절감 효과가 크다
- + 100% 로컬·결정론적 추출 — 코드 외부 전송이 없고 환각 여지가 적다
- + MIT 라이선스, 설치 한 줄, npm 월 약 104,000 다운로드로 실사용 증가
- + 주요 웹 프레임워크 라우트 인식·크로스언어 브리징 지원
단점
- − 벤치마크가 자체 보고치이고 공개 하니스가 없어 제3자 재현 불가
- − 소형 repo(약 110파일)에서는 절감이 13%까지 떨어져 실익이 적다
- − 아직 v0.9.x 버전 — OOM·Windows 파일워처 등 이슈가 릴리스마다 수정 중
- − 의미적 모호 검색·코드 편집은 CodeGraph의 영역이 아니다
이런 분에게 추천한다:
- 토큰·비용을 줄이려는 클로드 코드 헤비 유저: 대형 코드베이스 탐색에서 새는 입력 토큰을 그래프 쿼리로 줄일 수 있다.
- 컨텍스트 한계를 자주 체감하는 개발자: 불필요한 파일 본문 적재를 줄여 컨텍스트 여유를 확보한다.
- 보안·로컬을 선호하는 팀: 코드가 외부로 나가지 않는 100% 로컬 인덱싱이 기본이다.
커뮤니티 반향은 어떤가
수치상 성장은 가파르다. 저장소 생성일은 2026년 1월 18일로, 약 4.5개월 만에 GitHub 스타 약 34,856개(≈34.8k), 포크 2,138개, 오픈 이슈 204개를 기록했다(출처: CodeGraph GitHub, 2026-05-31 조회). 다만 토론형 커뮤니티 반향은 그에 비해 제한적이다. 해커뉴스(HN)에서는 CodeGraph 직접 스토리가 1포인트 수준에 그쳐 토론이 거의 형성되지 않았다. 스타·다운로드 같은 채택 지표는 폭발적이지만, 깊은 토론으로 검증된 단계는 아니라고 보는 편이 균형 잡힌 해석이다.
- "Zero Read calls. One query to a local graph. (4개 repo 자체 측정: 도구 호출 70%↓·토큰 59%↓·49% 빠름)" — Medium 실무자 후기 (개인 측정, 통제 실험 아님)
- "약 4.5개월 만에 GitHub 스타 약 34.8k, npm 월 약 104,000 다운로드 — 채택 지표 급성장" — GitHub·npm (2026-05-31 조회)
- "스타·다운로드에 비해 HN 등 토론형 커뮤니티 반향은 1포인트 수준으로 제한적" — Hacker News (직접 스토리 기준)
- "공개 벤치마크 하니스·raw 데이터 미공개 — 자체 보고치라 제3자 재현 불가" — CodeGraph README 측정 조건
9. FAQ: CodeGraph에 대해 자주 묻는 질문
CodeGraph를 처음 검토할 때 자주 나오는 질문을 모았다. 설치·비용·보안·대안까지 핵심만 짚는다.
도입 전 흔한 궁금증
아래 답변은 모두 2026년 5월 31일 기준 공식 저장소·문서를 근거로 한다. 버전이 v0.9.x이므로 세부 동작은 릴리스에 따라 바뀔 수 있다.
CodeGraph는 무료인가?
내 코드가 외부로 전송되나?
클로드 코드 말고 다른 에이전트에서도 쓰나?
정말 토큰이 57% 줄어드나?
코드를 수정하면 매번 다시 인덱싱해야 하나?
Serena와 무엇이 다른가?
어떤 언어를 지원하나?
프로덕션에 바로 써도 되나?
10. 결론: 지금 기억할 한 줄
CodeGraph는 클로드 코드 같은 에이전트가 코드를 찾을 때 새는 토큰을, 코드베이스를 미리 결정론적 그래프로 인덱싱해 줄이려는 시도다. 효과는 실재하지만 조건부이고, 도구는 아직 성숙 중이다.
핵심 요약
CodeGraph는 grep·파일 읽기 왕복을 한 번의 로컬 그래프 쿼리로 대체해 토큰·도구 호출을 줄이는 MCP 서버다. 자체 보고 기준 대형 repo에서 토큰 약 57%·도구 호출 약 62% 감소를 보이지만, 공개 하니스가 없어 재현은 불가하고 소형 repo에서는 절감이 13%까지 떨어진다. 코드 탐색의 여러 접근 중 하나로, 대형·멀티언어·로컬 보안 환경에 특히 맞는다.
- 대형·멀티언어 코드베이스의 클로드 코드 헤비 유저: 탐색 단계 토큰 절감 여지가 가장 크다.
- 코드 외부 전송이 금지된 팀: 100% 로컬·결정론적 인덱싱이 기본이라 데이터가 로컬을 떠나지 않는다.
- 소형 repo·편집 자동화가 주목적인 사용자: 절감 실익이 작거나 영역이 달라, 기본 검색이나 Serena가 더 맞을 수 있다.
직접 측정으로 시작
자기 코드베이스에서 CodeGraph를 켠 경우와 끈 경우의 토큰·도구 호출을 비교해 효과를 검증한다. 평균치를 그대로 믿지 않는다.
최신 버전 설치
OOM·Windows 파일워처 이슈가 수정된 v0.9.7 이상을 설치한다.
대안과 함께 검토
편집이 필요하면 Serena, 의미적 유사 검색이 핵심이면 커서 인덱싱, 범용 지식 그래프가 필요하면 graphify를 같이 저울질한다.
소규모 검증 후 확대
v0.9.x인 만큼 핵심 프로젝트에 전면 도입하기 전 작은 repo·브랜치에서 먼저 검증한다.
이 글이 도움이 됐나요?
한 번의 반응이 다음 글의 방향을 정해요.
주제 태그

클로드 코드 토큰 절약법, 60~90% 줄이는 rtk 사용법 (2026)
클로드 코드 토큰이 너무 빨리 닳는다면, 명령어 출력을 줄여 토큰을 60~90% 아끼는 RTK를 정리했다. 설치법부터 실제 절약 효과, 안전성과 한계, 대안 비교까지 한 글에 담았다.
읽기
클로드 코드 완전 정복: 설치, 가격, 활용법 총정리 (2026)
AI 코딩 도구 클로드 코드를 처음 접하는 사람을 위한 솔직한 리뷰. 설치법, 요금제, Cursor 비교, 장단점까지 한 글에 담았다.
읽기
Gemini 3.5 Flash 총정리: 가격·벤치마크·해외 반응
Gemini 3.5 Flash의 공식 스펙, 가격, 벤치마크, API 변경점과 해외 Reddit·Hacker News 반응을 정리한다.
읽기