Gemma 4 완전 정리: 벤치마크, 한국어 성능, 로컬 설치까지
구글 Gemma 4의 모델 구성, 벤치마크 성능, Llama 4·Qwen 3.5 비교, 한국어 실사용 후기, Ollama 로컬 설치법까지 한 글에 정리한다.

빠른 결론
먼저 이렇게 보면 됩니다
약 31분 읽기한 줄 판단
구글 Gemma 4의 모델 구성, 벤치마크 성능, Llama 4·Qwen 3.5 비교, 한국어 실사용 후기, Ollama 로컬 설치법까지 한 글에 정리한다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- Gemma 4 · 오픈소스 AI · 로컬 LLM
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- Gemma 4는 Apache 2.0 오픈소스로, 31B 모델이 AIME 2026 89.2%를 기록하며 400B급 상용 모델과 대등한 추론 성능을 보여준다
- 한국어 사용성 테스트에서 76.20점으로 오픈소스 1위, ChatGPT o3-mini(76.40)와 0.2점 차이로 상용 모델급 한국어를 구사한다
- Ollama 한 줄이면 로컬 설치가 가능하고 상업적 이용에 제한이 없으니, 이 글을 따라 직접 구동해보자
목차
- Gemma 4는 어떤 모델인가?
- 4종 모델 라인업, 어떤 걸 골라야 하나?
- 벤치마크 성능은 실제로 어떤가?
- Llama 4·Qwen 3.5와 비교하면 어떤가?
- 한국어 성능은 실제로 어떤 수준인가?
- Ollama로 로컬 설치하는 방법은?
- 실사용 시 주의할 점은 무엇인가?
- 커뮤니티 반응은 어떤가?
- 트러블슈팅 Q&A
- 결론: 누가, 어떤 모델을 써야 하는가?
Gemma 4는 어떤 모델인가?
구글 딥마인드의 차세대 오픈소스 전략
Gemma 4는 구글 딥마인드가 2026년 3월에 공개한 오픈소스 LLM 패밀리다. 이전 세대인 Gemma 3까지는 “Gemma 이용 약관”이라는 별도 라이선스를 적용했고, 월간 활성 사용자(MAU) 제한 등 상업적 이용에 걸림돌이 있었다. Gemma 4부터 Apache 2.0 라이선스로 전환하면서 MAU 제한도, 수익 상한도 완전히 사라졌다 (출처: Google Blog).
이 변화가 중요한 이유는 단순하다. 스타트업이든 대기업이든 Gemma 4를 제품에 내장해도 구글에 로열티를 낼 필요가 없다. Meta의 Llama 4도 자체 라이선스를 유지하는 상황에서, Gemma 4의 Apache 2.0 전환은 오픈소스 AI 생태계에서 명확한 차별점이다.
# Gemma 4 라이선스 확인 (Hugging Face)
from huggingface_hub import model_info
info = model_info("google/gemma-4-27b")
print(info.card_data.license) # apache-2.0PLE 아키텍처란 무엇인가?
Gemma 4의 핵심 기술은 PLE(Per-Layer Embeddings) 아키텍처다. 기존 트랜스포머는 입력 임베딩을 모든 디코더 레이어에서 동일하게 사용한다. PLE는 각 레이어마다 별도의 임베딩을 부여한다. 덕분에 E2B 모델은 활성 파라미터 2.3B에 불과하지만, 실제로는 5.1B급 표현력을 발휘한다 (출처: WaveSpeed AI).
쉽게 비유하면, 같은 크기의 뇌(파라미터)로 더 많은 “관점”을 동시에 처리하는 것이다. 레이어별 임베딩이 각기 다른 문맥 정보를 캡처하기 때문에, 작은 모델도 큰 모델처럼 동작할 수 있다.
# PLE 레이어별 임베딩 차원 확인 (pseudo-code)
from transformers import AutoModel
model = AutoModel.from_pretrained("google/gemma-4-e2b")
for i, layer in enumerate(model.layers):
print(f"Layer {i}: embed_dim={layer.embed.weight.shape}")네이티브 멀티모달 지원 범위
Gemma 4는 모든 모델이 텍스트 + 이미지 입력을 기본 지원한다. 가변 해상도(variable resolution) 이미지를 별도 전처리 없이 직접 넣을 수 있다. E2B와 E4B는 추가로 30초 오디오 입력을 지원하고, 26B와 31B 모델은 최대 60초 비디오 입력까지 처리한다 (출처: Google AI Dev).
⚠️ 주의: 멀티모달 입력은 현재 입력(이해) 방향만 지원한다. 이미지나 오디오를 생성하는 기능은 포함되어 있지 않다.
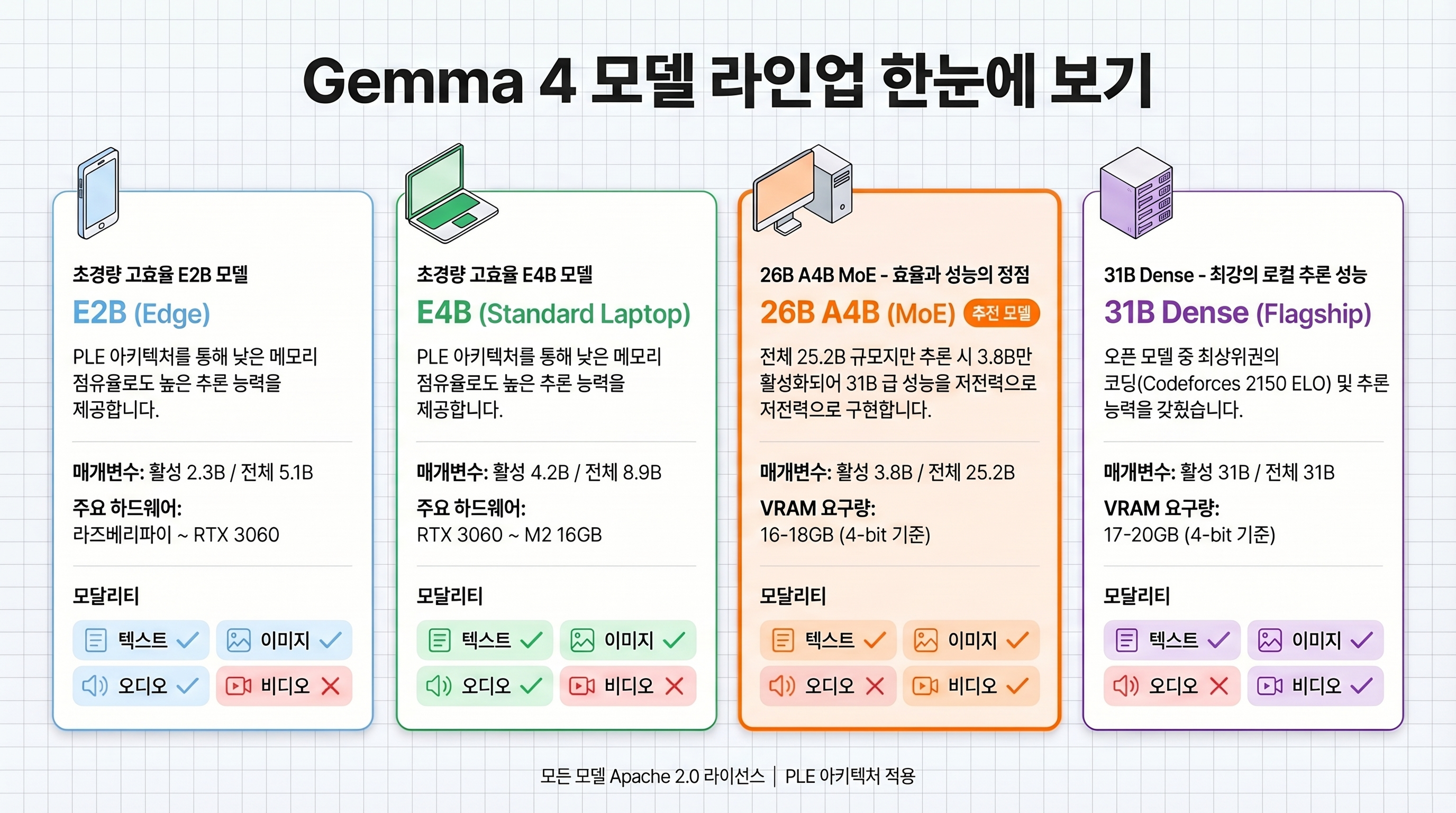
4종 모델 라인업, 어떤 걸 골라야 하나?
모델별 핵심 스펙 비교
Gemma 4 패밀리는 4가지 크기로 구성된다. 스마트폰부터 데이터센터 GPU까지, 실행 환경에 따라 선택지가 다르다 (출처: LM Studio).
| 항목 | E2B | E4B | 26B A4B (MoE) | 31B Dense |
|---|---|---|---|---|
| 전체 파라미터 | 5.1B | 8.9B | 25.2B | 31B |
| 활성 파라미터 | 2.3B | 4.2B | 3.8B | 31B |
| 아키텍처 | PLE Dense | PLE Dense | MoE + PLE | Dense |
| 이미지 입력 | 가변 해상도 | 가변 해상도 | 가변 해상도 | 가변 해상도 |
| 오디오 입력 | 30초 | 30초 | 미지원 | 미지원 |
| 비디오 입력 | 미지원 | 미지원 | 60초 | 60초 |
| 컨텍스트 | 128K | 128K | 128K | 256K |
| VRAM 요구 | 4GB | 6GB | 16~18GB | 17~20GB |
실행 환경별 권장 모델
GPU VRAM과 실행 환경에 따라 권장 모델이 달라진다.
| 실행 환경 | 권장 모델 | 이유 |
|---|---|---|
| 라즈베리파이 5 / 모바일 | E2B | 4GB VRAM, 133 tok/s prefill — IoT 엣지 추론에 적합 |
| 일반 노트북 (RTX 3060 / M2 16GB) | E4B | 6GB VRAM으로 코딩 보조, 문서 요약에 충분 |
| 개발 워크스테이션 (RTX 4090 / M2 Max) | 26B A4B | 4B급 속도로 26B급 품질 — 가성비 최고 |
| 서버 / 풀 성능 필요 | 31B Dense | AIME 89.2% — 연구, 복잡 추론에 최적 |
# 각 모델의 Ollama 다운로드 크기 확인
ollama show gemma4:e2b --modelfile | grep SIZE
# E2B: ~3.2GB (Q4_K_M)
ollama show gemma4:26b --modelfile | grep SIZE
# 26B A4B: ~15.1GB (Q4_K_M)MoE 구조가 주는 실질적 이점
26B A4B 모델이 특히 주목받는 이유는 MoE(Mixture of Experts) 구조 때문이다. 전체 파라미터는 25.2B이지만 한 번에 활성화되는 파라미터는 3.8B에 불과하다. 그래서 추론 속도는 4B급이면서 출력 품질은 26B급에 도달한다 (출처: WaveSpeed AI).
실제로 MMLU Pro에서 82.6%, AIME 2026에서 88.3%를 기록한다. 이는 31B Dense 모델(85.2%, 89.2%)과 큰 차이가 없으면서도, VRAM은 16~18GB로 RTX 4090 한 장에 올라간다.
벤치마크 성능은 실제로 어떤가?
추론 벤치마크: Gemma 3 대비 극적 향상
Gemma 4의 가장 두드러진 개선은 추론(reasoning) 성능이다. Thinking Mode(단계별 사고 과정)를 내장하면서, AIME 2026에서 31B가 89.2%를 달성했다. Gemma 3 27B의 20.8%와 비교하면 4배 이상 뛴 수치다 (출처: Google Blog).
| 벤치마크 | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 3 27B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 67.6% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 20.8% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 29.1% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 42.4% |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 19.3% |
| MMMU Pro (비전) | 76.9% | 73.8% | 52.6% | 49.7% |
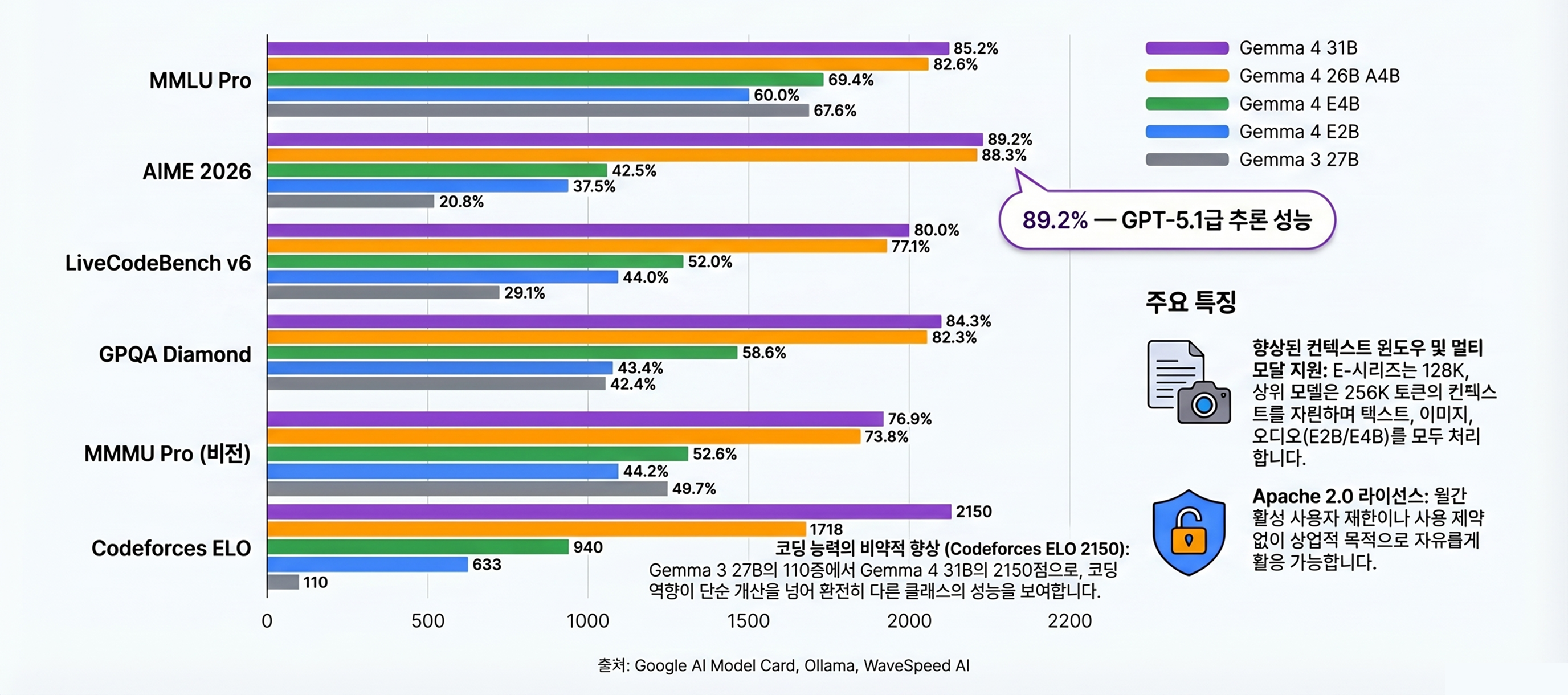
코딩 벤치마크: Codeforces ELO 2150
코딩 성능도 주목할 만하다. Gemma 4 31B는 Codeforces ELO 2150을 기록했다. 이는 인간 프로그래머 기준으로 “Expert~Candidate Master” 수준이다. Gemma 3 27B의 ELO 110(입문 수준)에서 대폭 상승했다.
# Gemma 4 31B로 코딩 문제 풀기 예시 (Thinking Mode)
import ollama
response = ollama.chat(
model="gemma4:31b",
messages=[{
"role": "user",
"content": "<start_of_turn>思考\n두 정수 배열의 교집합을 O(n) 시간에 구하는 함수를 작성하라.<end_of_turn>"
}],
)
print(response["message"]["content"])에이전트 워크플로우: 6%에서 86%로
Gemma 4가 도입한 또 하나의 변화는 네이티브 함수 호출(Function Calling)이다. 에이전트 벤치마크에서 Gemma 3의 6%가 Gemma 4에서 86%로 급등했다 (출처: CoderSera). JSON 출력 모드도 기본 지원하므로, 별도 파싱 없이 구조화된 응답을 받을 수 있다.
# Gemma 4 함수 호출 예시
import ollama
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "도시의 현재 날씨를 가져온다",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "도시 이름"}
},
"required": ["city"]
}
}
}]
response = ollama.chat(
model="gemma4:26b",
messages=[{"role": "user", "content": "서울 날씨 알려줘"}],
tools=tools
)
print(response["message"]["tool_calls"])Llama 4·Qwen 3.5와 비교하면 어떤가?
Llama 4 Scout(109B MoE)과의 비교
Llama 4 Scout은 전체 파라미터 109B, 활성 파라미터 17B의 대형 MoE 모델이다. 컨텍스트 윈도우가 10M 토큰으로 Gemma 4의 256K 대비 압도적이다. 하지만 VRAM 요구량이 64GB 이상이어서, 단일 GPU 로컬 실행은 사실상 불가능하다.
반면 Gemma 4 26B A4B는 16~18GB VRAM으로 RTX 4090 한 장에 올라간다. MMLU Pro에서 82.6%로 Llama 4 Scout의 80.1%를 오히려 앞서고, 코딩/추론 벤치마크에서도 우위를 보인다 (출처: CoderSera).
| 항목 | Gemma 4 26B A4B | Llama 4 Scout 109B | Qwen 3.5 27B |
|---|---|---|---|
| 활성 파라미터 | 3.8B | 17B | 27B (Dense) |
| VRAM 요구 | 16~18GB | 64GB+ | 18~20GB |
| MMLU Pro | 82.6% | 80.1% | 79.8% |
| 컨텍스트 윈도우 | 128K | 10M | 1M |
| 라이선스 | Apache 2.0 | Llama License | Apache 2.0 |
| 함수 호출 | 네이티브 지원 | 제한적 | 네이티브 지원 |
| 로컬 실행 난이도 | RTX 4090 1장 | A100 2장+ | RTX 4090 1장 |
Qwen 3.5 27B와의 실전 비교
Qwen 3.5 27B는 Dense 모델로 Gemma 4 26B A4B와 파라미터 규모가 비슷하다. 실제 비즈니스 태스크 18개를 테스트한 결과, Gemma 4가 13:5로 승리했다는 커뮤니티 보고가 있다 (출처: CoderSera). 하지만 Qwen 3.5는 1M 토큰 컨텍스트 윈도우라는 독보적 장점이 있어, 긴 문서 처리에서는 Qwen이 유리하다.
# Ollama에서 모델 크기 비교
ollama list | grep -E "gemma4|qwen3.5"
# gemma4:26b 15.1GB
# qwen3.5:27b 16.7GB상용 모델(GPT-5.1)과의 격차
GPT-5.1은 OpenAI의 최신 상용 모델이다. Gemma 4 31B는 MMLU Pro에서 85.2%로 GPT-5.1과 거의 동등한 수준이다. 하지만 SWE-bench(소프트웨어 엔지니어링 벤치마크)나 복잡한 멀티턴 대화에서는 여전히 GPT-5.1이 앞선다.
결정적 차이는 비용이다. GPT-5.1은 API 호출당 과금이 발생하지만, Gemma 4는 로컬 실행 시 추가 비용이 0이다. 월 API 비용이 수십만 원에 달하는 프로덕션 환경이라면, Gemma 4 로컬 배포가 합리적 대안이 된다.
한국어 성능은 실제로 어떤 수준인가?
오픈소스 모델 중 한국어 사용성 1위
위키독스의 ‘LLM 한국어 사용성 테스트’(22개 항목, 40점 만점)에서 Gemma 4(26B)는 76.20점으로 전체 16위, 오픈소스 모델 중 1위를 기록했다 (출처: 위키독스 LLM 한국어 사용성 순위). 같은 아키텍처의 Gemma 3 27B(71.71점, 20위)보다 4.5점 높고, Qwen3-32B(65.97점, 26위)를 10점 이상 앞서는 수치다.
| 모델 | 점수 | 순위 | 유형 |
|---|---|---|---|
| Gemini 3.0 Pro (Thinking) | 99.25 | 1위 | 상용 |
| ChatGPT 4.5 | 95.57 | 3위 | 상용 |
| Claude Sonnet 4 | 88.65 | 4위 | 상용 |
| ChatGPT o3-mini | 76.40 | 14위 | 상용 |
| Gemma 4 (26B) | 76.20 | 16위 | 오픈소스 1위 |
| Gemma 3 27B (Q4_K_M) | 71.71 | 20위 | 오픈소스 |
| CLOVA X | 70.51 | 23위 | 상용 (한국어 특화) |
| Qwen3-32B | 65.97 | 26위 | 오픈소스 |
| Llama 3 8B | 22.89 | 60위 | 오픈소스 |
주목할 점은 Gemma 4가 ChatGPT o3-mini(76.40점)와 0.2점 차이라는 것이다. 오픈소스 26B 모델이 OpenAI의 경량 추론 모델과 동급 한국어 성능을 보인다. 또한 한국어 특화 모델인 CLOVA X(70.51점)를 5.7점 앞선다는 점도 의미가 크다. 물론 최상위 상용 모델(Gemini 3.0 Pro 99.25점, ChatGPT 4.5 95.57점)과는 아직 20점 이상 격차가 있다.
22개 항목 상세 테스트 결과
평가는 한국어 기본 능력부터 문학 분석, 방언 번역, 코딩까지 총 22개 항목으로 구성된다. Gemma 4는 대부분의 항목에서 “우수” 평가를 받았다 (출처: 위키독스 Gemma 4 상세 결과).
| 영역 | 테스트 항목 | 평가 |
|---|---|---|
| 기본 한국어 | 한국어 대화, 정체성 인식 | 우수 |
| 창작 | 삼행시·오행시 작성 | 우수 — 문학적 표현력 |
| 언어 게임 | 끝말잇기 참여 | 우수 |
| 번역 | 영한 번역, 문맥별 다중 번역 | 우수 |
| 방언 | 부산 사투리 해석 | 우수 — 정확한 방언 인식 |
| 문학 분석 | 한용운 '님의 침묵' 해석 | 우수 — 깊이 있는 분석 |
| 문서 이해 | 6가 혼합백신 정책 분석 | 우수 |
| 격식체 변환 | 비즈니스·공식·뉴스레터 스타일 | 우수 |
| 텍스트 교정 | 3가지 스타일 제안 | 우수 |
| 지명·특산물 | 영덕 대게 등 지역 지식 | 우수 |
| 코딩 | 유니코드 한글 처리, 수학 문제 | 우수 |
| 날짜·실시간 | 현재 날짜, 실시간 정보 | 제한적 — 오프라인 모델 한계 |
⚠️ 주의: “날짜 인식”과 “실시간 정보” 항목에서 낮은 점수를 받았다. 이는 Gemma 4가 인터넷 연결 없는 로컬 모델이기 때문이며, 모든 오프라인 LLM에 해당하는 구조적 한계다. 한국어 능력 자체의 문제는 아니다.
오픈소스 한국어 모델 계보에서의 위치
Gemma 4의 한국어 76.20점이 의미하는 바를 정리하면:
- 로컬 실행 가능한 모델 중 최고 수준이다. RTX 4090 한 장으로 상용 서비스급 한국어 품질을 확보할 수 있다.
- Gemma 3 대비 명확한 개선이다. 같은 양자화(Q4_K_M) 기준 4.5점 상승했고, 더 높은 양자화에서는 격차가 더 벌어질 수 있다.
- 한국어 특화 모델(CLOVA X 70.51점)을 앞선다. 범용 오픈소스 모델이 한국어 전용 상용 모델을 넘어선 것은 주목할 만하다.
다만 프롬프트 없이 사용하면 영어로 응답하거나 한국어 품질이 떨어질 수 있다. 아래 트러블슈팅 섹션에서 한국어 품질을 높이는 시스템 프롬프트 설정법을 확인하자.
Ollama로 로컬 설치하는 방법은?
Ollama 설치와 모델 다운로드
Gemma 4를 로컬에서 가장 쉽게 실행하는 방법은 Ollama를 사용하는 것이다. macOS, Linux, Windows 모두 지원한다 (출처: Ollama).
Ollama 설치
공식 사이트(ollama.com)에서 OS에 맞는 설치 파일을 받아 설치한다. macOS는 dmg, Linux는 curl 스크립트를 지원한다.
Gemma 4 모델 다운로드
터미널에서 ollama pull gemma4:26b 명령을 실행한다. 26B 모델 기준 약 15GB를 다운로드한다.
모델 실행 확인
ollama run gemma4:26b 명령으로 대화형 세션을 시작한다. 첫 응답까지 10-30초 정도 걸릴 수 있다.
API 서버 활용
Ollama는 기본적으로 localhost:11434에 REST API를 제공한다. curl 명령이나 Python SDK로 프로그래밍 방식 호출이 가능하다.
# 1. Ollama 설치 (Linux)
curl -fsSL https://ollama.com/install.sh | sh
# 2. Gemma 4 모델 다운로드
ollama pull gemma4:26b
# 3. 대화형 실행
ollama run gemma4:26bPython에서 Ollama API 호출하기
Ollama의 Python SDK를 사용하면 몇 줄로 Gemma 4를 호출할 수 있다. 프롬프트 엔지니어링 기초에서 다루는 역할 지정, 출력 형식 고정, 예시 기반 지시를 함께 활용하면 더 좋은 결과를 얻을 수 있다.
# pip install ollama
import ollama
response = ollama.chat(
model="gemma4:26b",
messages=[
{"role": "system", "content": "너는 한국어 기술 블로그 어시스턴트다."},
{"role": "user", "content": "Python GIL이 뭔지 3줄로 설명해줘"}
]
)
print(response["message"]["content"])# 스트리밍 응답으로 체감 속도 높이기
import ollama
stream = ollama.chat(
model="gemma4:26b",
messages=[{"role": "user", "content": "FastAPI vs Flask 비교해줘"}],
stream=True
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)LM Studio로 GUI 기반 실행하기
CLI가 익숙하지 않다면 LM Studio를 추천한다. GUI에서 모델을 검색하고 다운로드한 뒤, 채팅 인터페이스로 바로 대화할 수 있다 (출처: LM Studio). 자세한 로컬 설치 흐름은 별도 가이드에서 다룰 예정이다.
# LM Studio CLI로 모델 다운로드 (베타 기능)
lms get google/gemma-4-26b-it-GGUF
lms server start실사용 시 주의할 점은 무엇인가?
양자화 민감도 문제
Gemma 4는 양자화(quantization)에 민감한 편이다. 특히 Q4 이하로 과도하게 양자화하면 성능이 급격히 떨어진다. Reddit r/LocalLLM에서 “26B MoE Q4 양자화 버전은 최악”이라는 보고가 다수 나왔다.
권장하는 양자화 수준은 다음과 같다.
| 양자화 레벨 | VRAM 사용량 (26B) | 성능 유지율 | 권장 여부 |
|---|---|---|---|
| FP16 (원본) | ~32GB | 100% | VRAM 충분 시 최선 |
| Q8_0 | ~25GB | ~98% | 권장 — 성능 손실 미미 |
| Q5_K_M | ~18GB | ~95% | 권장 — 대부분 사용자 최적 |
| Q4_K_M | ~15GB | ~88% | 주의 — MoE 모델에서 성능 저하 가능 |
| Q3_K | ~12GB | ~70% | 비권장 — 심각한 품질 저하 |
# Q5_K_M 양자화 모델 다운로드 (Ollama)
ollama pull gemma4:26b-q5_K_M
# 양자화 레벨별 응답 품질 간이 테스트
ollama run gemma4:26b-q5_K_M "대한민국 수도는?"
ollama run gemma4:26b-q4_K_M "대한민국 수도는?"MoE 모델(26B A4B)은 Expert 라우팅 가중치가 양자화에 취약하다. Q4_K_M 이하에서는 라우팅 정확도가 떨어져 전체 성능이 급락할 수 있다. VRAM이 부족하면 26B Q4보다 E4B FP16을 선택하는 것이 더 나은 결과를 줄 수 있다.
컨텍스트 윈도우 제한
Gemma 4의 최대 컨텍스트 윈도우는 31B Dense 기준 256K 토큰이다. 한국어 기준으로 약 12만~15만 자에 해당한다. 일반적 용도에는 충분하지만, 긴 코드베이스 분석이나 대량 문서 처리에서는 한계가 있다.
비교하면 Llama 4 Scout은 10M 토큰, Qwen 3.6은 1M 토큰을 지원한다. 긴 컨텍스트가 필수인 워크로드(코드베이스 전체 분석, 논문 다수 동시 비교 등)에서는 Gemma 4가 불리하다.
# 컨텍스트 윈도우 한계 확인
import ollama
# 31B 모델의 컨텍스트 길이 설정
response = ollama.chat(
model="gemma4:31b",
messages=[{"role": "user", "content": "이 텍스트를 요약해줘: " + long_text}],
options={"num_ctx": 131072} # 128K 토큰 설정
)도구 호출 초기 버그와 안정성
Gemma 4의 함수 호출 기능은 벤치마크상 86%로 크게 개선되었지만, 실전에서는 아직 버그 보고가 존재한다. 특히 이미지와 함수 호출을 동시에 사용할 때 인식 거부 현상이 보고되었고, safety 필터가 과도하게 작동하는 경우도 있다.
⚠️ 주의: 프로덕션에서 Gemma 4의 도구 호출을 사용한다면, 반드시 폴백(fallback) 로직을 구현하라. 도구 호출 실패 시 텍스트 기반 파싱으로 전환하는 방어 코드가 필요하다.
# 도구 호출 폴백 패턴
import json
import ollama
def safe_tool_call(prompt, tools):
response = ollama.chat(
model="gemma4:26b",
messages=[{"role": "user", "content": prompt}],
tools=tools
)
msg = response["message"]
# 도구 호출 성공 시
if msg.get("tool_calls"):
return msg["tool_calls"]
# 폴백: 텍스트에서 JSON 파싱 시도
try:
return json.loads(msg["content"])
except json.JSONDecodeError:
return {"error": "도구 호출 및 파싱 실패", "raw": msg["content"]}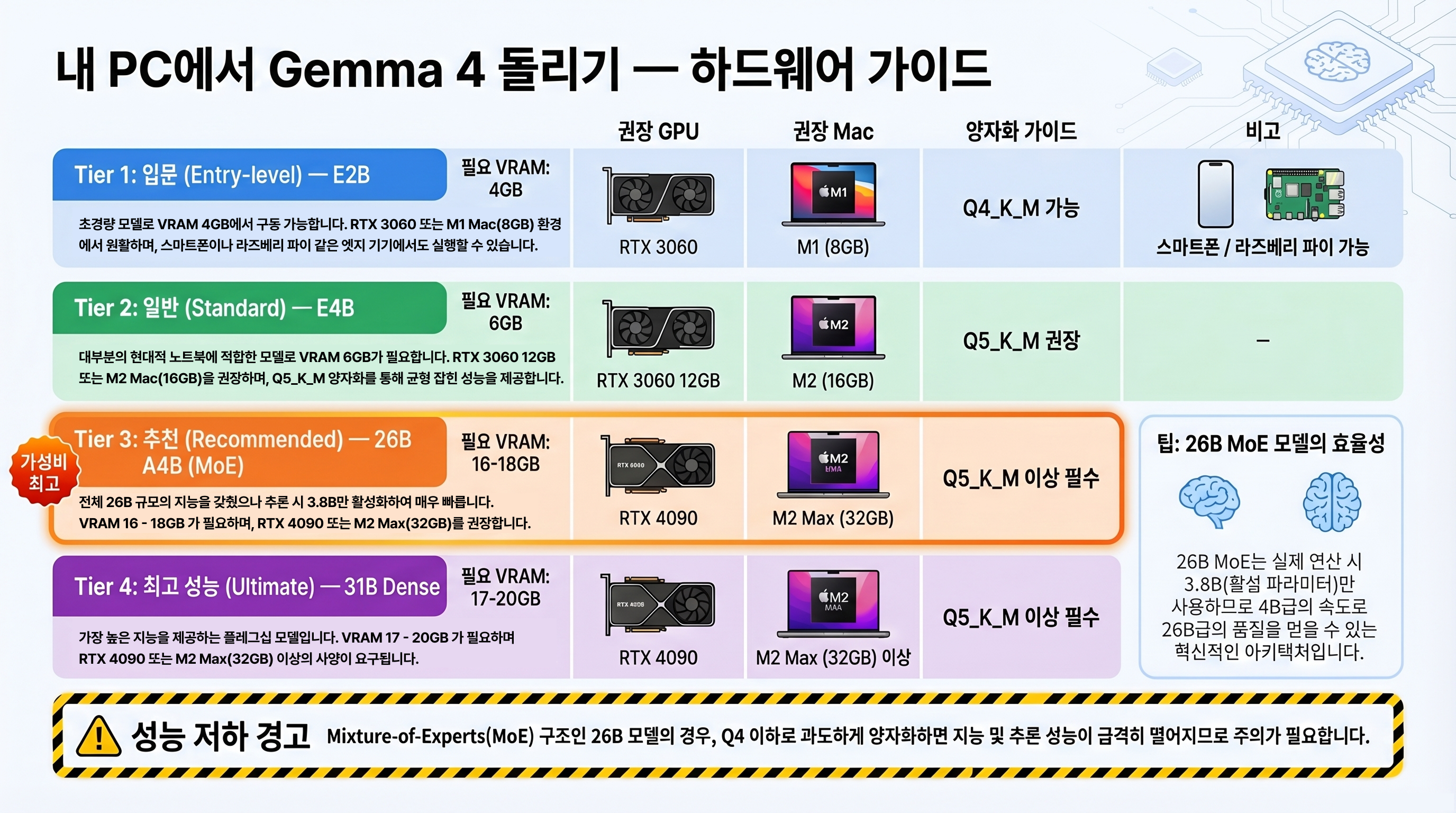
커뮤니티 반응은 어떤가?
Reddit·GitHub에서 나온 실사용 평가
Gemma 4 출시 이후 Reddit r/LocalLLaMA, r/LocalLLM, r/ollama 등에서 활발한 토론이 이어지고 있다. 전반적으로 벤치마크 성능에 대한 찬사와, 실전 안정성에 대한 우려가 공존한다.
- "31B로 단일 GPU에서 GPT-5.1급 벤치마크를 찍는다" — r/LocalLLM
- "모든 리더보드에서 Opus 4.6과 GPT-5.2 빼고 다 이긴다" — r/LocalLLaMA (1.8K upvotes)
- "26B로 Qwen 3.5 27B 상대 18개 비즈니스 테스트 13:5 승리" — r/ollama
- "26B MoE Q4 양자화 버전은 성능이 기대 이하다" — r/LocalLLM
- "벤치마크 점수와 실사용 체감이 다르다는 걸 보여주는 모델" — r/LocalLLaMA
- "도구 호출 첫 시도에서 이미지 인식을 거부했다" — r/LocalLLM
핵심 시사점
커뮤니티 피드백에서 도출되는 핵심은 세 가지다.
- 양자화는 Q5_K_M 이상으로 유지하라. MoE 모델은 특히 양자화 민감도가 높다.
- 도구 호출은 검증 후 배포하라. 벤치마크 86%라고 해서 실전에서 무조건 동작하지는 않는다.
- 벤치마크 ≠ 체감 성능이다. 특히 개방형(open-ended) 창의적 작업에서는 벤치마크 수치 대비 체감이 떨어진다는 보고가 있다.
트러블슈팅 Q&A
Ollama에서 모델 로드 실패 시
Ollama로 Gemma 4를 실행할 때 가장 흔한 문제는 VRAM 부족이다. Error: model requires more system memory 메시지가 뜨면, 양자화 레벨을 낮추거나 더 작은 모델을 선택해야 한다.
# VRAM 사용량 실시간 확인 (NVIDIA GPU)
nvidia-smi --query-gpu=memory.used,memory.total --format=csv -l 1
# VRAM 부족 시 해결: 더 작은 양자화 모델 사용
ollama pull gemma4:26b-q4_K_M # 15GB → VRAM 18GB GPU에서 실행 가능
ollama pull gemma4:e4b # VRAM 6GB면 충분한국어 응답 품질이 낮을 때
Gemma 4는 영어 중심으로 학습되었기 때문에, 시스템 프롬프트에 한국어 응답을 명시하지 않으면 영어로 답변하거나 한국어 품질이 떨어질 수 있다. ChatGPT, Claude, Gemini 계열을 비교해 보면 모델마다 한국어 성능 차이가 뚜렷하다.
# 한국어 응답 품질 높이는 시스템 프롬프트
system_prompt = """당신은 한국어 전문 AI 어시스턴트입니다.
규칙:
1. 반드시 한국어로 답변한다
2. 전문 용어는 영문 병기한다 (예: 양자화(Quantization))
3. ~다/~한다 서술체를 사용한다"""
response = ollama.chat(
model="gemma4:26b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "트랜스포머 어텐션 메커니즘을 설명해줘"}
]
)추론 중단 현상 해결
복잡한 프롬프트에서 Gemma 4가 추론을 중간에 멈추는 현상이 보고되었다. 이 경우 num_predict 옵션으로 최대 출력 토큰을 늘리거나, 프롬프트를 단계별로 분할하면 해결되는 경우가 많다.
# 추론 중단 방지: 최대 출력 토큰 설정
response = ollama.chat(
model="gemma4:31b",
messages=[{"role": "user", "content": complex_prompt}],
options={
"num_predict": 8192, # 기본값(2048)보다 높게 설정
"temperature": 0.7, # 너무 낮으면 반복 루프에 빠질 수 있다
}
)결론: 누가, 어떤 모델을 써야 하는가?
장점
- + Apache 2.0 — MAU·수익 제한 없는 완전 자유 라이선스
- + 26B MoE로 4B급 속도에 26B급 품질 달성
- + AIME 2026 89.2% — 31B 단일 GPU로 상용 모델급 추론
- + E2B가 라즈베리파이에서 7.6 tok/s로 구동
- + 에이전트 벤치마크 6%→86%로 도구 호출 대폭 개선
단점
- − 컨텍스트 윈도우 최대 256K — Llama 4(10M), Qwen 3.6(1M) 대비 짧다
- − Q4 이하 양자화 시 MoE 모델 성능 급락
- − 도구 호출 + 이미지 동시 사용 시 안정성 미흡
- − 개방형 창의적 작업에서 벤치마크 대비 체감 저하
- − 한국어 76.20점(오픈소스 1위)이지만 상위 상용 모델(99점대)과는 격차 존재
핵심 요약
Gemma 4는 Apache 2.0 라이선스의 오픈소스 LLM으로, 31B 파라미터 모델이 AIME 2026 89.2%, MMLU Pro 85.2%를 기록하며 GPT-5.1급 추론 성능을 단일 GPU에서 실현했다. 26B MoE 모델은 3.8B 활성 파라미터로 26B급 품질을 달성해 가성비 면에서 현 시점 최고 수준이다.
- 로컬 코딩 어시스턴트가 필요한 개발자: 26B A4B + Ollama로 Codeforces 1718 ELO급 코딩 보조를 무료로 구축할 수 있다
- 저사양 기기에서 AI를 구동하려는 IoT/임베디드 개발자: E2B가 라즈베리파이 5에서 7.6 tok/s로 동작한다
- API 비용 없이 상업 제품을 만들고 싶은 스타트업: Apache 2.0이므로 로열티 없이 제품에 내장 가능하다
- 데이터 프라이버시를 유지하며 AI를 활용하려는 기업: 로컬 실행으로 데이터가 외부 서버로 나가지 않는다
- 오픈소스 AI 동향을 팔로우하는 AI 팔로워: Gemma 4는 2026년 상반기 오픈소스 LLM 벤치마크의 새 기준점이다
Ollama로 모델 설치
Gemma 4 로컬 설치 가이드를 따라 ollama run gemma4 명령으로 시작한다
모델과 양자화 레벨 선택
GPU VRAM에 맞는 모델을 고른다. 16GB 이상이면 26B A4B, 6GB 이하면 E4B 또는 E2B
한국어 시스템 프롬프트 설정
Modelfile에 한국어 응답 규칙을 명시해야 안정적인 한국어 출력을 얻을 수 있다
도구 호출 폴백 로직 구현
프로덕션에서 함수 호출을 쓴다면 실패 시 텍스트 파싱으로 전환하는 방어 코드가 필수다
양자화 품질 검증
Q5_K_M 이상을 유지하고 Q4 이하는 반드시 벤치마크 후 판단한다. MoE 모델은 특히 민감하다
Gemma 4와 Gemma 3의 가장 큰 차이는 무엇인가?
Gemma 4를 상업적으로 자유롭게 사용할 수 있는가?
GPU 없이 Gemma 4를 실행할 수 있는가?
Gemma 4 26B와 31B 중 어떤 모델이 더 나은가?
Gemma 4의 한국어 성능은 어떤 수준인가?
Ollama 외에 다른 실행 방법이 있는가?

맥북 로컬 AI 서버 끝판왕? Rapid-MLX 설치·성능·Ollama 비교
Rapid-MLX가 무엇인지, 맥북에서 어떻게 설치해 쓰는지, Ollama·LM Studio와 비교하면 무엇이 다른지 최신 기준으로 정리한다.
읽기
RTX 4090에서 직접 돌려본 로컬 코딩 에이전트 후기 — Qwen 3.6 27B (2026)
RTX 4090과 Mac M4 Max에서 직접 돌려본 로컬 코딩 에이전트 후기. SWE-bench 77%·1M 컨텍스트·Apache 2.0 오픈소스 모델 Qwen 3.6 27B의 설치, VRAM, Claude 대비 실력을 정리했다.
읽기
GPT-5.5 총정리: 성능·벤치마크·가격·반응 (2026)
GPT-5.5의 출시일, 성능, 벤치마크, API 가격, Codex 변화, 커뮤니티 반응을 2026년 4월 기준으로 정리했다.
읽기