벡터리스 RAG란? PageIndex가 진짜 RAG 대안일까
PageIndex가 왜 벡터 DB와 청킹 없이 긴 문서를 찾는다고 말하는지, 가격·MCP·FinanceBench·한계를 2026년 5월 기준으로 정리한다.

빠른 결론
먼저 이렇게 보면 됩니다
약 31분 읽기한 줄 판단
PageIndex가 왜 벡터 DB와 청킹 없이 긴 문서를 찾는다고 말하는지, 가격·MCP·FinanceBench·한계를 2026년 5월 기준으로 정리한다.
- 읽을 사람
- 도구를 고르기 전에 비용과 한계를 확인하려는 독자
- 확인 기준
- PageIndex · 벡터리스 RAG · RAG 대안
- 주의할 점
- 가격과 기능은 바뀔 수 있습니다. 공식 안내도 함께 확인하세요.
3줄 요약
- PageIndex는 “벡터 DB를 버린 만능 RAG”라기보다, 긴 구조화 문서를 트리 인덱스로 읽게 만드는 reasoning-first 문서 검색 도구에 가깝다.
- 2026년 5월 7일 기준 GitHub 별 29,161개, MIT 라이선스, MCP/API/Chat 표면까지 갖춘 빠르게 성장 중인 프로젝트지만, 98.7% FinanceBench는 벤더 소유 평가 위에 놓인 숫자라는 점을 같이 봐야 한다.
- 가장 현실적인 읽는 법은 “기존 vector RAG를 완전히 대체할 도구”보다 “긴 PDF와 cross-reference가 많은 문서에서 정확도를 올릴 수 있는 하이브리드 후보”다.
목차
- PageIndex는 정확히 무엇인가?
- 벡터 DB 없이 정말 검색이 되나?
- self-host와 cloud/API는 무엇이 다른가?
- 가격은 얼마나 들까?
- 98.7% FinanceBench는 어디까지 믿어야 하나?
- vector RAG·GraphRAG·LLM 위키와 무엇이 다른가?
- MCP로 붙이면 어떤 워크플로가 되나?
- 설치는 정말 쉬운가?
- 어떤 문서에 잘 맞고 어떤 경우엔 안 맞나?
- FAQ: PageIndex에 대해 자주 묻는 질문
- 결론: 지금 PageIndex를 써볼 만한가?
짧게 결론부터 말하면 PageIndex는 “RAG는 다 끝났다”를 증명한 도구가 아니다. 대신 긴 재무 보고서, 규정집, 기술 매뉴얼처럼 구조가 곧 의미인 문서에서 vector similarity가 자주 놓치는 구간을 tree search와 LLM reasoning으로 보완하는 도구에 더 가깝다. 2026년 5월 7일 기준 이 레포는 빠르게 성장 중이고 가격표도 공개돼 있지만, open-source self-host 경로와 managed cloud 경로를 섞어 읽으면 과장이 심해진다. 이 글은 그 경계를 분리해서 본다.
PageIndex는 정확히 무엇인가?
한 줄로 말하면 PageIndex는 긴 문서를 청크로 잘라 벡터 검색하는 대신, 문서의 계층 구조를 JSON 트리로 만든 뒤 LLM이 그 트리를 탐색하도록 설계한 retrieval 도구다. 공식 소개도 “vectorless, reasoning-based RAG”라는 문구를 앞세우지만, 실제로는 “트리 인덱스를 만들고 그 위를 reasoning으로 걷는 문서 검색 엔진”으로 이해하는 편이 더 정확하다 (출처: PageIndex GitHub, PageIndex introduction).
오픈소스 레포와 관리형 서비스는 같은 제품이 아니다
여기서 첫 번째 오해가 생긴다. GitHub 레포는 로컬에서 PDF나 Markdown을 트리 구조로 바꿔 쓰는 오픈소스 self-host 경로이고, 공식 docs의 Getting Started는 개발자 대시보드와 API 키를 전제로 하는 managed cloud 경로를 안내한다 (출처: PageIndex GitHub, Getting Started).
즉 “PageIndex를 써본다”는 말 안에는 사실 두 제품 표면이 겹쳐 있다.
- 레포를 clone해서 로컬 문서를 직접 인덱싱하는 오픈소스 경로
- 문서를 업로드하고 MCP나 Chat API로 붙이는 관리형 경로
이 차이를 분리하지 않으면 “설치가 쉽다”나 “바로 MCP에 붙는다” 같은 문장이 전부 반쯤만 맞게 된다.
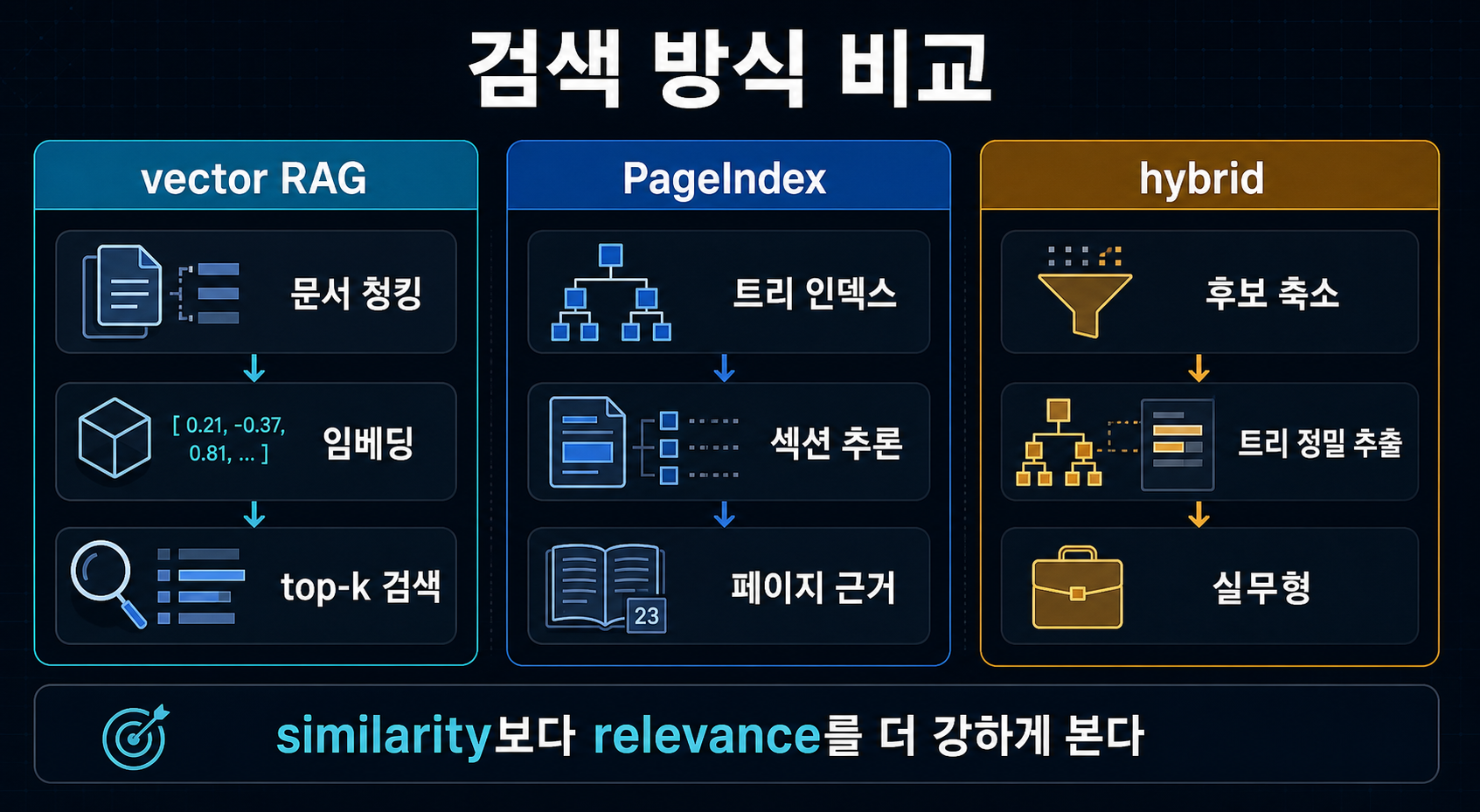
핵심은 벡터 검색이 아니라 트리 탐색이다
PageIndex가 기존 vector RAG와 갈라지는 지점은 retrieval unit이다. 일반적인 vector RAG는 문서를 고정 길이 chunk로 잘라 embedding을 만들고, 쿼리와 비슷한 조각을 top-k로 가져온다. 반면 PageIndex는 문서를 목차 같은 트리로 바꾸고, 모델이 “이 질문이면 어느 가지를 더 열어봐야 하나?”를 추론하면서 내려간다 (출처: PageIndex introduction, Thoughtworks Radar).
이 차이는 특히 “Appendix G를 보라”, “표 5.3을 참고하라” 같은 cross-reference가 많은 문서에서 의미가 크다. 의미상 비슷한 chunk를 찾는 것과, 문서 구조상 다음에 어디를 열어야 하는지를 판단하는 것은 완전히 다른 문제이기 때문이다.
2026년 5월 7일 기준 레포 상태는 어떨까?
현재 확인되는 공개 신호는 꽤 강하다. GitHub API 기준 VectifyAI/PageIndex는 2025년 4월 1일 생성된 공개 Python 레포이고, 2026년 5월 7일 기준 별 29,161개, 포크 2,472개를 기록하고 있다. 라이선스는 MIT다. 다만 GitHub Releases API는 비어 있어서, 문서와 블로그 갱신 속도에 비해 버전 릴리스 기록은 분명하지 않다 (출처: PageIndex GitHub).
이건 좋은 신호와 경고 신호가 같이 있다는 뜻이다. 성장세는 빠르지만, 운영 안정성과 배포 히스토리를 릴리스 태그로 추적하기는 아직 어렵다.
벡터 DB 없이 정말 검색이 되나?
된다. 다만 여기서 말하는 “검색”은 cosine similarity로 가장 비슷한 chunk를 뽑는 검색이 아니라, 문서 구조를 따라 reasoning으로 내려가는 탐색에 가깝다.
similarity와 relevance를 분리해서 본다
PageIndex 쪽 주장의 핵심 문장은 “similarity는 relevance가 아니다”다. 이 문장은 과장처럼 들리지만, 재무 보고서나 법률 문서처럼 반복 문구가 많은 곳에서는 실제로 꽤 설득력이 있다. 의미상 비슷한 문단이 수십 개라면, 가장 비슷한 chunk가 아니라 “이번 질문에서 진짜 필요한 위치”를 골라야 하기 때문이다 (출처: PageIndex introduction, Adaptive Query Routing).
트리 구조가 cross-reference에 강한 이유
PageIndex가 잘 먹히는 대표 사례는 문서 내부 참조다. 본문에서 숫자를 바로 주지 않고 “Appendix G”나 “표 5.3”을 가리키는 구간은 vector RAG가 자주 놓친다. 반대로 트리 탐색은 “지금 보고 있는 절이 충분하지 않다”는 판단을 한 뒤 다른 섹션으로 이동할 수 있다. 이게 PageIndex가 강조하는 human-like retrieval의 실체다 (출처: PageIndex introduction).
그래도 모든 검색 문제를 해결하는 건 아니다
여기서 한 발 물러서야 한다. Thoughtworks는 2026년 4월 15일 Radar에서 PageIndex를 Assess로 올리면서도, 이 접근이 LLM inference를 retrieval 안에 넣기 때문에 latency와 cost를 키운다고 명시했다 (출처: Thoughtworks Radar).
또 2026년 4월 공개된 Adaptive Query Routing 논문은 tree reasoning이 FinanceBench에서는 vector RAG보다 높았지만, 모든 질문 유형에서 단일 패러다임이 이기는 것은 아니며 hybrid가 일부 질의군에서 더 낫다고 보고했다 (출처: Adaptive Query Routing). 즉 “벡터리스가 무조건 우위”라는 식으로 읽으면 곤란하다.
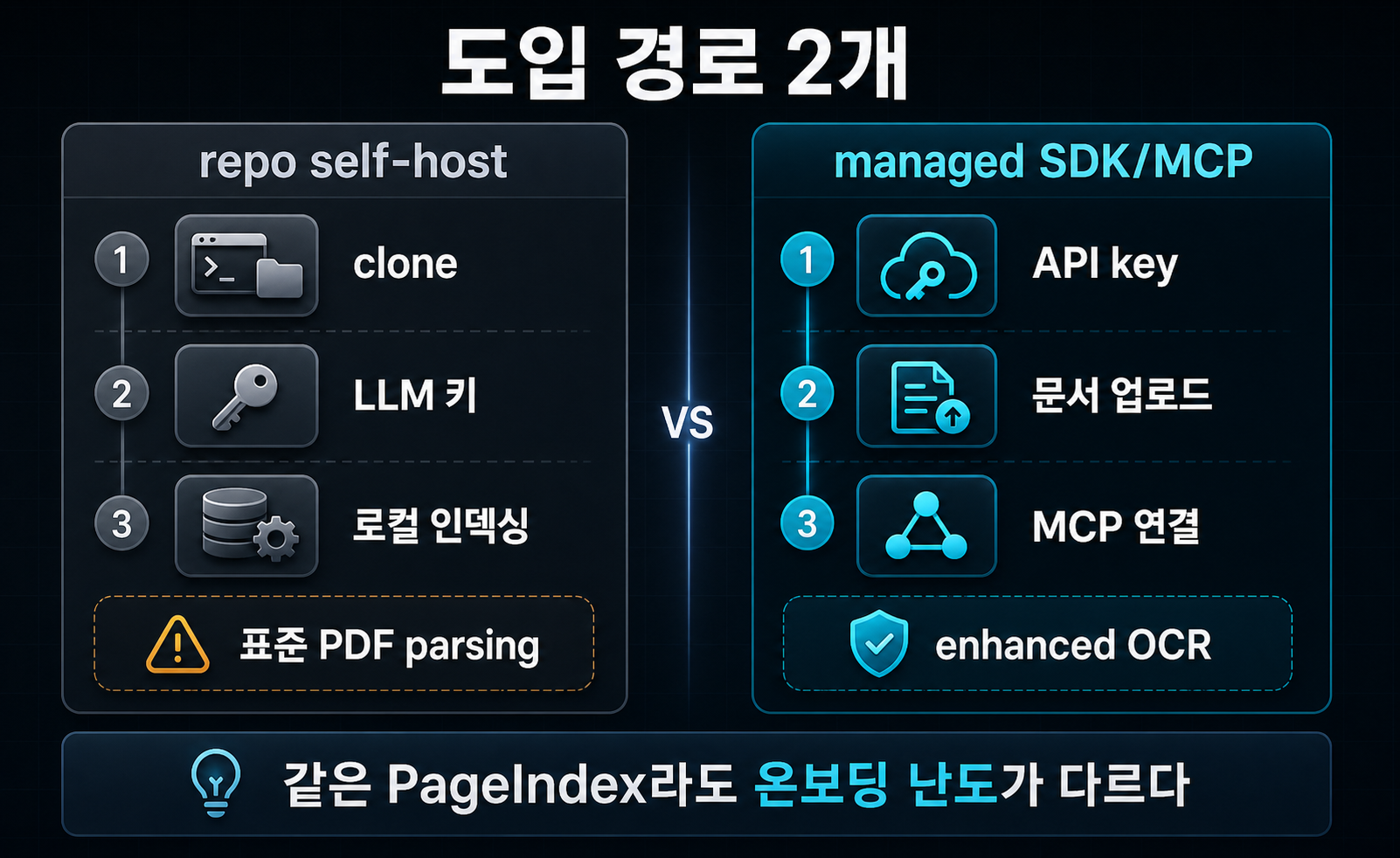
self-host와 cloud/API는 무엇이 다른가?
실무적으로 가장 중요한 섹션이다. PageIndex를 제대로 평가하려면 “오픈소스 레포”와 “관리형 문서 처리 서비스”를 아예 다른 온보딩 경로로 봐야 한다.
오픈소스 repo는 로컬 트리 생성기 성격이 강하다
README가 안내하는 self-host 경로는 매우 단순하다. 의존성을 깔고, .env에 LLM 키를 넣고, run_pageindex.py로 PDF나 Markdown을 트리 구조로 변환한다. requirements.txt를 보면 litellm, pymupdf, PyPDF2, python-dotenv, pyyaml 정도가 잡혀 있고, client.py는 OPENAI_API_KEY 또는 CHATGPT_API_KEY를 읽어 온다. 즉 “벡터 DB가 없다”는 말은 맞지만, LLM inference 자체가 사라지는 것은 아니다 (출처: PageIndex README, requirements.txt, client.py).
pip3 install --upgrade -r requirements.txt
python3 run_pageindex.py --pdf_path /path/to/your/document.pdf또 README는 이 오픈소스 경로가 “standard PDF parsing”을 쓴다고 명시한다. 복잡한 PDF는 cloud 쪽 enhanced OCR이 더 낫다고 스스로 적어둔 이유다 (출처: PageIndex README).
cloud/API는 문서 업로드 후 MCP나 Chat API로 붙는다
반대로 공식 docs의 Getting Started는 레포 clone이 아니라 Developer Dashboard에서 API 키를 만들고, pip install -U pageindex로 SDK를 설치한 뒤 문서를 업로드하는 흐름을 보여준다. 여기서 retrieval은 PageIndex cloud가 처리하고, 사용자는 자기 LLM/agent를 MCP로 붙이거나 PageIndex Chat API를 그대로 쓸 수 있다 (출처: Getting Started, MCP docs).
pip install -U pageindex{
"mcpServers": {
"pageindex": {
"type": "http",
"url": "https://api.pageindex.ai/mcp",
"headers": {
"Authorization": "Bearer your_api_key"
}
}
}
}실제 도입 판단은 두 경로를 분리해서 해야 한다
이 차이를 표로 보면 더 분명하다.
| 항목 | 오픈소스 repo | Cloud / SDK / MCP |
|---|---|---|
| 주 진입점 | GitHub clone + 로컬 실행 | Dashboard + API key + SDK |
| 문서 처리 | 표준 PDF parsing | 향상된 OCR + 관리형 처리 |
| 질의 연결 | 로컬 코드에서 직접 | MCP 또는 Chat API |
| 비용 구조 | 내 LLM 비용 중심 | 크레딧 + 경우에 따라 내 LLM 비용 |
| 현재 체감 | 구조 실험에 적합 | 실무 온보딩에 더 자연스러움 |
가격은 얼마나 들까?
가격은 공식 docs에 공개돼 있다. 이건 생각보다 중요한 포인트다. PageIndex는 “벡터 DB가 없으니 저렴하다”로 끝나는 구조가 아니다. 구독제와 크레딧 모델, 그리고 경우에 따라 별도 LLM 비용이 동시에 들어간다 (출처: Pricing docs).
월 구독과 크레딧이 함께 간다
2026년 3월 30일자 가격 문서 기준 무료 체험은 200 credits와 200 active pages를 준다. 유료는 Standard가 월 30달러, Pro가 월 50달러, Max가 월 100달러다. 포함 크레딧은 각각 1,000 / 2,000 / 6,000이고, active pages 한도는 10,000 / 50,000 / 500,000이다 (출처: Pricing docs).
| 플랜 | 월 가격 | 월 크레딧 | active pages | 메모 |
|---|---|---|---|---|
| Free Trial | $0 | 200 | 200 | 기본 MCP/API 체험 |
| Standard | $30 | 1,000 | 10,000 | 문서 AI 도입 시작점 |
| Pro | $50 | 2,000 | 50,000 | 팀 단위 처리량 확대 |
| Max | $100 | 6,000 | 500,000 | 대규모 처리 + 다중 워크스페이스 |
MCP는 내 LLM 비용과 PageIndex 비용이 분리된다
공식 가격표에서 특히 봐야 할 문구는 두 개다. 하나는 Page Indexing이 1 page당 1 credit이라는 점이고, 다른 하나는 LLM Integration은 unlimited이지만 inference billing은 네 LLM provider가 맡는다는 점이다. 다시 말해 MCP 모드에서는 PageIndex 비용과 OpenAI/Anthropic/Google 같은 모델 비용이 분리된다 (출처: Pricing docs, MCP docs).
이 구조는 장점과 단점을 동시에 만든다. 장점은 기존 에이전트 스택에 붙이기 쉽다는 점이다. 단점은 “월 30달러면 다 끝”이 아니라는 점이다. 문서 인덱싱과 모델 호출을 둘 다 계산해야 한다.
공짜처럼 보이지만 페이지 수가 곧 비용이다
top-up도 있다. 추가 크레딧은 개당 0.01달러고 만료되지 않는다. 즉, PDF가 길고 많이 들어오는 팀일수록 “질문 수”보다 “페이지 수”가 먼저 예산 변수로 올라올 가능성이 크다 (출처: Pricing docs).
98.7% FinanceBench는 어디까지 믿어야 하나?
PageIndex를 검색하면 거의 반드시 98.7%가 보인다. 문제는 이 숫자를 “거짓이냐 진실이냐”로만 보면 놓치는 게 많다는 점이다. 숫자 자체보다 어디서 나왔고, 어디까지 일반화할 수 있느냐가 더 중요하다.
숫자 자체는 실재하지만 출처는 벤더 소유다
Mafin 2.5 FinanceBench 레포와 공식 developer 페이지는 PageIndex 기반 시스템이 FinanceBench에서 98.7% 정확도를 냈다고 명시한다. 이는 실제 공개 자료에 있는 수치다. 다만 이 평가는 VectifyAI가 소유한 벤치마크 리포지토리와 마케팅 표면에서 가장 강하게 제시된다 (출처: Mafin2.5-FinanceBench, PageIndex Developer).
독립 자료도 tree reasoning 쪽 우세를 일부 지지한다
그렇다고 이 수치를 전부 무시할 필요도 없다. Adaptive Query Routing 논문은 FinanceBench와 금융/법률/의료 질의군에서 tree reasoning이 vector RAG보다 강한 면이 있다고 보고한다. 특히 cross-reference recall 같은 항목에서 tree 기반 접근의 강점이 드러난다 (출처: Adaptive Query Routing).
또 Thoughtworks Radar는 PageIndex를 “worth exploring” 정도로 평가하면서, 구조 의존성이 큰 문서에서는 실제로 이 접근이 잘 먹힌다고 적었다 (출처: Thoughtworks Radar).
그러나 multi-document 일반화는 아직 과감하다
여기서 바로 제동을 걸어야 한다. Mafin 레포 자신도 현재 벤치마크의 한계로 정답의 모호성과 multi-document reasoning 부재를 적고 있다. 즉 98.7%는 “모든 문서 검색 문제에서 PageIndex가 압도적이다”가 아니라, FinanceBench류 단일 문서 중심 평가에서 매우 강하다는 뜻으로 읽는 편이 맞다 (출처: Mafin2.5-FinanceBench, FinanceBench paper).
| 헤드라인 | 실제로 뜻하는 것 | 독자가 붙여야 할 단서 |
|---|---|---|
| 98.7% FinanceBench | 금융 문서 QA에서 강한 결과가 공개돼 있음 | 벤더 소유 평가와 자료라는 점 같이 볼 것 |
| vectorless RAG | 벡터 DB 없이 트리 인덱스와 reasoning으로 검색 | LLM 비용과 latency가 사라지는 건 아님 |
| million-document scale | 파일 시스템 레이어를 얹은 enterprise/cloud 확장 주장 | 오픈소스 repo 단독 근거로 일반화하면 과감함 |
PageIndex를 소개하는 글이 자주 놓치는 지점은 이 숫자를 제품 전체의 일반 우위로 번역하는 순간이다. FinanceBench 강세와 일반 RAG 대체 가능성은 같은 문장이 아니다.
vector RAG·GraphRAG·LLM 위키와 무엇이 다른가?
PageIndex를 제대로 이해하려면 “벡터 DB를 버리는 다른 대안”들과도 분리해서 봐야 한다. 세부 구현보다 중요한 건 지식을 어떤 단위로 저장하고, 질의 때 무엇을 탐색하느냐다.
vector RAG와의 차이는 retrieval unit이다
vector RAG는 보통 chunk를 retrieval unit으로 쓴다. PageIndex는 섹션과 페이지가 묶인 트리를 쓴다. 그래서 PageIndex는 긴 구조화 문서의 흐름을 보존하는 대신, retrieval에 LLM reasoning을 집어넣는 비용을 감수한다 (출처: PageIndex introduction, Thoughtworks Radar).
Graphify나 LLM 위키는 목표가 다르다
Claude Code 토큰 71배 줄이는 법 — Graphify 실전 구축 2026는 코드와 문서를 그래프 topology로 묶어 Claude가 그래프를 읽게 만드는 접근이다. RAG는 끝났다? Karpathy가 제안한 LLM 위키의 정체 (2026 총정리)는 문서를 markdown 위키로 누적 컴파일하는 철학에 가깝다. 둘 다 “벡터 DB 바깥의 구조”를 쓴다는 점은 비슷하지만, PageIndex는 문서 검색, Graphify는 지식 그래프 기반 코드/문서 탐색, LLM 위키는 누적형 지식 컴파일에 더 가깝다.
현실적인 답은 대체보다 하이브리드다
AI 앱은 프롬프트가 아니라 하네스로 완성된다에서 다뤘듯, 실제 시스템은 보통 한 retrieval만으로 끝나지 않는다. 광범위 후보 문서를 먼저 vector나 metadata search로 줄이고, 마지막 정밀 추출을 PageIndex 같은 reasoning retriever에 맡기는 식이 가장 현실적이다. Adaptive Query Routing 논문도 완전 대체보다 hybrid가 일부 질의군에서 더 낫다고 보여준다 (출처: Adaptive Query Routing).
| 구분 | vector RAG | PageIndex | Graphify / LLM 위키 |
|---|---|---|---|
| 탐색 단위 | chunk | 섹션·페이지 트리 | 그래프 노드 또는 위키 문서 |
| 강한 문제 | 대규모 후보 축소 | 긴 구조화 문서 deep retrieval | 누적 지식 구조화 |
| 약한 문제 | cross-reference와 의미 왜곡 | latency·비용·광범위 코퍼스 | 문서 QA 일반화 |
| 실전 역할 | 1차 후보 검색 | 2차 정밀 추출 | 장기 메모리 / 코드 이해 보조 |
MCP로 붙이면 어떤 워크플로가 되나?
PageIndex가 지금 시점에 흥미로운 이유는 단순한 PDF QA가 아니라, 에이전트 도구로 붙을 때의 표면이 꽤 잘 정리돼 있기 때문이다.
PageIndex MCP는 end-user chat과 분리된 개발자용이다
공식 MCP 문서는 PageIndex MCP가 end-user용 Chat과 usage/file space를 공유하지 않는 developer integration surface라고 못 박는다. 인증은 Bearer API 키를 쓰고, HTTP MCP 서버 URL은 https://api.pageindex.ai/mcp다 (출처: MCP docs).
이건 실무적으로 중요하다. “채팅창에서 잘 되더라”와 “내 에이전트 파이프라인에 안정적으로 붙는다”는 전혀 다른 문제이기 때문이다.
OpenAI Agents SDK 예제가 주는 힌트
레포의 agentic_vectorless_rag_demo.py는 OpenAI Agents SDK를 사용해 get_document, get_document_structure, get_page_content 세 도구를 등록하고, 에이전트가 구조를 먼저 읽은 뒤 필요한 페이지 범위만 가져오게 만든다. 여기서 포인트는 PageIndex가 “답을 대신 쓰는 모델”이 아니라, 에이전트가 더 정확히 읽게 만드는 retrieval tool이라는 점이다 (출처: agentic_vectorless_rag_demo.py).
하네스 관점에서 봐야 과장이 줄어든다
이 지점은 AI 앱은 프롬프트가 아니라 하네스로 완성된다와 그대로 닿는다. PageIndex는 새로운 foundation model이라기보다, retrieval layer를 교체하는 하네스 부품에 가깝다. 그래서 “PageIndex가 똑똑하냐?”보다 “지금 내 agent loop에서 어떤 retrieval 실패를 줄여주냐?”로 묻는 편이 맞다.
설치는 정말 쉬운가?
이 질문에는 “경로에 따라 다르다”라고 답하는 수밖에 없다.
관리형 SDK 설치는 현재 매끄럽다
공식 Getting Started가 안내하는 pip install -U pageindex 경로는 2026년 5월 7일 clean Python 3.11 가상환경에서 직접 설치가 정상 완료됐다. 즉 관리형 SDK로 문서를 업로드하고 API/MCP를 붙이는 시작점은 현재 기준 꽤 매끄러운 편이다 (출처: Getting Started).
그러나 repo clone self-host는 바로 부딪히는 마찰이 있다
반면 같은 날짜에 레포를 clone해서 pip install -r requirements.txt를 실행해 보니 clean Python 3.11 환경에서 바로 dependency conflict가 났다. litellm==1.83.7가 python-dotenv==1.0.1을 요구하는데, 레포는 python-dotenv==1.2.2를 핀하고 있기 때문이다. 즉 README 경로는 지금 시점에 “설명은 간단하지만, clean install은 바로 통과하지 않는 상태”라고 보는 편이 정확했다 (출처: requirements.txt).
따라서 ‘간단하다’는 말은 경로를 명시해야 한다
이 차이는 단순한 사소함이 아니다. 팀이 “오픈소스만으로 self-host하려는가”, 아니면 “관리형 문서 처리 + MCP를 쓰려는가”에 따라 진입 난도와 리스크가 크게 달라진다.
requirements.txt핀 충돌이 해결됐는지\n2. 어떤 LLM provider 키를 쓸지\n3. 복잡한 PDF에서 표준 parsing으로 충분한지\n4. cloud enhanced OCR이 꼭 필요한 도메인인지
어떤 문서에 잘 맞고 어떤 경우엔 안 맞나?
PageIndex를 가장 정확히 쓰는 방법은 “어디서 잘 맞는지”를 먼저 좁히는 것이다.
잘 맞는 경우: 긴 구조화 문서와 cross-reference 질문
재무 보고서, 규정 문서, 법률 문서, 기술 매뉴얼처럼 섹션 구조와 참조 흐름이 중요한 문서에서는 PageIndex가 꽤 설득력 있다. Thoughtworks도 그런 부류에서 잘 작동한다고 적었고, FinanceBench류 평가 역시 이런 성격의 문서를 전제로 한다 (출처: Thoughtworks Radar, FinanceBench paper).
덜 맞는 경우: 짧은 FAQ, 초저지연, 광범위 다문서 탐색
반대로 짧은 문서나 범용 semantic search, 응답 지연이 매우 민감한 실시간 UX, 수백만 문서를 한 번에 넓게 훑는 문제에서는 vector RAG나 hybrid가 더 현실적일 수 있다. 공식 블로그조차 million-document scale 이야기를 할 때는 별도 PageIndex File System 레이어를 강조한다. 기본 오픈소스 repo만으로 그 스케일까지 일반화하면 과감하다 (출처: PageIndex File System blog, Adaptive Query Routing).
독립 평가에서도 비슷한 제동이 걸린다. Nathan A. King은 상업용 대출 문서 코퍼스에서 전통 RAG가 정답률 47%, PageIndex가 22%, 평균 지연은 4.7초 대 27.2초였다고 보고했다. 이 결과 하나로 일반화할 수는 없지만, “구조가 덜 선명한 문서 + 빠른 응답이 필요한 상황”에서는 PageIndex가 오히려 불리할 수 있음을 보여주는 사례로는 충분하다 (출처: PageIndex as RAG Alternative).
million-document 이야기는 enterprise layer 문맥으로 읽어야 한다
이게 핵심이다. “single long document deep retrieval”과 “massive corpus search”는 다른 문제다. PageIndex가 후자에도 도전하고 있는 것은 맞지만, 현재 공개 근거의 중심축은 아직 전자에 더 가깝다.

FAQ: PageIndex에 대해 자주 묻는 질문
PageIndex는 벡터 DB를 완전히 대체하나요?
PageIndex는 오픈소스만으로 바로 쓸 수 있나요?
관리형 서비스와 GitHub repo 중 무엇부터 보는 게 좋나요?
98.7% FinanceBench는 믿을 만한가요?
어떤 모델과 함께 쓰는 게 좋나요?
PageIndex는 어떤 사람에게 가장 먼저 추천할 만한가요?
결론: 지금 PageIndex를 써볼 만한가?
지금 시점의 추천은 명확하다. 긴 구조화 문서에서 vector RAG의 정확도가 자주 흔들린다면, PageIndex는 충분히 실험할 가치가 있다. 다만 그 실험은 “기존 RAG를 다 버릴까?”가 아니라 “어느 구간을 tree reasoning으로 바꾸면 이득이 생기나?”라는 질문으로 시작해야 한다.
한 줄 판단
PageIndex는 문서 구조가 곧 의미인 문제에서 강한 후보지만, 현재 공개 근거만으로 “범용 RAG 대체”라고 부르기엔 아직 이르다.
managed SDK / MCP 경로와 open-source self-host repo 경로를 절대 한 문장으로 묶지 말 것. 전자는 빠른 검증용, 후자는 구조 실험용에 가깝다.
1. 한 문서로 먼저 비교하라
재무 보고서나 규정집처럼 구조가 복잡한 PDF 하나를 골라 기존 vector RAG와 PageIndex를 같은 질문 세트로 비교한다.
2. managed 경로부터 검증하라
빠른 온보딩이 필요하면 SDK와 MCP부터 보고, 이후에 self-host 필요성이 분명해질 때 GitHub repo를 다시 검토한다.
3. hybrid를 기본값으로 생각하라
광범위 후보 검색은 기존 검색 계층에 맡기고, 마지막 정밀 추출만 reasoning retriever에 맡기는 구성이 현재로선 가장 현실적이다.
주제 태그

PlayMCP란? 카카오 MCP 플랫폼과 OpenClaw 연동 총정리
PlayMCP가 무엇인지, 카카오의 도구함과 OpenClaw 연동이 왜 중요한지, 공개된 연결 방식과 보안 포인트까지 최신 기준으로 정리한다.
읽기
RAG는 끝났다? Karpathy가 제안한 LLM 위키의 정체 (2026 총정리)
RAG 한계에 부딪혔다면? Karpathy가 공개한 LLM 위키 패턴을 뜯어봤다. 3계층 아키텍처, 95% 토큰 절감, 2주 만에 폭발한 생태계까지 2026년 개념편 총정리.
읽기
Kronos란? 금융 시계열 AI 모델, Chronos·TimesFM과 비교
Kronos가 왜 금융 시계열 특화 AI 모델로 주목받는지, 논문 수치와 공식 문서 기준으로 Chronos·TimesFM·TimeGPT와 비교해 정리한다.
읽기